




8月5日 ,云和恩墨高级技术顾问范计杰老师,在墨天轮上分享了《经典知识库:Oracle DBA的SQL编写技能提升宝典》的直播。老师围绕实际运维场景下的案例,向大家介绍了提升SQL编写技能的干货和小技巧。
当晚,朋友们对这场直播的反响十分热烈,考虑到有些朋友没有来得及参与,这里小编为大家整理了文字版干货重点、PPT资源以及直播回放,有需要的朋友们可以收藏、查看。(文末还有部分SQL的资源下载包。)
目录导读
直播干货
一、运维场景SQL实例
案例一:创建表空间
背景:要迁移数据库,需要创建与源库相同的表空间,大小与源库相同。由于个别表空间较大,手工添加可能需要写很多的脚本,于是同事通过PL/SQL解决了问题。
但实际上通过一条SQL就可以搞定,步骤👇
创建表空间——添加数据文件,直到与源库大小相同
-
查询源表空间的大小;
-
生成文件列表<最大文件数为1024>;
-
进行关联
SQL如下:
col sqltext for a999
with t as
(select tablespace_name tsname, round(sum(bytes) / 1024 / 1024 / 1024) gb
from dba_data_files
group by tablespace_name),
t2 as
(select rownum n from dual
connect by rownum < 1024)
select decode(b.n, 1,'create tablespace','alter tablespace')||
a.tsname || ' datafile''+DATADG''size 30G;'sqltxt
from t a, t2 b
where 30 * b.n < a.gb
order by a.tsname, b.n;
复制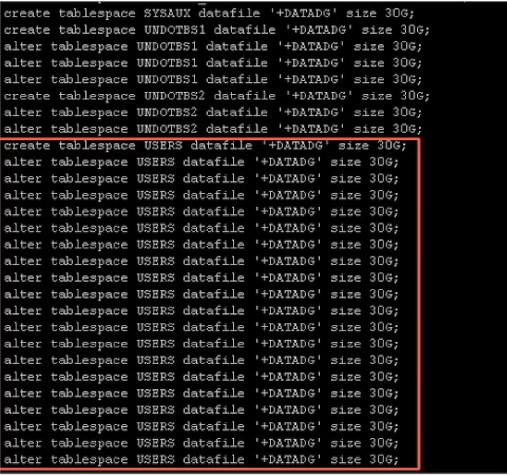
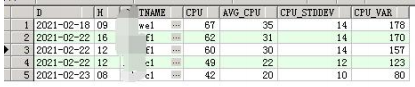
案例二:巡检-异常检测-周期数据
数据库主机CPU一般每天随着上下班时间进行规律性波动。在这种数据中,怎么找出CPU使用率异常的主机、时间点?
1、从一堆数据库中找出异常的数据库节点
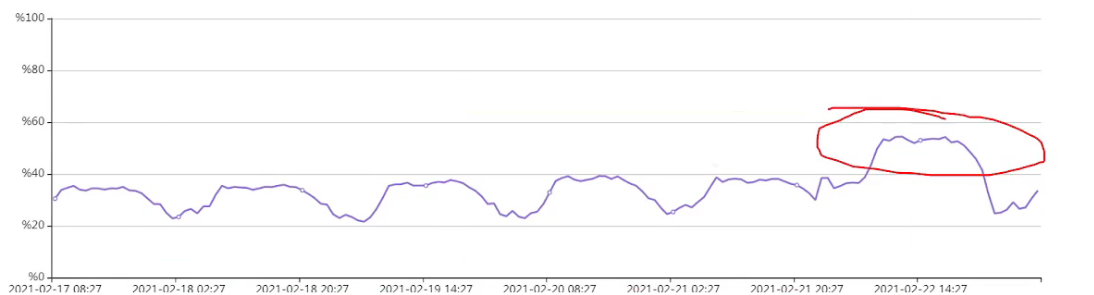
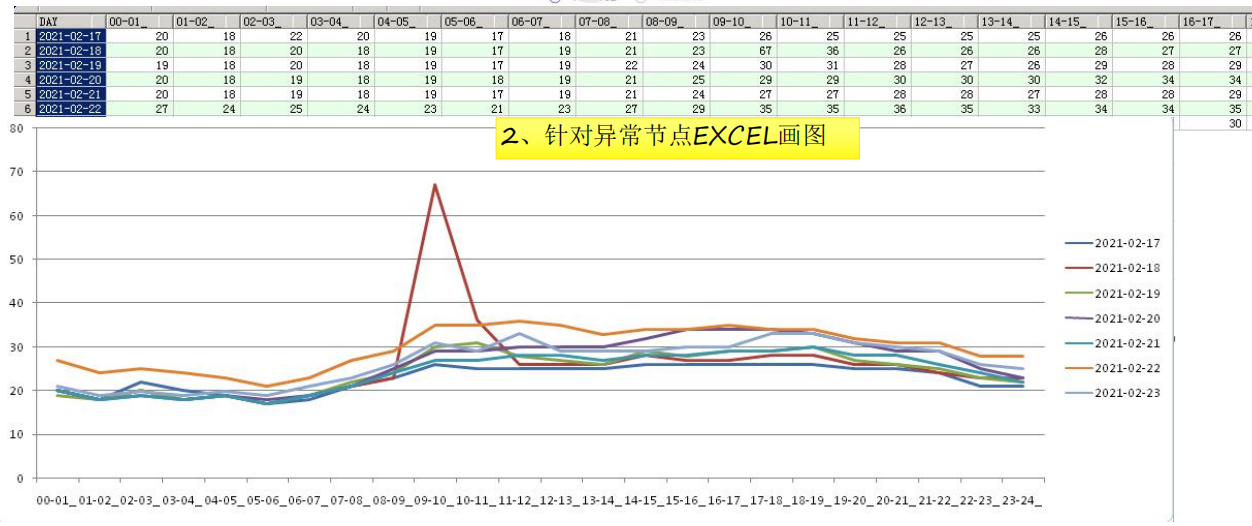
2、找出波动区域后,针对异常节点Excel画图,以观察其与正常负载的区别
3、异常主机查询-主要SQL介绍
a. 以天、小时为单位对数据分组
b. 用分析函数取平均值分析标准方差,以更加精准定位问题主机
with t as
(select to_char(exectime, 'yyyy-mm-dd') d,
to_char(exectime, 'hh24') h,
hostname,
round(avg(100 - id)) cpu
from sys_vmstat
where exectime between trunc(sysdate - 7, 'dd') and trunc(sysdate, 'dd')
and (hostname like 'yyyy%' or hostname like 'zzzz%')
group by to_char(exectime, 'yyyy-mm-dd'),
to_char(exectime, 'hh24'),
hostname),
t2 as
(select d,
h,
hostname,
cpu,
round(avg(cpu) over(partition by hostname, h)) avg_cpu,
