





陈焕生
Oracle Real-World Performance Group 成员,senior performance engineer,专注于 OLTP、OLAP 系统 在 Exadata 平台和 In-Memory 特性上的最佳实践。个人博客 http://dbsid.com 。
编辑手记:感谢陈焕生授权我们发布他的精品文章,Sidney 撰写这个系列的文章时间跨度也有两年,下篇刚刚出炉。
上篇分为两篇文章:
深入并行:从生产者到消费者模型深度理解 Oracle 的并行(http://dwz.cn/3vQ7I9)
深入并行:从数据倾斜到布隆过滤深度理解 Oracle 的并行(http://dwz.cn/3vQaDb)
在深入理解 Oracle 的并行执行(上)中, 阐述了一个并行执行计划包含的四个核心概念:
DFO: Data FlowOperators, 可以并行执行的操作, 比如全表扫描, hash join.
Table Queue: 生产者和消费者之间的数据分发. 常见的数据并行分发方式有 broadcast, hash. 12c引入多种新的数据分发, 比如 replicate, 更加智能的 adaptive 分发.
Granule: 并行扫描数据时, 表的数据如何切分, 按照地址区间, 或者以分区为单位的
QC: 对生产者和消费者PX进程进行管理和调度
本篇文章, 我将谈谈并行执行的其他两个主题
并行加载数据时四种数据分发方式, 分别为 None/ Partition/Random/Randomlocal.
12C 的 Adaptive 分发特性
Oracle 版本为12.1.0.2.7, 两个节点的 RAC, 硬件为 Exadata X3-8.
这是一个典型的星型模型, 事实表 lineorder 有3亿行记录, 维度表 part/customer 分别包含1.2M 和1.5M 行记录, 3个表都没有进行分区, lineorder 大小接近 30GB.
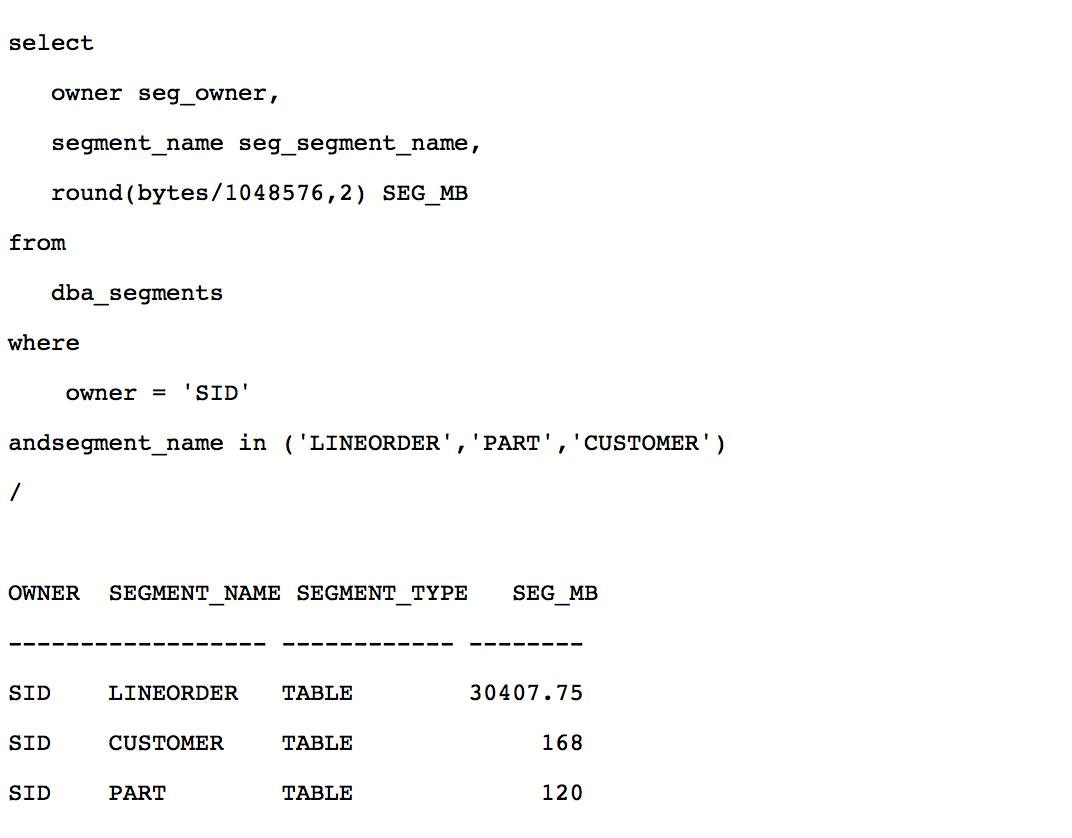
表名 | 行数 |
lineorder | 300005811 |
part | 1200000 |
customer | 1500000 |
对于 CTAS(CreateTable As Select) 或者 IAS(Insert asselect) 形式的并行插入语句, 作为生产者的 PX 进程执行查询操作, 作为消费者的 PX 进程执行数据插入. 生产者和消费者之间数据存在以下四种分发方式.
None: 只需一组PX进程, 把查询, 数据加载操作合并在一起. 因为数据不需要通过进程间或者节点间通信进行分发, 加载大量数据时, 这种方式可以节省大量CPU, 通常是并行加载最快的方式.使用这种方式需要注意两点:
① 数据倾斜: 如果查询部分数据存在倾斜, 会导致后续插入操作的也存在执行倾斜
② 内存的消耗: 对于分区表, 因为每个PX进程都会插入数据到每一个分区, 每个分区的数据需要0.5M 内存的缓冲数据, 对于使用HCC(Hybrid ColumnarCompress: 混合列压缩)压缩的表, 缓冲区大小为1.5M, 以提高写性能. 当分区数很多, 或者DoP很大时, 总的内存消耗接近DoP * 分区数 * 0.5M(对于HCC压缩表是1.5M).
Partition: 根据目标表的分区属性, 查询PX进程把数据发送给相应加载PX进程. 当分区数大于DoP时, 每个加载 PX进程会平均加载多个分区的数据. 这种方式操作每个分区的PX进程最少, 消耗的内存也最少. 如果分区间的数据存在倾斜, 加载PX进程会出现执行倾斜.
Random: 查询 PX 进程把数据按照round-robin的方式分送给每个加载PX进程.
Random local: 于 random 方式类似, 使用 slaves mapping 特性, 按 round-robin 的方式分发给本实例的加载 PX 进程, 避免节点间的数据传输. Random local 的数据分发成本比 Random 更低, 消耗的内存也更少. 如果使用 none 分发内存过大, 又不能使用 partition 分发因为分区数据存在倾斜, 那应该选择 random local 的分发方式.
PQ_Distribute 这个 hint 除了可以控制 hash join 时数据的分发方式, 从11.2开始, 也可以控制并行加载时数据在查询PX进程和加载PX进程之间的分发方式. 为了说明数据倾斜, 内存消耗对各种分发方式的影响, 我构造一个 range-hash 复合分区表, 一级分区为32 个 range 分区, 每个分区区间大小不同使数据存在倾斜, 二级分区为16个 hash 分区, 总共512个子分区. 并行度为64.



