





读取数据并可视化
簇分配和质心移动
初始化K个质心
把每个样本分配予最近的质心
重新计算每一簇的质心,移动质心
判定移动质心是否对结果提升
直至收敛
聚类过程可视化
质心分割
质心移动轨迹和簇分布
前言
我们之前遇到的所有机器学习算法都属于带标签的监督算法,而实现生活中大部分数据是不带标签的,从今天起我们要学一些处理不带标签数据的非监督算法,先从Kmeans聚类算法开始,我们将从以下几个方面来介绍Kmeans聚类算法
什么是聚类? 聚类与分类的区别 Kmeans算法常用的距离公式 Kmeans算法流程 Kmeans算法实践 Kmeans算法优缺点分析 Kmeans算法应用场景
什么是聚类?
俗话说:“物以类聚,人以群分”,意思是说具有共同特质的人或物更容易聚集在一起,聚类算法正是依循这一客观规律,通过技术手段,将相似的研究对象聚集在同一个类里面,将相异的研究对象聚集在不同类里面,使得同一个类里面的研究对象具有极大的相似性,不同类的研究对象具有极大的差异性,聚类后的研究对象的内在结构就更加清楚明了。
聚类与分类的区别
聚类和分类看起来都是把一些样本分到相同或者不同的类,但是两者却有着本质区别,尤其是初学者对聚类和分类还是很难分清楚的,可以从以下几个方面来进行区分
(1) 目的
聚类的目的是要找出数据之间的相似性和相异性,在聚类之前并不清楚到底分多少类,也不清楚每个类里面包含哪些样本,甚至用什么方式方法来分也不确定,侧重总结归纳,而分类是在“分”之前就清楚知道总共有多少类,现在要确定新的样本到底属于哪个类,侧重预测。
(2) 操作
聚类是不需要利用已知数据进行训练的,直接聚类出结果,而分类是需要利用已有的数据训练出一个可靠的模型,然后利用这个模型去预测新的样本并给出判定,是一个训练加预测的过程;
(2) 范畴
正如上面所提,聚类是不需要利用已有的训练模型来对未知数据做预测,不需要数据类别标签,属于无监督学习,而分类是需要有一个训练过程得到一个训练模型,这个训练是有数据类别标签参与的,属于有监督学习。
Kmeans算法常用的距离公式
数学上常用距离来度量两个对象之间相隔多远,除此之外,距离还可以用来表示研究对象之间的近似程度,而聚类算法就是要根据研究对象的相似程度来决定哪些应该聚在一起,哪些不应该聚在一起,在聚类算法里面常用的一些距离公式有欧几里得距离,曼哈顿距离,闵可夫斯基距离,切比雪夫距离,夹角余弦距离和杰卡德距离等。设 和是样本空间里的两个样本点,其分量分别如下
(1) 欧几里得距离
欧几里得距离,又叫欧式距离,是生活,研究中最常用的距离公式,用来表示欧式空间里面两个对象的远近程度, 和的欧式距离可以用如下表达式来计算
Kmeans算法默认的就是欧式距离。
(2) 曼哈顿距离
曼哈顿距离也叫出租车距离或者城市距离,常用来刻画网格上面两点之间距离,其表达式如下
(3) 闵可夫斯基距离
稍微复杂的距离公式还有闵可夫斯基距离公式,其表达式如下
可以看到曼哈顿距离是闵科夫斯基距离当q=1的特例,欧几里得距离是闵科夫斯基距离当q=2的特例。
(4) 切比雪夫距离
由上式可以看到切比雪夫距离是闵科夫斯基距离的q趋向无穷大的极限形式,如果 和某些个分量差距很大,用切比雪夫距离有天然优势。
(5) 夹角余弦距离
如果把两个样本看成向量的话,可以计算向量之间的夹角,于是有了夹角余弦距离,一般的,如果夹角越小,相似度越高,反之,相似度越小,其表达式如下
夹角余弦距离常用来刻画文本相似度。
(6) 杰卡德距离
如果是两个集合,不关心集合里面具体元素,还可以用杰卡德距离,先介绍杰卡德相似系数,假设现有集合A和集合B, 其杰卡德相似系数公式如下