round(STDDEV(cpu) over(partition by hostname, h)) cpu_stddev
from t)
select *
from t2
where cpu_stddev < 15
and cpu - avg_cpu > 20
order by cpu - avg_cpu desc;
复制c. 生成7天对比图,使用pivot函数将每天每小时的sql使用率作图
with t as (select to_char(exectime,'yyyy-mm-dd')day,to_char(exectime,'hh24') hour,hostname,round(avg(100-id)) cpu from gm.sys_vmstat
where exectime between trunc(sysdate-7,'dd') and trunc(sysdate,'dd') and hostname='testb2'
group by to_char(exectime,'yyyy-mm-dd'),to_char(exectime,'hh24') ,hostname)
SELECT day,
"00-01_ ",
"01-02_ ",
"02-03_ ",
"03-04_ ",
"04-05_ ",
"05-06_ ",
"06-07_ ",
"07-08_ ",
"08-09_ ",
"09-10_ ",
"10-11_ ",
"11-12_ ",
"12-13_ ",
"13-14_ ",
"14-15_ ",
"15-16_ ",
"16-17_ ",
"17-18_ ",
"18-19_ ",
"19-20_ ",
"20-21_ ",
"21-22_ ",
"22-23_ ",
"23-24_ "
From t pivot(sum(CPU) as " " for hour in('00' AS "00-01",
'01' AS "01-02",
'02' AS "02-03",
'03' AS "03-04",
'04' AS "04-05",
'05' AS "05-06",
'06' AS "06-07",
'07' AS "07-08",
'08' AS "08-09",
'09' AS "09-10",
'10' AS "10-11",
'11' AS "11-12",
'12' AS "12-13",
'13' AS "13-14",
'14' AS "14-15",
'15' AS "15-16",
'16' AS "16-17",
'17' AS "17-18",
'18' AS "18-19",
'19' AS "19-20",
'20' AS "20-21",
'21' AS "21-22",
'22' AS "22-23",
'23' AS "23-24"))
复制
案例三:巡检-异常检测-异常波动
平时维护数据库较多时,若想通过人工找出某一数据库在何时间发生过较大的负载波动,会比较麻烦,通过以下 SQL筛查的方式会相对高效。
具体查询SQL可从后文“SQL资源下载”中的资源包下载。
1、通过函数将前后几分钟的负载变化选出
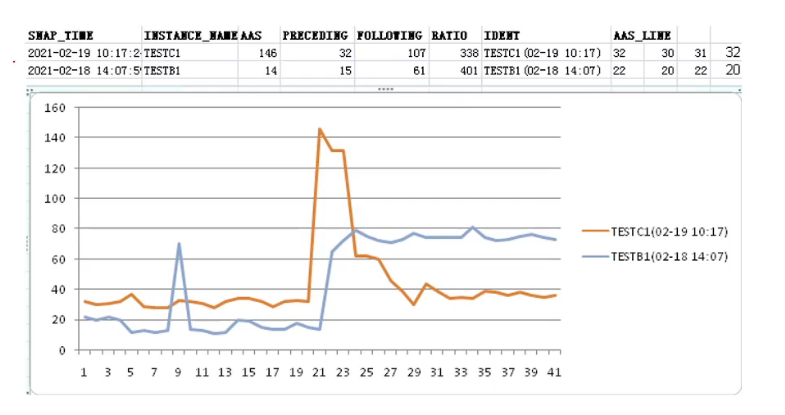
2、通过发生问题的时间点、实例采用LISTAGG生成负载变化图,通过excel生成直观曲线图

最后制作成的excle表格如下
案例四:巡检-表空间分析
通过分析表空间的变化,可以了解表空间有无异常增长或变化明显的情况,以合理规划表空间。
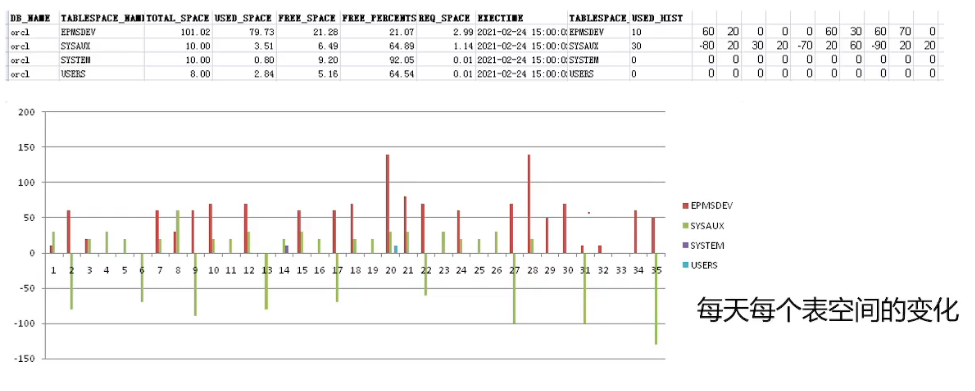
1、存储空间规划
❓如以下表空间每天增长、清理,有少量净增长,表空间预留多大才能使用90天?