None 无数据分发
通过hint pq_distribute(t_nonenone)使数据不需要分发.

SQL执行时间为2.1分钟, DB Time为18.5分钟. 执行计划只需一组蓝色的PX进程.
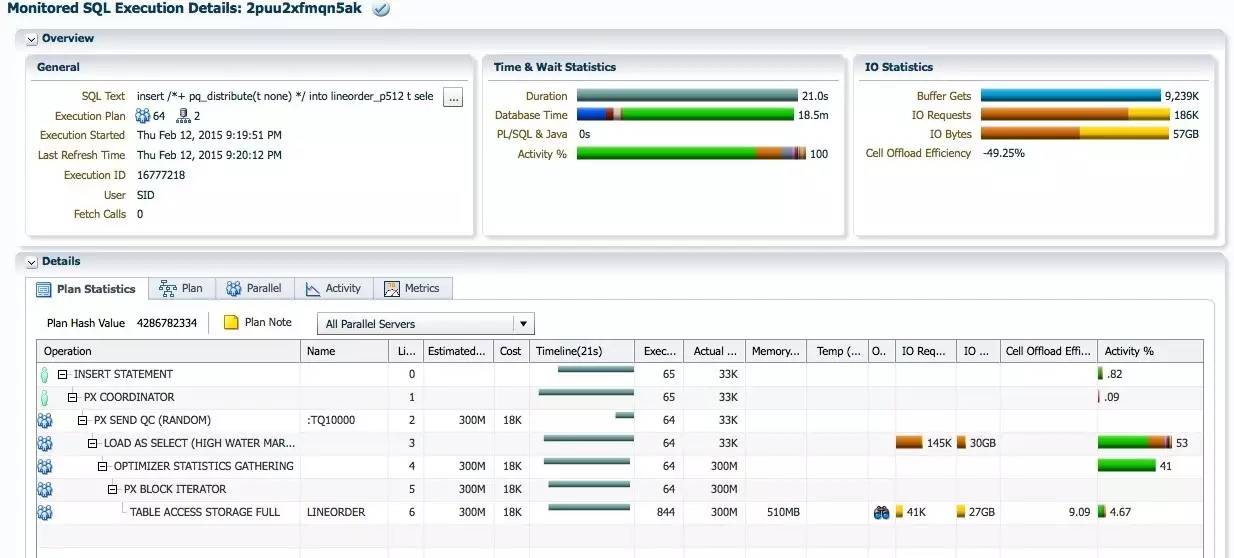
每个PX进程都加载512个分区的数据, 最大的PGA消耗为13.86GB, 接近预估的值: DoP*[Number of Subpartitions]*0.5MB = 64*512*0.5MB = 16GB. IO Interconnect的流量=read bytes +2*(Write Bytes), 每秒接近6GB. CPU的AAS保持在60左右, 这是期望的情况, 不需要数据分发, 充分利用系统的 CPU资源和IO带宽, 进行数据加载,

Partition 分发
通过 hint pq_distribute(tpartition) , 使用partition分发方式.

SQL执行时间为39秒, db time为24.2分钟. DB time比none分发时的两1.5倍, 因为第5行PX SEND PARTITION(KEY)占23%的db time, 第4行的PX RECEIVE占8.41%的db time, 数据分发一共占 31.41%的db time. SQL执行时间几乎为none分发时的两倍, 是因为分区数据存在倾斜导致加载的PX进程之间存在执行倾斜.
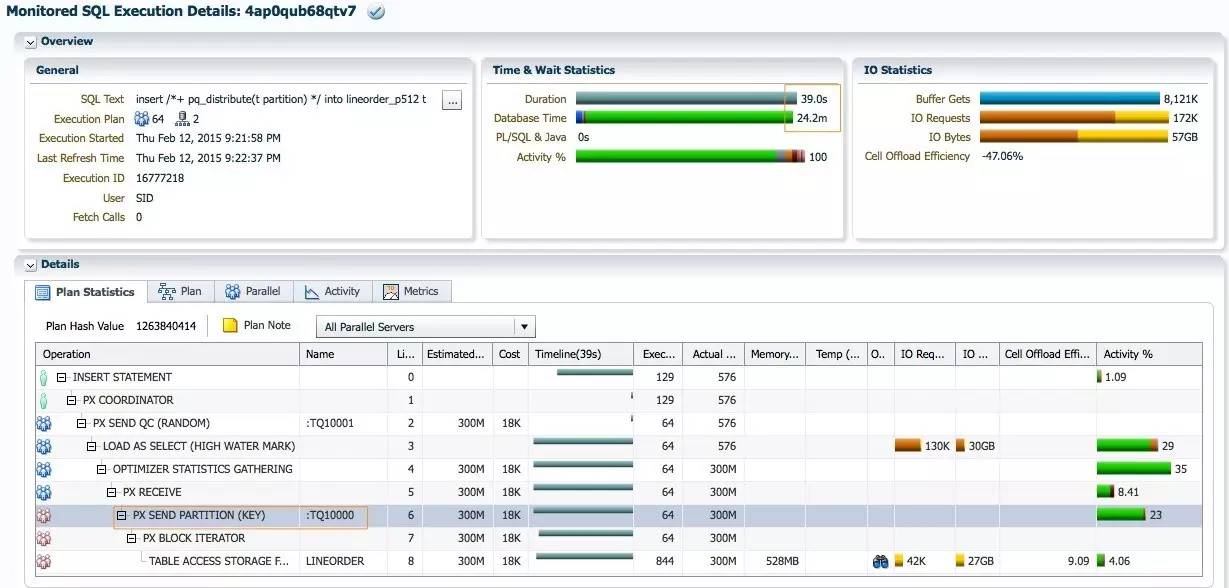
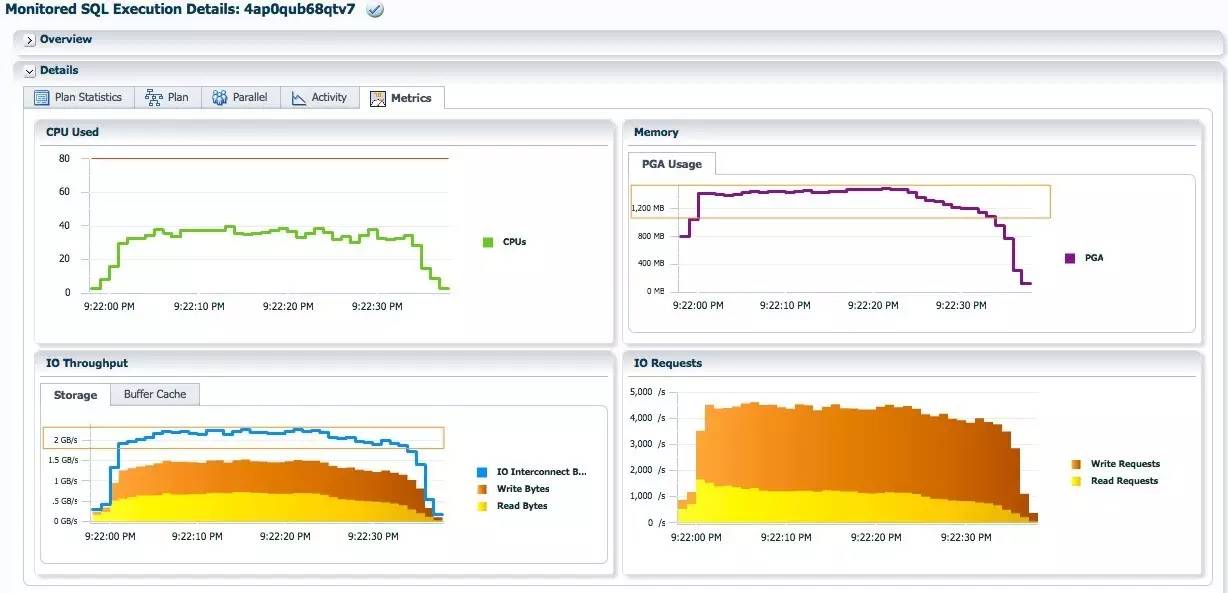
每个蓝色的PX加载进程只需加载8个分区的数据, 最大的PGA消耗为1.44GB, 仅为none分发的十分之一, IO interconnect的流量接近2.2GB每秒. 于none分发的峰值6GB每秒的流量相差很多. CPU的AAS只在40左右.
从视图V$PQ_TQSTAT观察并行倾斜, 每个红色的查询PX进程通过 table queue 0分发大约4.6M行记录, 蓝色的加载PX进程接收的数据接收的记录数差别很大, 有的超过10M, 有的接近4百万, 有的只有2M.