杰卡德相似系数表示两个集合的交的元素占两个集合的并的元素的比例,特别的,A与B完全相同,则,则J(A,B)=1
而杰卡德距离是在杰卡德系数的基础上再进一步加工
dist(A,B)表示A与B之间的距离,距离越小,相似度越高,反之,相似度越低。
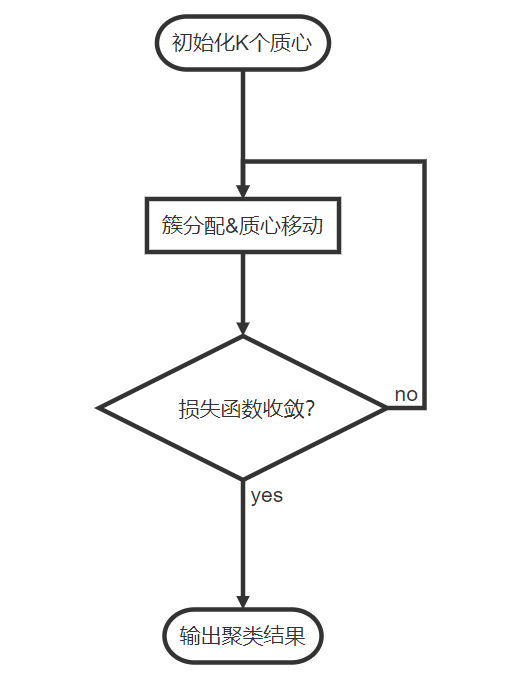
Kmeans算法流程
Kmeans算法包括簇分配和质心移动两个基本步骤,具体的
(1)初始化K个质心;
(2)计算每个样本到K个质心的距离,把每个样本分配予最近的质心,完成簇分配,记录此时每个样本的簇标签和整体损失函数;
(3)重新计算每一簇的质心,移动质心,同时,计算此时的整体损失函数;
(4)如果(3)的整体损失函数比(2)的整体损失函数小,重复第二步第三步,直到整体损失函数不再下降为止;
Kmeans算法流程如下
Kmeans实践
我们以吴恩达机器学习第七次作业为例子来进行实践,详细具体的掌握Kmeans算法。
读取数据并可视化
原始数据能够可视化的尽量可视化,原始数据可视化最大的好处就是非常直观的看到数据分布,猜到最佳聚类的数目和最后的大致效果。
import math
import numpy as np
import pandas as pd
import scipy.io as scio
import matplotlib.pyplot as plt
#数据可视化
data = scio.loadmat("D:\项目\机器学习\吴恩达机器学习课件\CourseraML\ex7\data\ex7data2.mat") #读取数据
X = data["X"] #50*2维数组
plt.figure(figsize=(6,4)) #新建画布
plt.scatter(X[:,0], X[:,1]) #散点图
plt.xlabel("X1")
plt.ylabel("X2")
plt.show()

由于原来的数据是mat格式的,这里我们要用scipy模块io类的loadmat函数读取数据,查看数据基础信息,发现数据主体 X 其实是一个50*2维的数组,只有2个特征,那么可以用matplotlib模块可视化,从样本的散点图能够非常直观的看到最佳的聚类数目为 3。
簇分配和质心移动
利用散点图知道聚多少类之后,就有的非常关键参数K,接下来要做的就是严格按照Kmeans算法流程中的簇分配和质心移动。
初始化K个质心
实践表明第一步K个质心的选择好坏直接关系到最终的收敛效果和收敛步数,在初始质心的选择上面有两个关键因素需要考虑
一个是随机性
随机性是指初始质心的选择可以有很多种可能,可以是原样本点,也可以是非原样本点,一般选择原样本点比较好。
一个是离散性
虽然随机性可以让初始质心有很多种选择,但是质心又有牵引的作用,为保障最终收敛效果和收敛步数,初始质心还应该尽可能离散。
initial_centroids = X[np.random.permutation(len(X))[0:K],:] #随机取K个样本作为初始质心
这行代码是将原样本空间随机打乱再取打乱后样本空间的前面K个,相当于从原样本空间随机抽取了K个样本。
把每个样本分配予最近的质心
有了初始K个质心,就可以计算每一个样本到这些质心的距离,这样每个样本就会产生K个距离,可以比较这K个距离的大小,选出最小距离对应的那个质心,并将该样本划归到这个质心簇里,并标记该样本的所属的簇号,这样每个样本也有了一个簇标签,完成了第一轮簇分配。
def find_closet_centroids(myX, my_init_centroids): #给出初始聚类中心点,计算每个样本到中心点的距离并划分类
m = myX.shape[0] #样本数