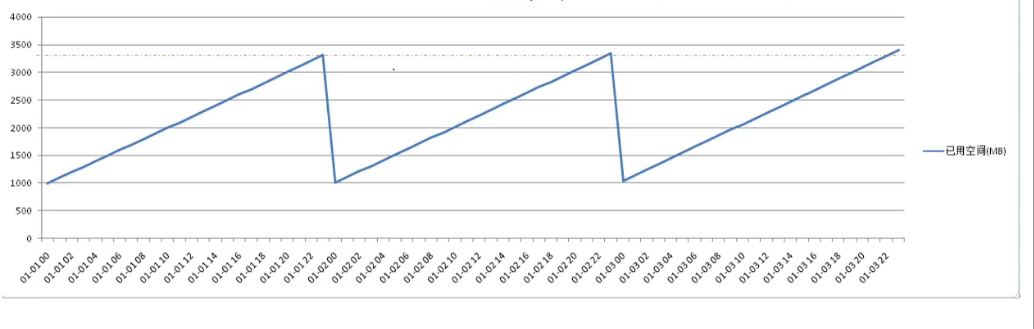
计算公式:每天净增长*预留天数+每天最大使用量+最小保留

净增长的计算方式
2、等待链
在分析性能问题或堵塞时需要对等待链进行分析。
set lines 1000
col wait_chain format a160
with t as
(select * from gv$session),
t2 as
(select level lv,
sid,
serial#,
program,
event,
connect_by_iscycle iscycle,
connect_by_isleaf leaf,
LEVEL,
SYS_CONNECT_BY_PATH('['||program||']'||'('||
to_char(inst_id)||'-'||nvl(event,state)||')',
'->') wait_chain
from t
connect by NOCYCLE prior blocking_session= sid
and prior blocking_instance= inst_id
start with state='WAITING')
select wait_chain,count(*),max(iscycle)iscycle
from t2
where leaf=1
AND LV>1
group by wait_chain
order by count(*) desc;
复制不同的场景则需对SQL进行调整。
(1)使用gv%session函数

(2)使用ISCYCLE


右侧可看到堵塞者为SQL*Net message from client,为空闲等待事件,即活堵塞处为非活动状态,在执行SQL后未及时提交事务,导致堵塞。
3、ASH分析
进行ASH分析,分析等待事件的变化,可以使用event或sql_id执行。
(1)event
----by event
break on etime
with t as (select to_char(sample_time,'hh24:mi')etime,nvl(event,'ONCPU')event,round(count(*)/60,2) cnt,row_number()over(partition by to_char(sample_time,'hh24:mi')order by count(*) desc) rn from v$active_session_history
where sample_time>sysdate-30/1440
group by to_char(sample_time,'hh24:mi') ,nvl(event,'ONCPU'))
select * from t where rn<=10 order by etime,cnt desc;
复制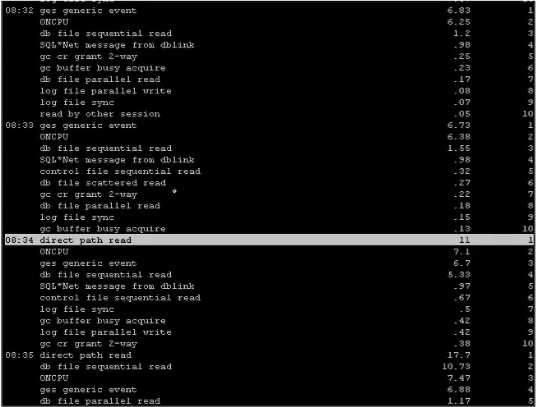
(2)sql_id
可以通过函数,看到百分比以及某一时间点的使用次数
---by sqlid
break on etime
with t as (select to_char(sample_time,'hh24:mi')etime,nvl(sql_id,TOP_LEVEL_CALL_NAME) sql_id,round(count(*)/60,2) cnt,round(ratio_to_report(count(*))over(partition by to_char(sample_time,'hh24:mi'))*100,2) pct, max(SQL_EXEC_ID)-min(SQL_EXEC_ID)+1 execs,row_number()over(partition by to_char(sample_time,'hh24:mi')order by count(*) desc) rn from v$active_session_history
where sample_time>sysdate-30/1440
group by to_char(sample_time,'hh24:mi') ,nvl(sql_id,TOP_LEVEL_CALL_NAME))