Random local 分发
通过hint pq_distribute(trandom_local) 使用random local的分发方式.
insert *+ pq_distribute(t random_local) */ intolineorder_p512 t select * from lineorder;
SQL执行时间为32秒, db time为27.5分钟. 相比partition分发, Random local分发的db time增加三分钟, 但是sql执行时间缩短了, 因为消除了并行执行倾斜.

每个蓝色的PX加载进程只需加载256个分区的数据, 最大的PGA消耗为7.88GB, 大概为none分发时的一半. IO Interconnect的流量每秒大概3GB.
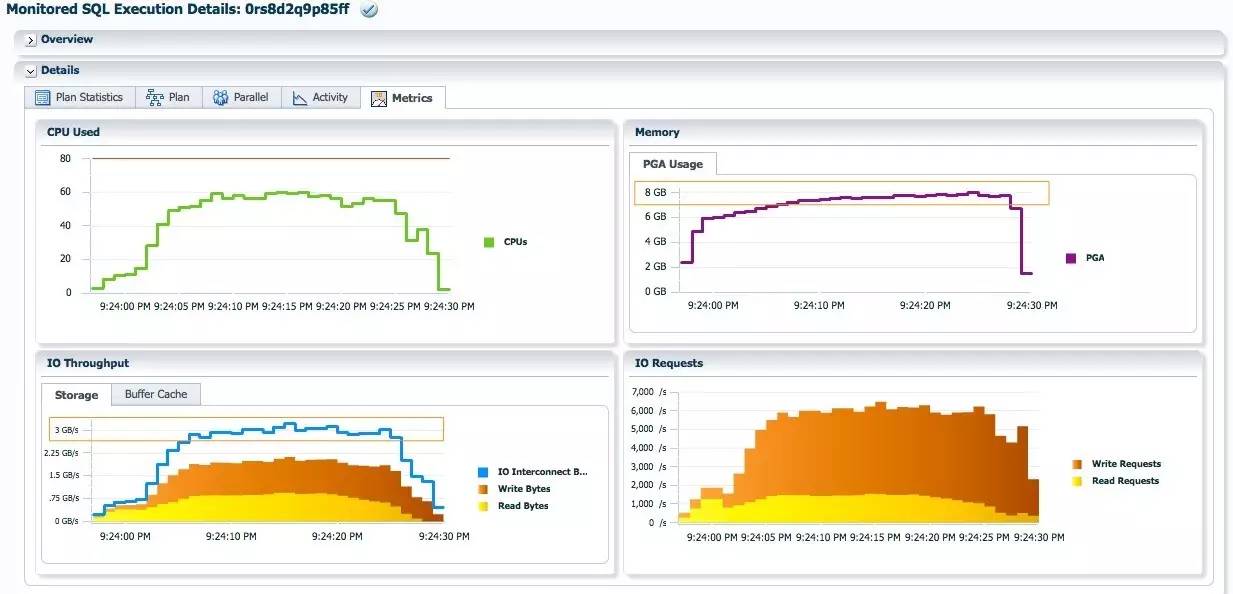
Random 分发
通过hint pq_distribute(trandom) 使用random local的分发方式.

SQL执行时间为49秒, db time为29.1分钟. Random分发相对于random local分发, 性能明显下降, 实际中很少使用random分发.
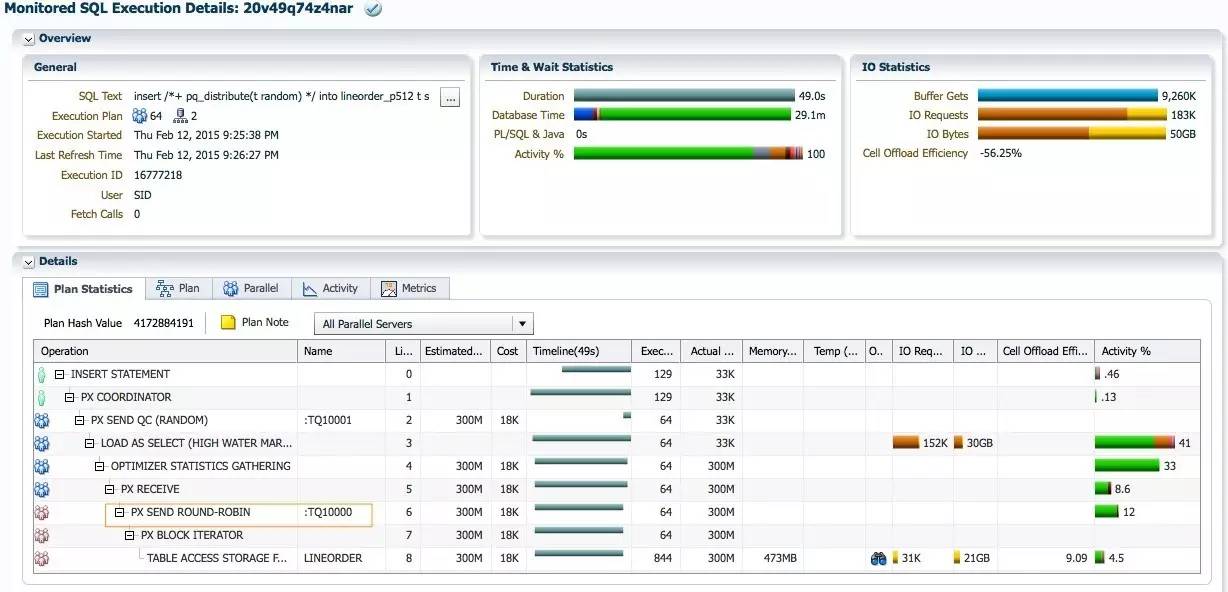
每个蓝色的PX加载进程加载512个分区的数据, 和none分发类似, 最大的PGA消耗为13.77GB.
IO interconnect最大的流量为2.5GB每秒.

