




备用主机一定要留几台,如果这次我们没有备用机,后果不堪设想。
做好备份,做好监控,老生常谈了。
中小公司能上云就上云吧,有一说一,大公司的云数据库产品不香吗?
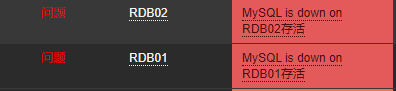
出现问题,要冷静,按部就班特别涉及数据恢复的问题(反正已经宕机了三个多小时了,还在乎那么十几分钟的binlog数据恢复吗),应变能力和决策能力也很重要。
一定要做好沟通和通告。
好好学习,增强实力,让问题扼杀在摇篮中。
PS:截止到现在第三方还没有具体的故障答复。。。从数据库的日志看貌似存储有问题,但系统日志没有异常,还是把时间交给第三方吧。
文章转载自爱可可的人生记录仪,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
2393次阅读
2025-04-09 15:33:27
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1107次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
794次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
612次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
552次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
536次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
521次阅读
2025-04-14 09:40:20
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
484次阅读
2025-04-07 09:44:54
一页概览:Oracle GoldenGate
甲骨文云技术
440次阅读
2025-04-30 12:17:56
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
438次阅读
2025-04-17 17:02:24