select * from t where rn<=10 order by etime,cnt desc;
复制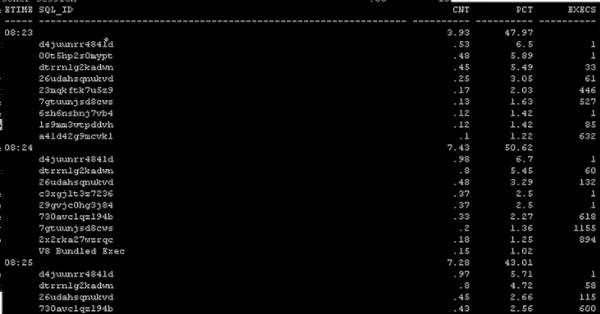
4、SQLPLUS 中的性能监控
可以使用 PL/SQL PIPE ROW 特性进行实时监控某些指标,函数中指标可配置,用逗号隔开即可
主要SQL如下:
(具体查询SQL可从后文“SQL资源下载”中的资源包下载。)
dbms_lock.sleep(interval_sec);
PIPE ROW ('------------------------------------');
for r in (select /*+use_hash(s) leading(l,s)*/s.name,s.value,sysdate etime from table(dbmt.split(stat_str))l, v$sysstat s where l.column_value=s.name)
loop
v_interval_sec:=(r.etime-v_date)*24*3600;
ret_str:=to_char(r.etime,'hh24:mi:ss')||' '||rpad(r.name||'/s ',30,'-')||' '|| round((r.value-stat1(r.name))/v_interval_sec,2);
PIPE ROW (ret_str);
stat1(r.name):=r.value;
v_date_new:=r.etime;
end loop;
/
复制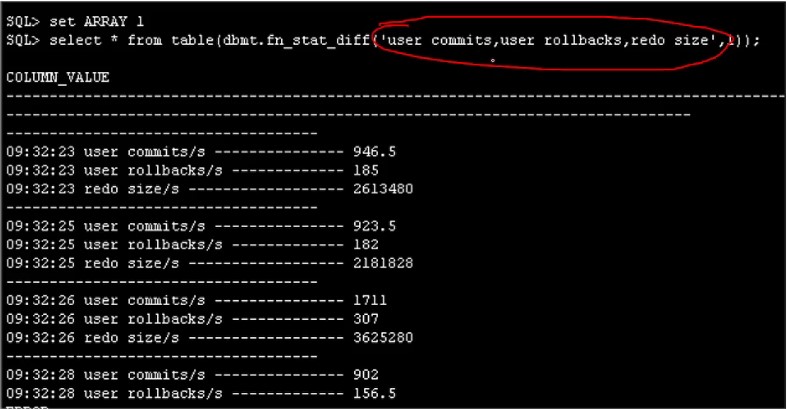
二、常用函数介绍、示例
1、分析函数
用来支持进行OLAP(联机分析处理),提供强大的分析功能
分析函数语法及释义:
FUNCTION\_NAME(<argument>,<argument>..…) OVER(<Partition-Clause><Order-by-Clause><Windowing Clause>)复制
(1)FUNCTION子句
ORACLE提供了很多分析函数,按功能分5类:等级(ranking)函数,开窗(windowing)函数,制表(reporting)函数,LAG/LEAD函数,线性的衰减函数。
(2)PARTITION子句
按照表达式分区(就是分组),如果省略了分区子句,则全部的结果集被看作是一个单一的组
可根据实际情况进行调整,是否需要依不同条件、值进行分组。
(3)ORDER BY子句
分析函数中ORDER BY的存在将添加一个默认的开窗子句,这意味着计算中所使用的行的集合是当前分区中当前行和前面所有行,没有ORDER BY时,默认的窗口是全部的分区。根据实际情况选择是否使用。
(4)WINDOWING子句
用于定义分析函数将在其上操作的行的集合
Windowing子句给出了一个定义变化或固定的数据窗口的方法,分析函数将对这些数据进行操作,默认的窗口是一个固定的窗口,仅仅在一组的第一行开始,一直继续到当前行,要使用窗口,必须使用ORDER BY子句,根据2个标准可以建立窗口:数据值的范围(RANGE)或与当前行的行偏移量(ROWS)。
示例:

- RANGE逻辑窗口
针对图中ID列的值作运算,RANGE_SUM列为逻辑窗口,意为当前行的值-1到当前行+2的窗口中所包含的值求和
- ROWS物理窗口
针对图中ID列的值作运算,ROWS_SUM列为物理窗口,意为当前行的前一行+当前行+后两行的值求和
2、常用分析函数
(1)汇总类
-
Sum
-
Avg
-
Count
-
Max/min
-
Ratio_to_report
在通过ASH分析性能时,在进行分组后会计算活动会话的百分比,即可用此函数
with t as
(select to_char(sample_time,' hh24: mi') etime,
nv1(sql_id, TOP_LEVEL_CALL NAME) sql_id,
round(count(*)/60,2) cnt,
round(ratio_to report(count(*)).