小结
为了充分发挥系统的CPU和IO能力, 在并行加载时, 应该尽可能的使用none分发的执行计划. 除非查询部分存在倾斜, 或者内存不够限制无法使用none分发. 当目标表的分区数很多时, 优化器考虑到none分发消耗的内存过滤, 过于保守会选择partition分发或者random local分发的方式, 比如上面的例子中, 没有使用pq_distribute的话, DoP=64时, 优化器选择random_local的分发方式. 因此实际中, 往往需要使用pq_distribute指定合适的分发方式.
12c 引入了 adaptive 分发特性, 执行计划中的分发操作为 PX SEND HYBRID HASH. Adaptive 分发在运行时, 根据 hash join 左边的数据量, 决定何种分发方式. Adaptive 分发也可以解决连接键存在数据倾斜, 导致 hash 分发并行执行倾斜的情况. Adaptive 分发的工作机制如下:
1. 执行计划中, 对 hash join 左边分发之前, 会插入一个STATISTICS COLLECTOR操作, 用于运行时确定hash join左边数据集的大小. 如果hash join左边的数据量小于并行度的两倍, 那么对于hash join左边的分发会切换为broadcast方式, 对hash join右边的分发为round-robin. 如果hash join左边的数据大于等于并行度的两倍, 对于hash join两边的分发方式都为hash, 和传统的hash分发一样.
2. 如果存在柱状图信息, 表明hash join右边连接键上存在数据倾斜, 大部分数据为少数热门的值. 硬解析时, 会对hash join右边的表进行动态采样, 确认热门的值. 通过如下分发方式消除数据倾斜的影响:
· Hash join的左边, 热门的数据会被广播到每个接收者, 不热门的数据被hash分发.
· Hash join的右边, 热门的数据通过round-robin的方式发送, 非热门的数据被hash分发.
我将在本章演示 Adaptive 分发的动态特性, 以及如果处理数据倾斜的. 本章的所有测试, optimizer_adaptive_features 设置为 true, 以使用 adaptive 分发特性.
Hash join 左边数据量小于 DoP 的两倍时
测试 SQL 如下, DoP=4. 在 customer 上使用 c_custkey<8 的条件, 返回7行记录, 刚好小于8(=2*DoP).

查询时间为3秒, 观察 Timeline 列时间轴信息, 执行计划中的操作 first active 的时间在3秒左右, 硬解析花了接近3秒的时间. SQL 执行过程如下:
1. 作为生产者的红色PX进程对 customer 的扫描过滤结果为7行记录, 在进行 adaptive 分发之前, 执行计划插入 STATISTICS COLLECTOR 操作, 判断 hash join 左边结果集的大小于两倍 DoP 的关系. 因为结果集只有7行记录, 小于8(两倍DoP), 所以第8行的 PX SEND HYBRID HASH 操作实际为 broadcast 分发. 通过 table queue 0, 每个蓝色的PX进程接收了7行 customer 记录, 总共28行, 并创建布隆过滤: BF0000, 发送给红色的 PX 进程, 并准备好第5行 hash join 的 build table.
2. 作为生产者的红色 PX 进程并行扫描 lineorder 时使用布隆过滤: BF0000, lineorder 过滤完只有1507行, 第5行的 hash join 结果集也为1507, 说明这是一个完美的布隆过滤. 因为布隆过滤卸载到存储节点之后, 返回数据量占总体300M行记录的比例太小, Cell Offload Efficiency 为100%. 红色的PX进程, 把 lineorder 的1507行记录, 通过 table queue 1, 以 round-robin 的方式, 分发给蓝色的 PX 进程.
3. 每个作为消费者的蓝色PX进程, 接收 lineorder 大约377行记录之后, 和 hash join 左边的7行记录进行连接. 连接结果集为1507行记录, 进行聚合之后为4行记录, 通过 table queue 2 发给 QC.
4. QC 做最终的聚合, 返回数据.


Customer 符合条件的7行记录, 都由实例2 P003 进程扫描得到, 通过 table queue 0, 广播给每个消费者PX进程. 对于 lineorder 的分发, 虽然每个生产者发送的数据量存在差异, 分别为311/552/313/331, 发送记录数之和为1507. 因为分发方式为 round-robin, 每个消费者接收的数据量接近平均, 分别为 377/375/378/377.


Hash join 左边数据量大于等于 DoP 两倍时
把条件改为 c_custkey<=8, customer 有8行记录符合条件, 等于两倍 DoP.