K = my_init_centroids.shape[0] #聚类个数
idx = np.zeros([m, 1]) #用来存放簇中心
for i in range(m): #对每一个样本循环
distance = [] #用来存放距离,每一个样本有k个距离
for j in range(K):
#print(myX[i,:], centeriods[j,:], myX[i,:] - centeriods[j, :])
dist = np.linalg.norm(myX[i,:] - my_init_centroids[j,:]) #每个样本都有k个距离,二阶范数即欧氏距离
distance.append(dist)
idx[i] = np.argmin(distance) #k个距离中取最小的
return idx
重新计算每一簇的质心,移动质心
每个样本都有了自己所属的簇标签后,就可以重新计算该簇的质心,一般以该簇的算术平均值作为新的质心,该簇的质心移动到新的质心上。
def compute_centroids(myX, myidx, K): #重新计算簇中心
m = myX.shape[0] #样本数
n = myX.shape[-1] #特征数
centroids = np.zeros((K, n)) #簇*特征数,如同前面的initial_centroids
counts = np.zeros((K, n)) #簇*特征数,用来存放各簇的样本数
for i in range(m):
centroids[int(myidx[i])] += myX[i] #簇求和
counts[int(myidx[i])] +=1 #簇计数
new_centroids = centroids/counts #簇平均值
return new_centroids
判定移动质心是否对结果提升
在评价质心的移动对聚类结果是否有提升需要一个评价尺度,也就是要设计一个整体损失函数来刻画每一步的操作是否对结果是否有提升,如果有提升,那么就沿着这个方向继续进行下去,如果没有提升就要考虑停下来,或者转变方向。在设计整体损失函数时候,需要考虑样本情况,也需要质心情况,以及前后可对比性。Kmeans聚类算法的整体损失函数可以设计成
其中, 代表样本 被分配的簇标签,,代表被分配簇标签所对应的质心。整体损失函数是一个收敛函数,如果下一轮算出的值比上一轮的值小,说明质心的移动确对结果有所提升,反之,质心移动没有对结果提升,达到收敛状态。
def cost(myX, myidx, centroids): #计算损失函数
cost_value = 0
for i in range(len(myX)):
cost_value += np.sum((myX[i] - centroids[int(myidx[i])])**2)
cost_value /= len(myX) #整体损失值
return cost_value
直至收敛
有了前面几小步的准备工作,现在要做的就是将其封装起来,给出整体损失函数,并设置收敛条件让其一步一步的去进行簇分配和质心移动工作,直至收敛为止。
def run_kmeans(myX, K): #在样本上运行kmeans算法
m = myX.shape[0] #样本数
n = myX.shape[1] #特征数
centroids = [] #用来存放每一步的簇中心
cost_values = [] #用来存放每一步的整体损失值
initial_centroids = myX[np.random.permutation(m)[0:K],:] #随机取K个样本作为初始中心点