over(partition by to_char(sample_time, 'hh24:mi'))*100,
2) pct,
max(SQL_EXEC_ID)-min(SQL_EXEC_ID)+1 execs,
row_number() over(partition by to char(sample_time,' hh24: mi') order by count(*) desc) rn
from vSactive_session history
where sample_time>sysdate-30/1440
group by to_char(sample_time,' hh24: mi'),
nvl(sql id, TOP LEVELCALLNAME))
select * from t where rn<=10 order by ctime, cnt desc;
复制
- LISTAGG(多个值平均到一起)
将一个分组中的多个值合成一行
示例:

使用listagg函数后,结果如下:

注意:超长溢出处理方式(最长4000字节)
a. ON OVERFLOW ERROR
b. ON OVERFLOW TRUNCATE
(2)排行类
-
Row_number
-
Rank
取每个用户下最多的两类对象
select*
from(select owner,
object_type,
cnt,
rank()over(partition by owner order by cnt desc)rank
from(select owner,object_type,count(*)cnt
from dbmt.db_objects
group by owner,object_type)t)
where rank<5
复制
- Dense_rank
注意:
a. Row number分配一个唯一的行编号
b. Rank排名可能不是连续的数字
c. Dense_rank排名是连续的数字
(3)其他
- LAG , LEAD
取当前行的前一/几行(LAG)或后一/几行(LEAD)中指定值
SQL与示例:
with t as
(select rownum r from dual connect by level<10)
select r,
1ag(r)over(order by r)lagr,
lead(r)over(order by r)lead_r
from t;
复制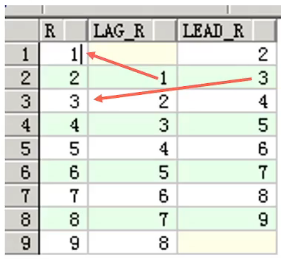
常用:分析AWR数据,用当前的值-上一行值即可计算增量,示例SQL如下
select st. instance_number,
st. snap_id,
to_char(SN. BEGIN_INTERVAL_TIME,' yyyy-mm-dd hh24: mi") BEGIN_INTERVAL_TIME,
(value-(lag(value)
over(partition by st. instance_number order by st. snap_id))) value
from dba_hist_sysstat st, DBA_HIST_SNAPSHOT sn
where st. INSTANCE_NUMBER=SN. INSTANCE_NUMBER
and st. SNAP_ID=SN. SNAP_ID
and sn. begin_interval_time> to_date("2021-03-01', yyyy-mm-dd")
and sn. instance_number=1
and stat_name=' gc cr blocks received'
order by st. instance_number, st. snap_id;
复制
- GREATEST , LEAST(取最大值、最小值)
常用于分析SQL历史性能

select ss.plan hash value phv,
to_char(s.begin_interval_time,'mm-dd HH24:MI")snap_time,
ss.instance_number,
ss.executions delta execs,
round(ss.rows processed delta/greatest(ss.executions delta,1),2)rows per exec,