查询执行时间为2秒. 此时执行计划和 c_custkey<8 时相同, Plan Hash Value 都为1139249071 , table queue, 布隆过滤的位置和编号是相同的, 并行执行的顺序完全一样.
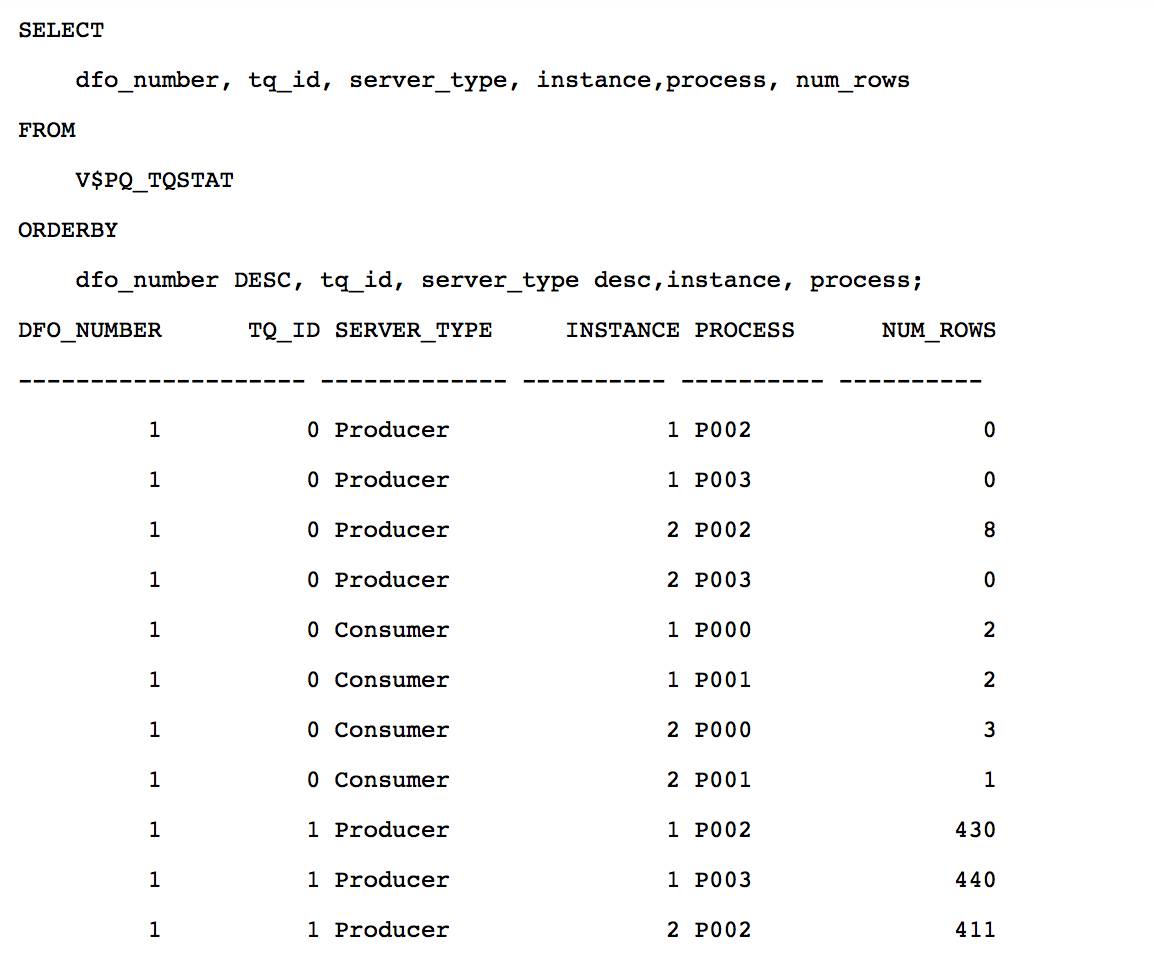
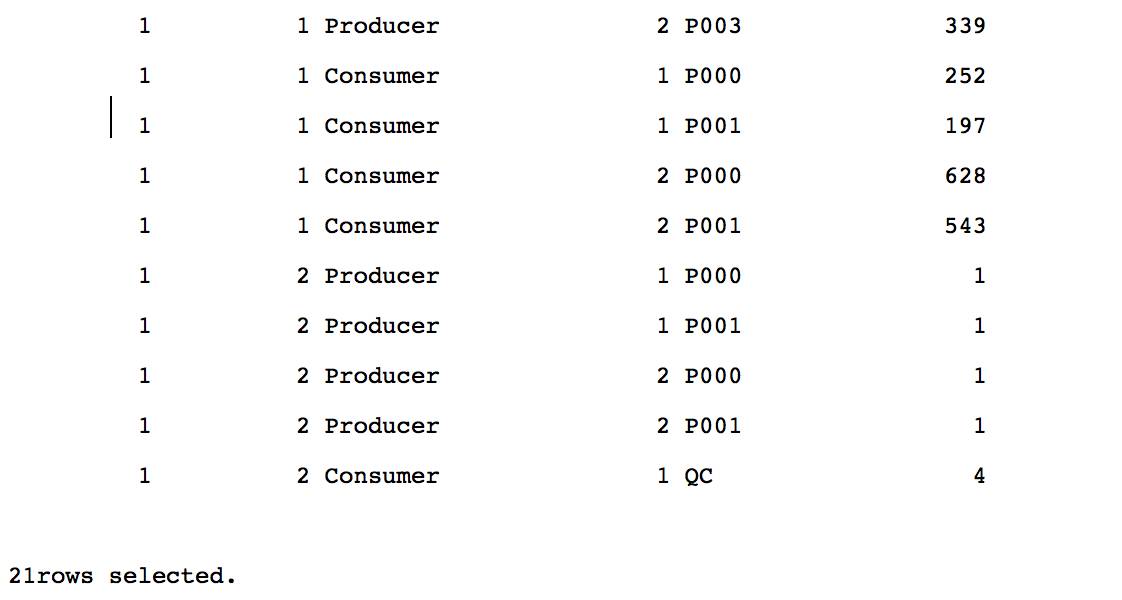
因为 hash join 左边的数据集有8行记录, 等于两倍 DoP, PX SEND HYBRID HASH 操作对 customer 数据的分发为 hash 分发. 红色的 PX 进程通过 table queue 0, hash 分发8行记录. 4个蓝色的 PX 进程一共接收8行 customer 记录, 然后分别对 c_custkey 列生成布隆过滤: BF000, 发送给4个红色的 PX 进程.
作为生产者的4个红色 PX 并行扫描 lineorder 时, 使用布隆过滤: BF0000, 过滤完为1620行记录, 第5行的 hash join 结果集为1620行, 说明布隆过滤: BF0000 是完美的. 1620行记录table queue 1, hash 分发给4个蓝色的 PX 进程. 蓝色的 PX 进程接收 lineorder 数据之后, 进行 hash join 和聚合, 再把结果集发给 QC.


Customer 符合 c_custkey<=8 的8行数据, 都由实例2 P002 进程扫描获得, 然后 hash 分发给4个消费者, 分别接收2/2/3/1行. 对 lineorder 过滤之后的1620行记录, 通过 hash 分发之后不像 round-robin 那样均匀, 4个消费者分别接收 252/197/628/543行.
小节
本节介绍 adaptive 分发如何根据 hash join 左边数据集的大小, 和两倍 DoP 的关系, 决定对 hash join 左右两边的分发方式. 两倍 DoP 这个阀值由隐含参数_px_adaptive_dist_method_threshold 控制, 默认值为0, 代表两倍 DoP.
为了演示 adaptive 分发如何处理数据倾斜, 新建两个表, customer_skew 包含一条 c_custkey=-1的记录, lineorder_skew 90% 的记录, 两亿七千万行记录 lo_custkey=-1.


Adaptive 分发, 意想不到的硬解析问题
为了使用 adaptive 分发特性, 解决 lineorder_skew.lo_custkey 数据倾斜的问题, 我们需要:
1. 设置 optimizer_adaptive_features 为 true.
2. 收集 lineorder_skew 在lo_custkey 列上的柱状图信息.
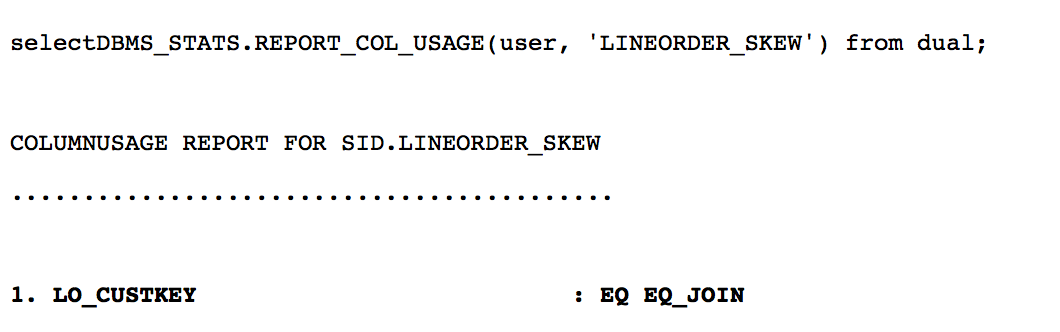
推荐使用 DBMS_STATS.SEED_COL_USAGE❶, 监控sql是使用了哪些列, 以及如何使用. 通过 explain plan for 命令解析 sql, 给优化器提供关键的信息, 比如那些列是连接键. 使用默认值选项收集统计信息时, 系统根据已有的信息, 自动收集所需的统计信息, 包括倾斜列上的柱状图信息. 下面的过程演示了 DBMS_STATS.SEED_COL_USAGE 简单使用方法.
过程如下, 一开始, LO_CUSTKEY 列上没有柱状图信息(HISTOGRAM=NONE).