centroids.append(initial_centroids) #把初始中心点追加进去
initial_idx = find_closet_centroids(myX, initial_centroids) #计算每个样本到中心点的距离,并返回类别标签
initial_cost_value = cost(myX, initial_idx, initial_centroids) #计算第一次的整体损失函数
cost_values.append(initial_cost_value) #把第一次整体损失函数追加进去
new_centroids = compute_centroids(myX, initial_idx, K) #重新计算聚类中心
centroids.append(new_centroids) #把新的聚类中心追加进去
new_cost_value = cost(myX, initial_idx, new_centroids) #重新计算整体损失函数,此时只是质心改变,类别标签并没改变
cost_values.append(new_cost_value) #把新损失函数值追加进去
while cost_values[-2]>cost_values[-1]: #判定损失函数值是否降低
idx = find_closet_centroids(myX, centroids[-1]) #以新的质心进行簇分配
centroid = compute_centroids(myX, idx, K)
cost_value = cost(myX, idx, centroid)
centroids.append(centroid)
cost_values.append(cost_value)
return idx, centroids, cost_values
聚类过程可视化
虽然前面实现了聚类模型,如果能够将聚类过程可视化呈现一定是锦上添花,更加能够明白聚类原理。
质心分割
由于之前的质心是以数组统一保存起来,但是在绘制质心移动轨迹的时候并不好用,所以需要做一个质心分割工作,简单的来说就是将所有质心分成K组,代表K个簇,每一组都有迭代次数个质心点坐标, 这样每一簇的质心移动就清晰了
def centroid_split(mycentroids, K): #将所有中心点分簇
step = len(mycentroids) #收敛步数
cluster_center = []#用来存放各簇的中心点坐标
for k in range(K):
for i in range(step):
cluster_center.append(tuple(mycentroids[i][k]))
cluster_center_k = [cluster_center[i:i+step] for i in range(0, len(cluster_center), step) ] #每簇的簇中心点坐标
return cluster_center_k
质心移动轨迹和簇分布
这一部分需要将最后收敛状态下每簇的样本分布区分开来,并且把各簇的质心移动轨迹绘制出来
def visual_Kmeans(myX, K): #可视化Kmeans过程
plt.figure(figsize=(6,4)) #新建画布
plt.subplot(1,2,1) #第一个子图
plt.xlabel("X1")
plt.ylabel("X2")
idx, centroids, cost_values = run_kmeans(myX, K)
plt.scatter(myX[:,0], myX[:,1], c = idx) #根据idx标签绘制各簇散点图