round(ss.buffer gets delta/greatest(ss.executions delta,1))lio_per_exec,
round(ss.disk_reads delta/greatest(ss.executions delta,1))pio_per_exec,
round((ss.cpu time delta/1e3)/greatest(ss.executions delta,1),2)cpu_per_exec,
round((ss.elapsed_time_delta/1e3)/greatest(ss.executions_delta,1),2)ela_per_exec
from dba_hist_snapshot s,
dba hist_sqlstat ss
where ss.dbid=s.dbid
and ss.instance_number=s.instance_number
and ss.snap_id=s.snap_idand ss.sql_id='&v_sqlid'
and ss.executions_delta>0
and s.begin_interval_time>=sysdate-&v_days
order by ss.plan_hash_value,s.snap_id;
复制示例:找出7列相同或不同的记录
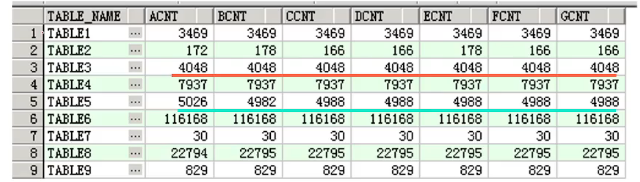
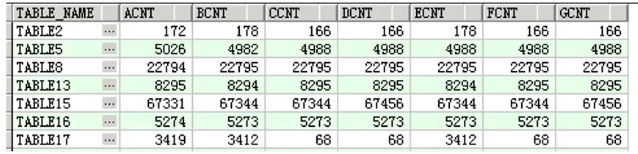
SQL如下:
SELECT * FROM dbmt. ogg tables count2 WHERE GREATEST(ACNT, BCNT, CCNT, DCNT, ECNT, FCNT, GCNT)<>LEAST(ACNT, BCNT, CCNT, DCNT, ECNT, FCNT, GCNT)
复制
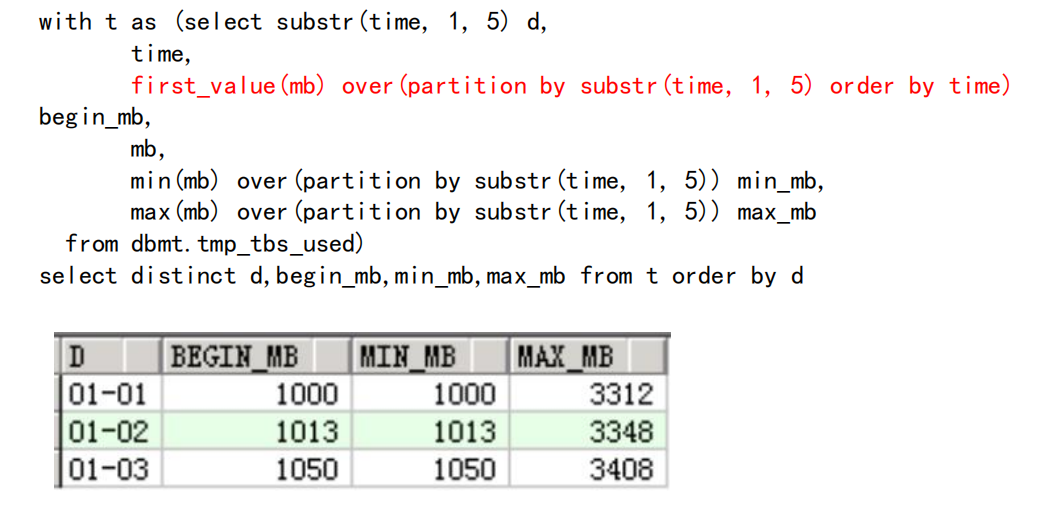
- FIRST_VALUE , LAST_VALUE
取分组中的第一个(FIRST_VALUE)、最后一个值(LAST_VALUE)
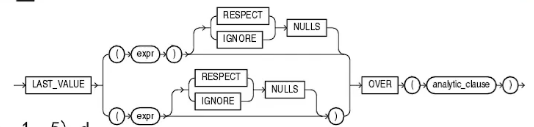
with t as(select substr(time,1,5)d,
time
first_value(mb) gver(partition by substr(time,1,5) order by time)
begin_mb,
mb,
min(mb) over(partition by substr(time,1,5)) min_mb,
max(mb) over(partition by substr(time,1,5)) max_mb
from dbmt. tmp tbs used)
select distinct d, begin mb, min_mb, max_mb from t order by d
复制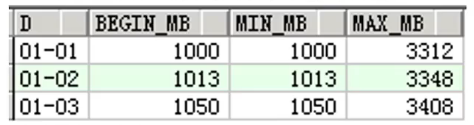
-
NVL ,NVL2
-
NVL(EXP,返回值1)当EXP值为null时返回值1,不为null时返回本身
-
NVL2(EXP,返回值1,返回值2)当exp的值为null时返回值1,不为null时返回值2
-
nvl(NULL,'N')==N nvl'A','')==A nv12(NULL,'A','B')==B nv12('c','A','B')==A复制
- LNNVL
LNNVL当条件的一个或两个操作数可能为空时,LNNVL提供了一种简明的方法来计算条件。它接受一个条件作为参数,如果条件为假或未知则返回TRUE,如果条件为真则返回FALSE。LNNVL可以在任何标量表达式可能出现的地方使用。
end_date is null or end_date>sysdate
可改为
Innvl(end_date<=sysdate);
- DECODE(IF ELSE 分支判断)
DECODE(EXP,条件1,返回值1,条件2,返回值2,…,默认值)

一般用于行转列。示例:
select owner,
sum(decode(object type,' TABLE',1,0)) table cnt,
sum(decode(ob. ject type,' INDEX',1,0)) index cnt
from dbmt. db objects where object type in (' TABLE',' INDEX')