进行一次硬解析

查询对于 lineorder_skew 的监控结果, 在 lo_custkey 上使用的相等连接的操作, 为统计信息的收集提供了关键信息.
使用默认 auto 选项收集统计信息

重新收集统计信息之后, lo_custkey 列上有了 HYBRID 类型的统计信息.

设置 optimizer_adaptive_features 为 true, 使用与 hash 分发时相同的 sql 重新执行:

出乎意料的是, sql 的执行时间为65秒, 比使用 hash 分发时58秒还慢了7秒.

执行计划的结构以及执行顺序和 hash 分发时类似, 但是分发的操作不一样. 从第8行 STATISTICS COLLECTOR, 第9行PX SEND HYBRID HASH 这两个操作可以确认, 并行执行使用了adaptive分发. 因为 lineorder_skew.lo_custkey 数据存在倾斜, 对于 lineorder_skew 的分发操作为 PX SEND HYBRID HASH(SKEW).
奇怪的是从 Timeline 列时间轴信息可以看到, 所有并行操作的 first active 时间为36秒, 这意味着所有 PX 进程在36秒时才开始执行 sql, sql 的实际执行时间只需30秒. 在执行查询时, SQL 一般需要经过解析-执行-返回数据等三个阶段, 因为我们使用 adaptive 分发, 并且 lineorder_skew.lo_custkey 列上的柱状图信息暗示了数据倾斜, 在硬解析阶段需要对 lineorder_skew 进行采样, 确认热门值.
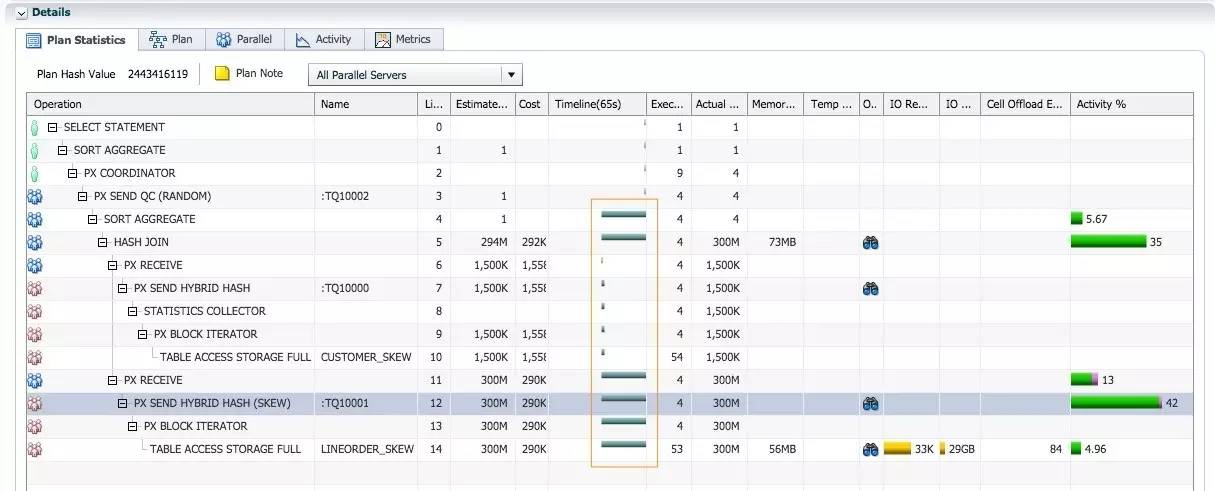
在 sql 的活动信息中, 一半时间处于硬解析阶段, 出现 cursor: pin S, cursor: pinS wait on X等 shared pool 相关的等待, 同时还有多块读的 IO 和 GC 等待, 这是采样 lineorder_skew 引起的. 在硬解析之后 sql 执行时, AAS 大于4, 至少4个 PX 进程同时活跃, 这是 adaptive 分发消除并行执行倾斜之后, 期望的效果. 这个例子中, Adaptive 分发带来的性能改进被长时间硬解析问题掩盖了.下一节, 我们将通过10046事件, 分析硬解析为什么需要30秒左右的时间.
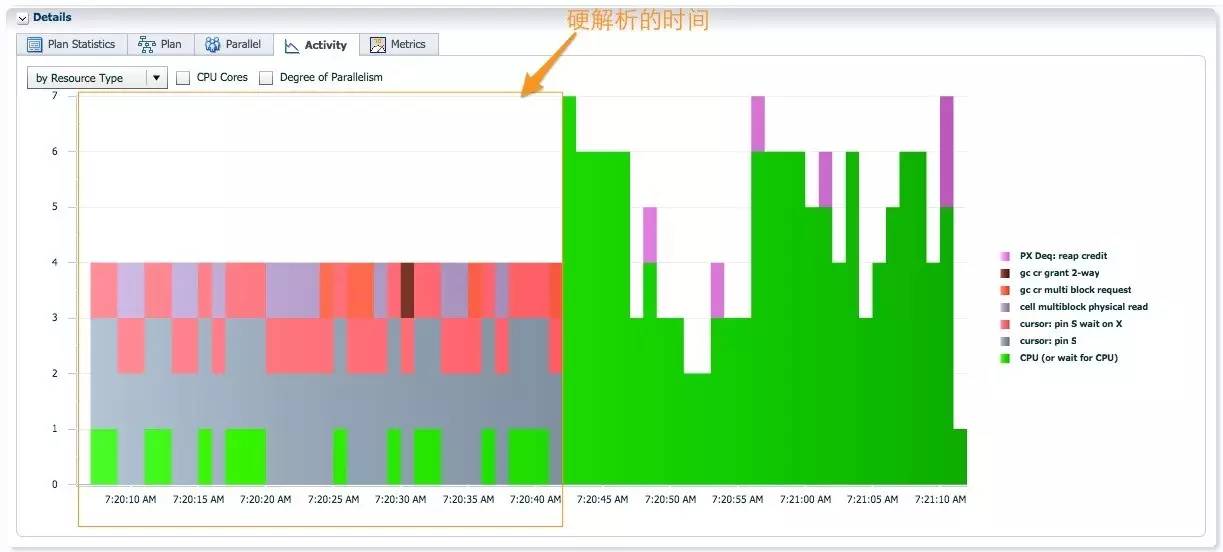