cluster_center = centroid_split(centroids, K) #中心点分簇
for k in range(K): #绘制K个簇中心移动轨迹
centroid_x = [] #用来存放每簇的中心点的每一步的x1值
centroid_y = [] #用来存放每簇的中心点的每一步的x2值
cluster_xy = cluster_center[k]
for s in range(len(cluster_xy)):
centroid_x.append(cluster_xy[s][0])
centroid_y.append(cluster_xy[s][1])
plt.plot(centroid_x, centroid_y, '-->' , linewidth = 0.7)
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.3, hspace=0.2) #调整子图间距
plt.subplot(1,2,2) #第二个子图
plt.plot([i for i in range(len(cost_values))], cost_values) #损失函数折线图
plt.xlabel("iteration")
plt.ylabel("cost")
plt.show()
Kmeans算法优缺点分析
优点
(1) 适用性强
很多未知特性的数据集都可以先用K-means去试试,探索数据内在结构。
(2) 过程简单
缺点
Kmeans聚类算法的缺点也很明显,如
(1) 需要事先知道聚类数目;
参数K作为一个输入参数,是在聚类之前就要根据业务或者经验来确定;
(2) 初始质心选择影响很大;
因为初始质心选择上要具备随机性,存在一些不确定因素,并不能保证每一次初始化聚类操作都能开始于一个合适的状态,不恰当的初始质心可能使得损失函数在聚类过程中陷入局部最小值,达不到全局最优的状态,下图是多次初始质心选择聚类结果和损失函数收敛情况。
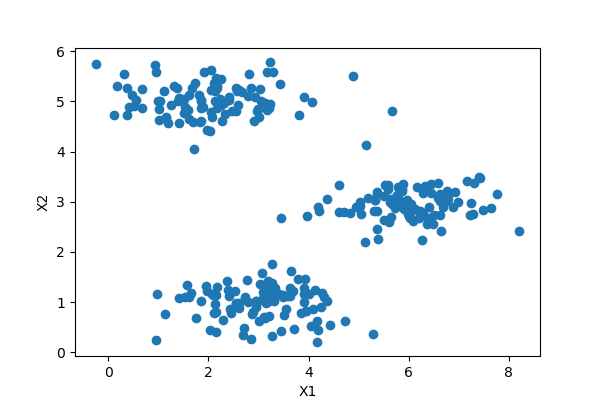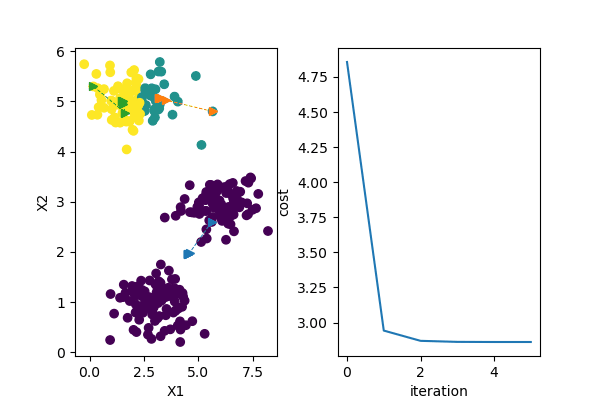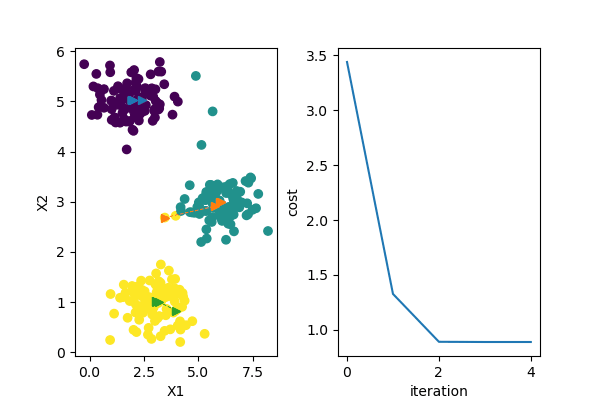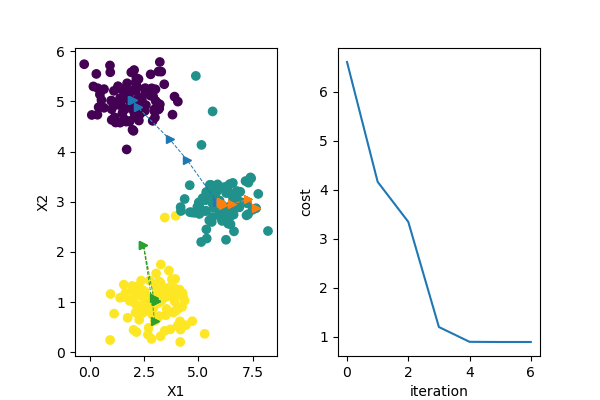
从上图可以看到前3次聚类并没有达到全局最优化,这正是因为初始质心的选择不当导致的。
Kmeans算法应用场景
Kmeans聚类算法的应用场景很多,凡是一些不带标签的数据需要聚类的都可以用Kmeans算法试一试。这里重点介绍一下Kmeans在反欺诈领域的应用,在反欺诈领域经常利用过往欺诈性索赔的黑数据,根据数据的相似性来提炼欺诈方式和欺诈模式,还可以识别新的欺诈行为。
参考文献
1, permutation用法
https://blog.csdn.net/ljyljyok/article/details/102929918
2, 调整子图间距
https://blog.csdn.net/zengbowengood/article/details/103279583
3, 多张静态图变成动图imageio
https://blog.csdn.net/zengbowengood/article/details/109336369
- - -The end- - -
交流群限时免费,入口见菜单栏
三行科创微信公众号欢迎投稿
稿件聚焦数学逻辑,数学工程,数学文化等领域
一经采用,我们将奉上酬劳
投稿邮箱:sanhang_kc@163.com
商务合作:17521754388