group by owner
复制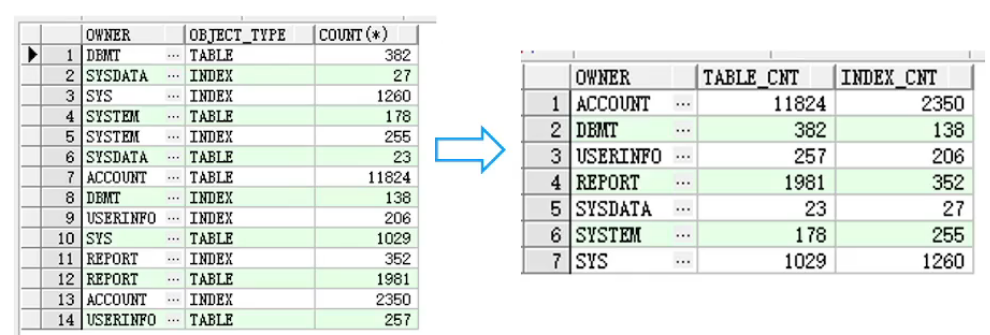
- LPAD , RPAD
LPAD(COLUMN,参数1,参数2)
LPAD指在column列的左边填充指定长度的指定字符串,RPAD指在右边填充。一般用于格式化数据。

示例:
SQL> select
rownum,LPAD(to_char(rownum),10,'0'),RPAD(to_char(rownum),10,'0') from dual
connect by rownum<4;
ROWNUM LPAD(TO_CHAR(ROWNUM) RPAD(TO_CHAR(ROWNUM)
---------- -------------------- --------------------
1 0000000001 1000000000
2 0000000002 2000000000
3 0000000003 3000000000
复制
- LTRIM , RTRIM
去掉一个字符串中左边(LTRIM)或右边(RTRIM)的字符
LTRIM(char [,set ])
RTRIM(char [,set ])
char参数为字符串,set为需要去掉的字符,若不指定具体字符默认为去掉空字符。
- 一些正则表达式:REGEXP_LIKE、REPLACE、SUBSTR
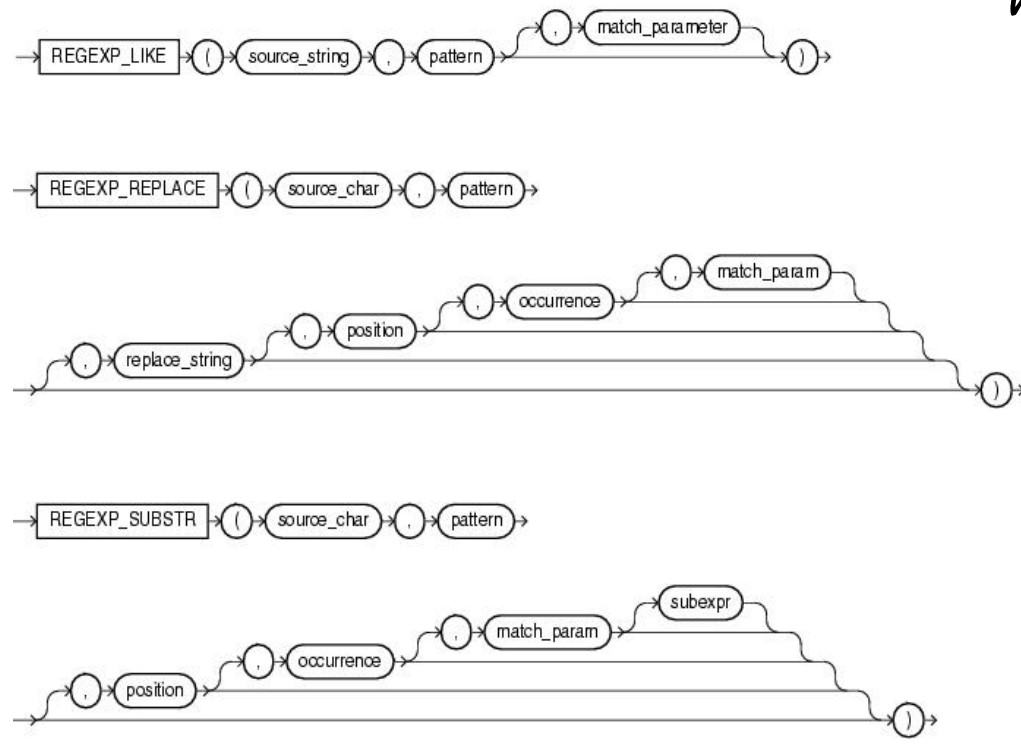
可以指定参数
-
match_param
-
i 指定不区分大小写的匹配。
-
c 指定区分大小写的匹配。
-
n 允许句点.匹配换行符,省略则与换行符不匹配。
-
'm’ 将源字符串视为多行。
-
Oracle将 ^ 和 $ 分别解释为源字符串中任何位置的任何行的开始和结束,而不仅仅是整个源字符串的开始或结束。如果省略此参数,则Oracle将源字符串视为一行
-
- ORA_HASH计算HASH值

select object_id,
ora_hash(ownerllobject_name)hashval from dba obajects
- Connect by
select * from table [start with condition1]
connect by [nocycle]
[prior]id=parentid==
1)[start with condition1]递归开始的条件,第一层
2)connect by [prior] id=parented 递归条件
3)[prior] id为当前层,parented为递归查询列,下次递归SQL类似select*from table where parented=id(当前层)
示例:
set lines 400 col txt for a100 set tab off
with t as
(select*from vSsql_plan
where sql_id="7fybj6y7ug6q2'
AND CHILD_NUMBER=0).
select id,
parent_id,
LEVEL,
lpad("", level*2-1,") || operation ||'' || options ||'' ||
object_owner || decode(object_name, null,",.") || object_name txt
from t
start with id=0
Connect by parent_id= prior id;
Select * from t where parent_id=0
Selct * from t where parent_id=1
复制
Connect by 可用的函数、伪列
1)SYS_CONNECT_BY_PATH(column,char)层级路径
2)CONNECT_BY_ISLEAF是否为页子节点
3)LEVEL当前层级,始于1
4)CONNECT_BY_ISCYCLE是否产生死循环,只有制定NOCYCLE时才能使用该伪列

三、常用SQL技巧
1、生成数据
(1)递归生成数字列表
select rownum rn from dual
connect by rownum<=10;
复制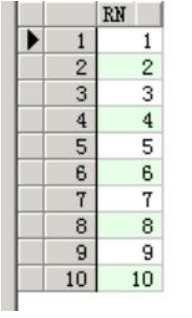
rownum<=10;
改变这个条件,可生成不同数量的数字列表。
如下想生成偶数列表呢?