DS_SKEW 采样语句造成长时间的硬解析
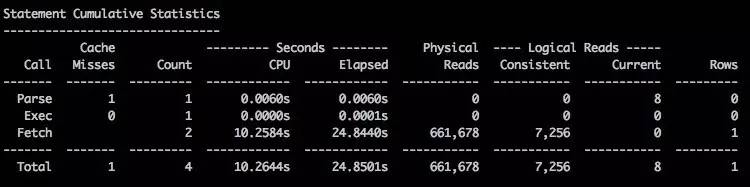
下面的测试, 我们可以确定硬解析过长的问题只有使用 adaptive 分发时出现(新特性引入新问题, 你应该不会惊讶吧J). 默认replicate 方式, 硬解析时间为0.3秒, adaptive 分发, 硬解析时间为24.89秒.
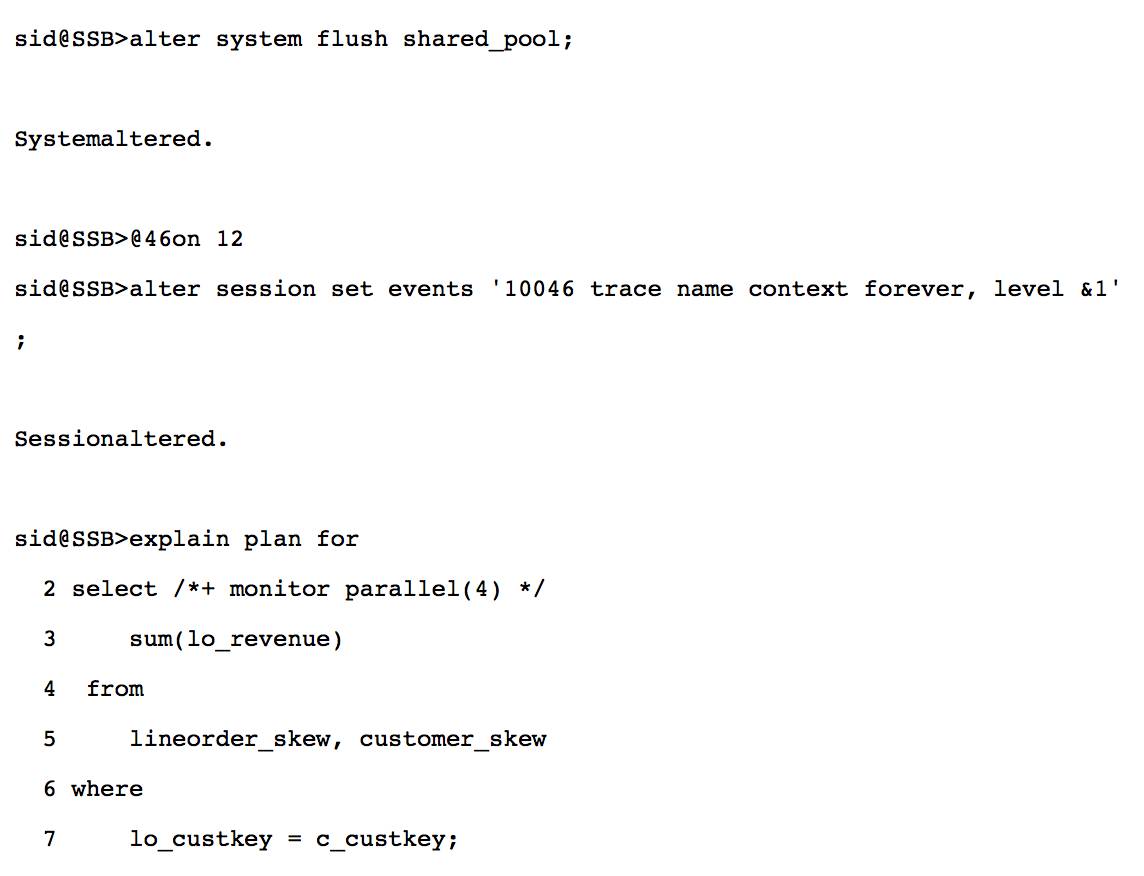
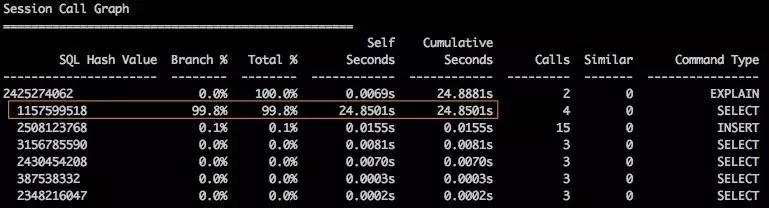
我使用 orasrp❷ 这个工具分析 adaptive 分发硬解析时的10046跟踪文件. 分析递归调用树(Session Call Graph)部分, 几乎所有的硬解析时间都来自 sql hash value=1157599518 这个递归 sql.
SQL hashvalue=1157599518 如下, DS_SKEW 的注释表明处理数据倾斜时, 这条 sql 用以确定最热门的值.
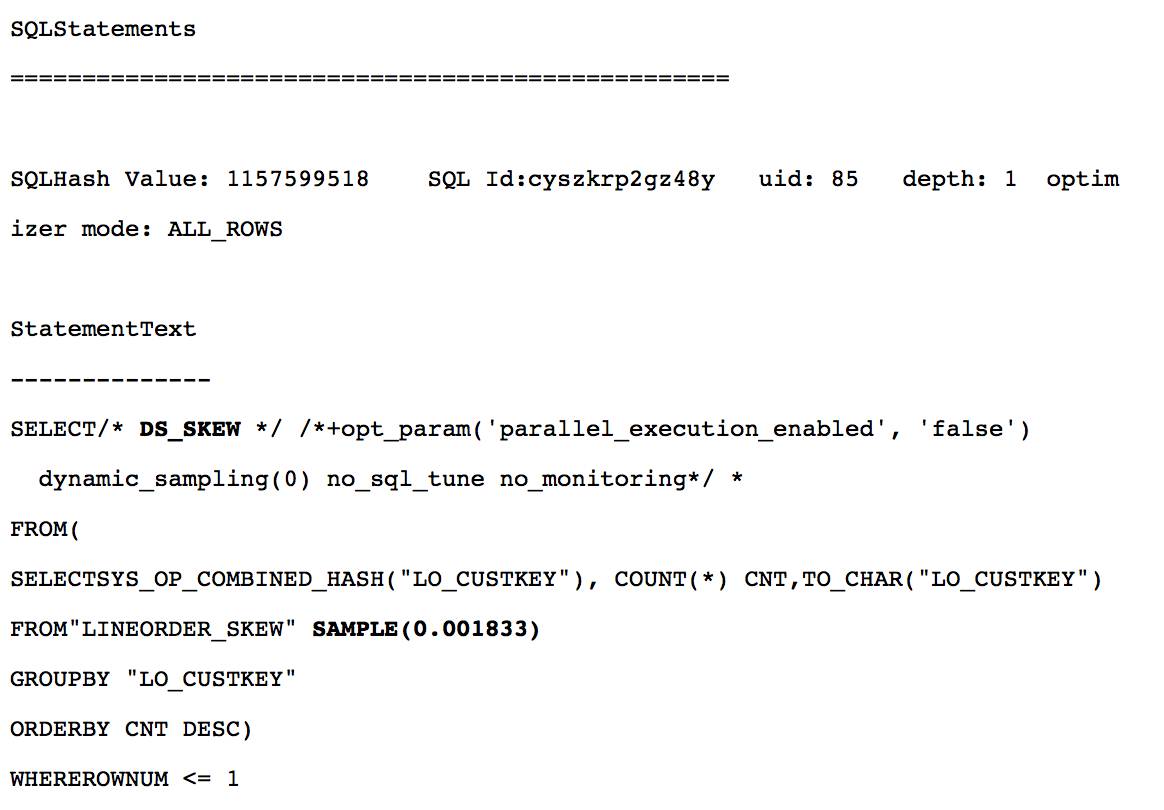
DS_SKEW 采样语句需要24.8秒的原因在于:
1. 使用行采样, 而不是块采样. 采样语句使用 SAMPLE, 而不是 SAMPLE BLOCK, 导致了661678次物理读.
2. 没有一个中断机制, 当采样 sql 执行时间过长时取消进行中断.
DS_SKEW 采样语句执行过长是一个已知的问题, 通过 bug 21384810 在12.2版本修复, 12.1.0.2已有补丁发布.
Bug 21384810 -GCW 12C: PARSE TIME REGRESSION DUE TO JOIN SKEW HANDLING (DS_SKEW QUERY)
因为 DS_SKEW 采样语句与 adaptive 分发特性是绑定在一起的, 使用 adaptive 分发无法绕过 DS_SKEW 采样语句. 如果你发现硬解析的成本高于 adaptive 分发带来的性能提升, 你可以通过以下两种方法关闭 adaptive 分发特性.
1. optimizer_adaptive_features=false.
2. _px_join_skew_handling=false,此时你可以保留optimizer_adaptive_features=true,使用其他adaptive特性.
第二次执行以下 SQL, 观察不需要硬解析时, adaptive 分发的实际效果.

查询执行时间为28秒, 接近 replicate 时23秒.

对于 lineorder_skew300M 行记录的 adaptive分发, 和 hash join 操作, 消耗了大部分的 db cpu.
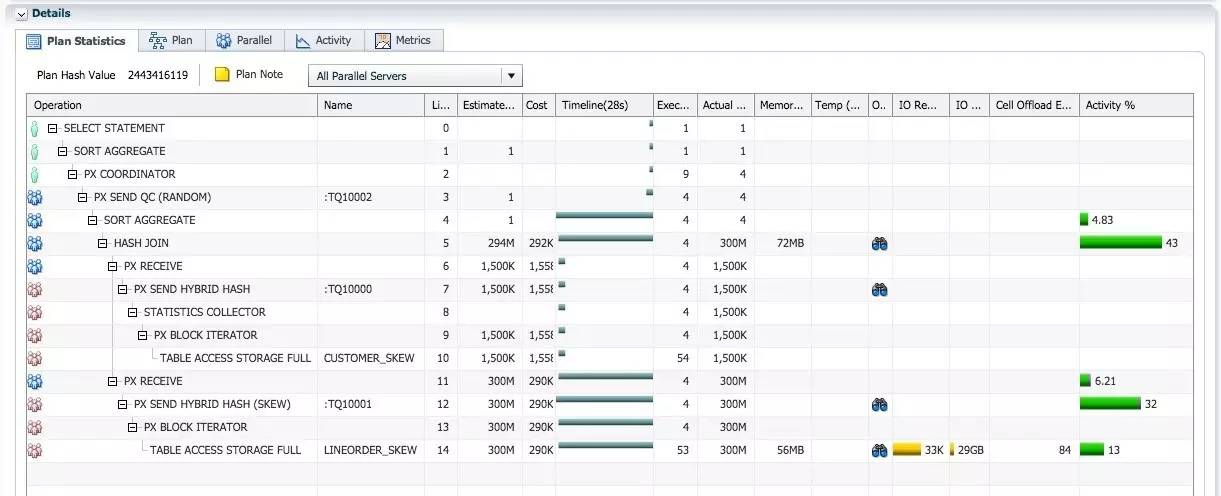
使用 adaptive 分发时, 蓝色 PX 进程不再出现执行倾斜的情况.

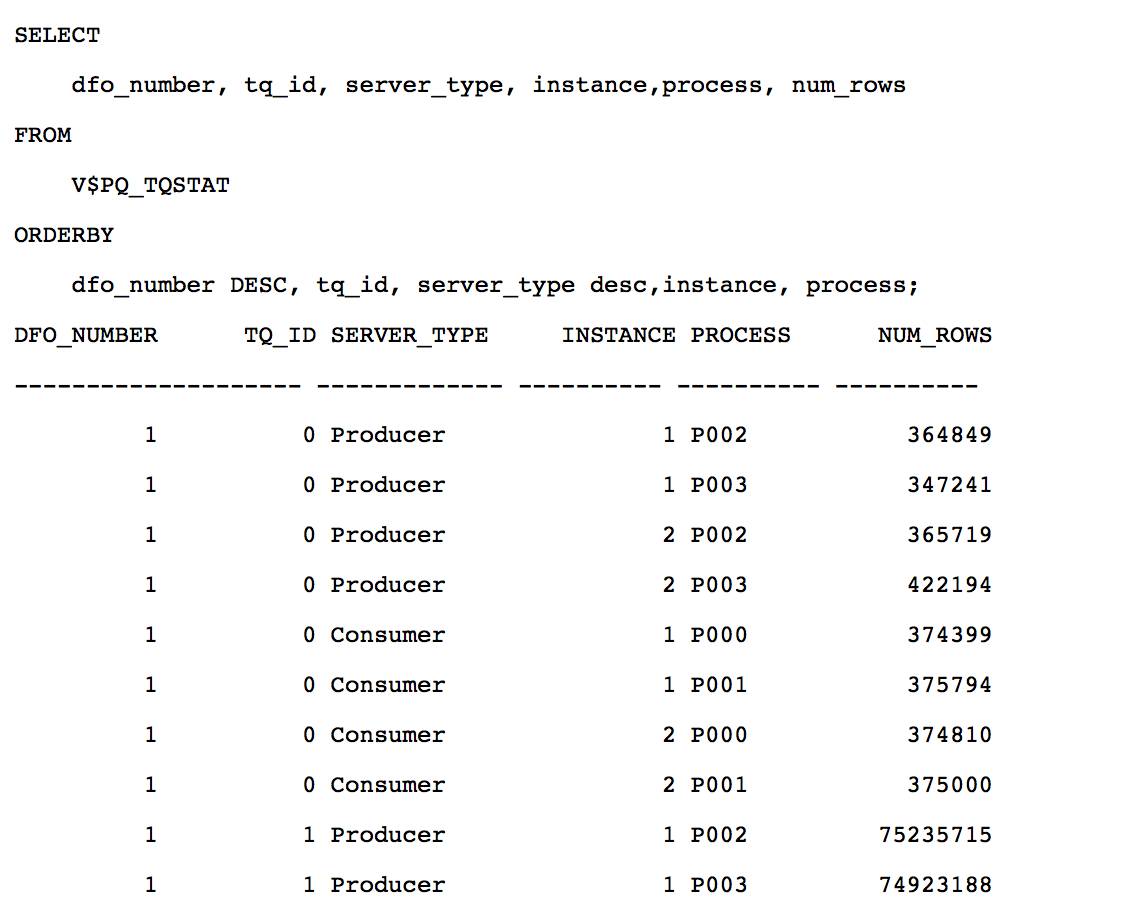
从 V$PQ_TQSTAT 视图可以确认, 对 lineorder_skew 通过 table queue 1的 adaptive 分发, 每个消费者接收了 75M 行记录左右, adaptive 分发解决了数据倾斜的影响.

❶推荐阅读 OracleOptimizer Blog 关于 DBMS_STATS.SEED_COL_USAGE 更详细的介绍和实例:https://blogs.oracle.com/optimizer/entry/how_do_i_know_what_extended_statistics_are_needed_for_a_given_workload
❷orasrp: OracleSession Resource Profiler, 来自俄罗斯的强大的10046分析工具. http://oracledba.ru/orasrp/