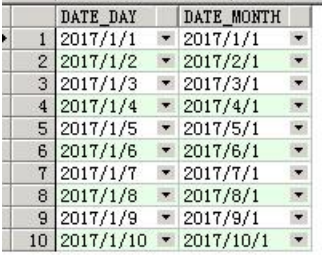
(2)生成日期列表,通过生成数字列表的方式扩展
select to_date('2017-01-01','yyyy-mm-dd')+rownum-1
date_day,
add_months(to_date('2017-01-01','yyyy-mm-dd'),rownum-1)
date_month from dual
connect by rownum<=10;
复制根据不同需要,可以天列表,月列表
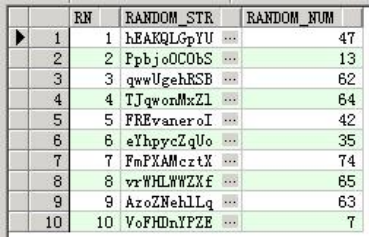
(3)生成随机数据(使用包DBMS_RANDOM)
select rownum rn,dbms_random.string('a',10)
random_str,abs(mod(dbms_random.random(),100)) random_num
from dual
connect by rownum<=10;
复制- dbms_random.string(‘a’,10)
改变参数可限制生成的字符串长度
- mod(dbms_random.random(),100)
改变参数可限制生成的数字范围
参数注意:
- 小数(0 ~ 1)
select dbms_random.value from dual ;
- 指定范围内的小数 ( 0 ~ 100 )
select dbms_random.value(0,100) from dual ;
- 指定范围内的整数 ( 0 ~ 100 )
trunc(dbms_random.value(0,100)) from dual ;
- 随机字符串
select dbms_random.string(‘x’, 3) from dual ;

2、统计分析
使用case when 行转列
(与DECODE类似,但DECODE只能是等值查选)
如下面统计每个用户下,2017年以前创建的对象有多少,2017年及以后创建的对象有多
少?
select owner,
sum(case when created'2017','yyyy') then 1 else 0end) "2017年以前",
sum(case when created>=to_date('2017','yyyy') then 1 else 0end) "2017年及以后"
from dbmt.db_objects where object_type in ('TABLE','INDEX')
group by owner
复制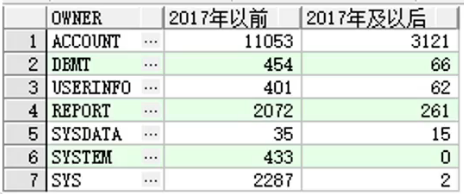
3、SQL技巧
查找连续值
可以查找出序列中的连续值或中断位置
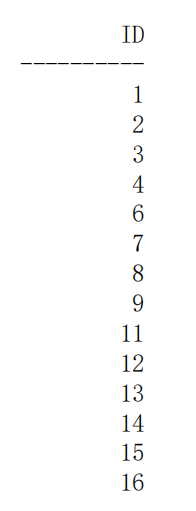
select min(id), max(id)
from (select id,id - rownum rn
from (select id from dbmt.list1
order by id))
group by rn
having count(rn) > 1
order by min(id);
MIN(ID) MAX(ID)
---------- ----------
1 4 //1-4连续
6 9 //6-9连续
11 21 //11-21连续
24 49 //24-49连续
复制4、XML TABLE
可通过函数提取分支数据
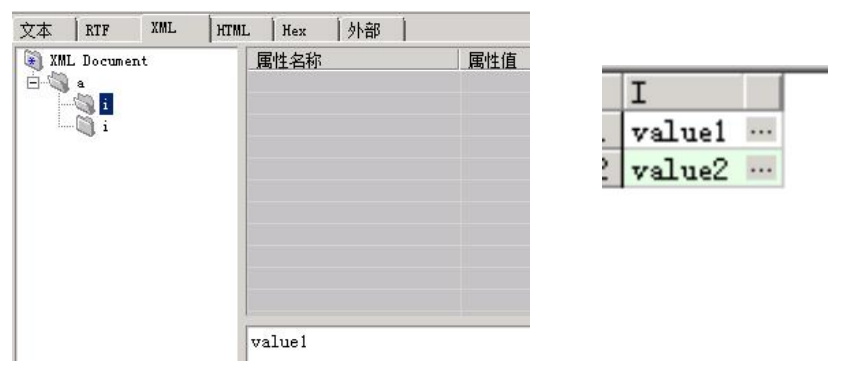
with t as (select xmltype('value1value2') xmlvalfrom dual)
select i from t a,
xmltable('/a/i' passing xmlval columns i path '/i')
复制
老师在直播中还讲解了一些关于null的注意事项,感兴趣的朋友点击查看回放视频、PPT继续学习。
回放视频:https://www.modb.pro/course/play/97?lsId=4811
课件下载:https://www.modb.pro/doc/42329
SQL资源下载
文章中包含的部分SQL(ASH、check cpu、stats_diff、 wait chain以及时序数据异常波动)大家可以点击👇下载合集。
范计杰老师个人主页:https://www.modb.pro/u/3770。
欢迎大家在文章评论区留言或前往老师个人主页留言互动。
