




一、数据集

数据是这样的:




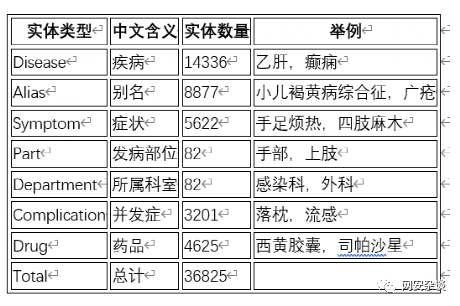
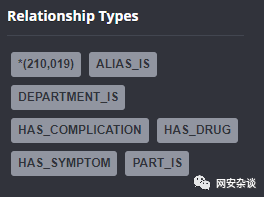
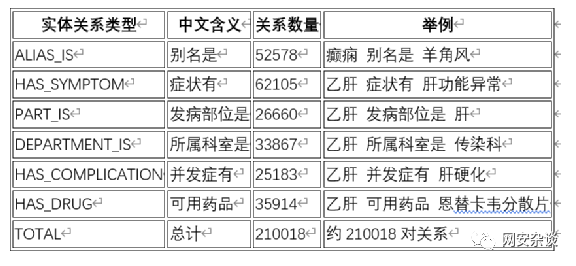

基于特征词分类的方法来识别用户查询意图,当然它也不是很智能
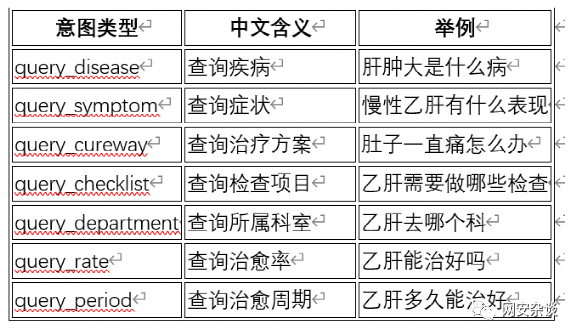
它的回答也确实很让人头疼呀。

二、导入数据代码
先回顾下项目的代码结构
data:存放数据
img:存放readme里的图片
model:存放训练好的tfidf模型和意图识别模型
build_graph.py:构建图,详见task03
entity_extractor.py:抽取问句中的实体和识别意图,详见task04
search_answer.py:根据不同的实体和意图构造cypher查询语句,查询图数据库并返回答案,详见task05
那我们今天的任务就是分析build_grapy.py
主程序非常简洁
if __name__ == "__main__":
handler = MedicalGraph()
handler.create_graphNodes()
handler.create_graphRels()
看来就主要是MedicalGraph()这个主体类。类的结构如下:
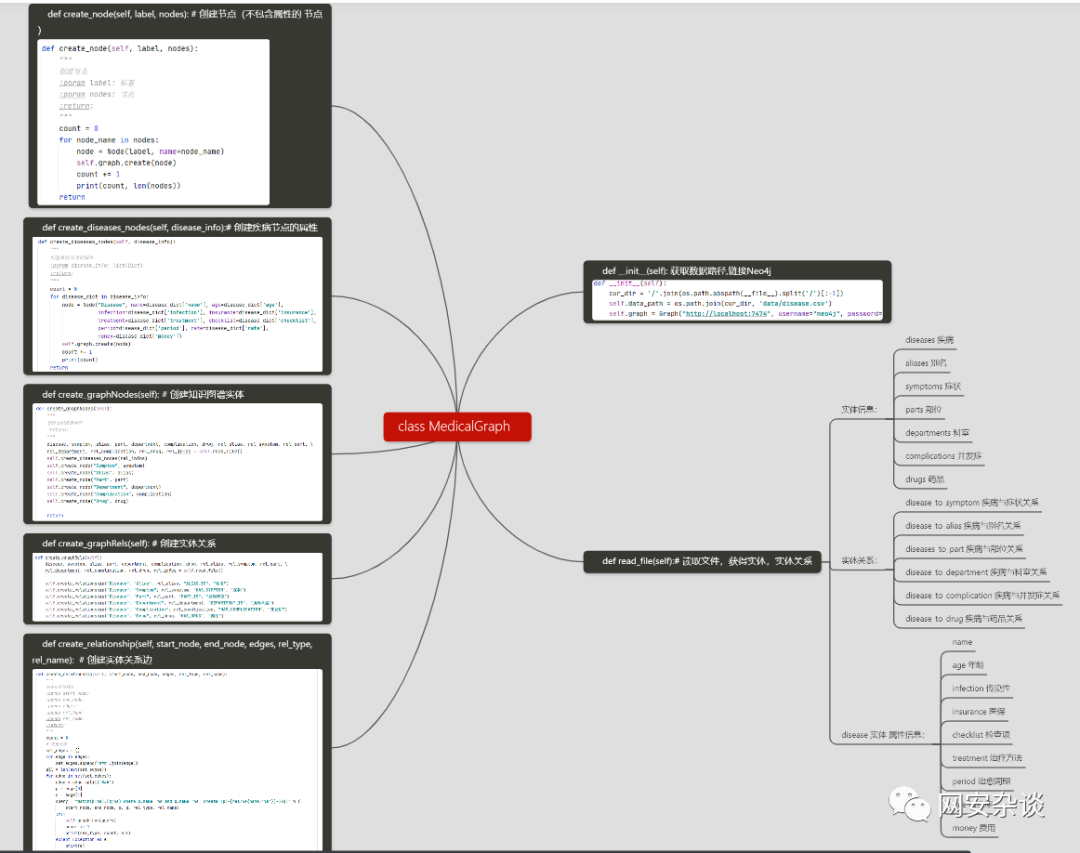
复制
分析read_file代码:
复制
def read_file(self):"""读取文件,获得实体,实体关系:return:"""# cols = ["name", "alias", "part", "age", "infection", "insurance", "department", "checklist", "symptom",# "complication", "treatment", "drug", "period", "rate", "money"]# 实体diseases = [] # 疾病aliases = [] # 别名symptoms = [] # 症状parts = [] # 部位departments = [] # 科室complications = [] # 并发症drugs = [] # 药品# 疾病的属性:age, infection, insurance, checklist, treatment, period, rate, moneydiseases_infos = []# 关系disease_to_symptom = [] # 疾病与症状关系disease_to_alias = [] # 疾病与别名关系diseases_to_part = [] # 疾病与部位关系disease_to_department = [] # 疾病与科室关系disease_to_complication = [] # 疾病与并发症关系disease_to_drug = [] # 疾病与药品关系all_data = pd.read_csv(self.data_path, encoding='gb18030').loc[:, :].valuesfor data in all_data:disease_dict = {} # 疾病信息# 疾病disease = str(data[0]).replace("...", " ").strip()disease_dict["name"] = disease# 别名line = re.sub("[,、;,.;]", " ", str(data[1])) if str(data[1]) else "未知"for alias in line.strip().split():aliases.append(alias)disease_to_alias.append([disease, alias])# 部位part_list = str(data[2]).strip().split() if str(data[2]) else "未知"for part in part_list:parts.append(part)diseases_to_part.append([disease, part])# 年龄age = str(data[3]).strip()disease_dict["age"] = age# 传染性infect = str(data[4]).strip()disease_dict["infection"] = infect# 医保insurance = str(data[5]).strip()disease_dict["insurance"] = insurance# 科室department_list = str(data[6]).strip().split()for department in department_list:departments.append(department)disease_to_department.append([disease, department])# 检查项check = str(data[7]).strip()disease_dict["checklist"] = check# 症状symptom_list = str(data[8]).replace("...", " ").strip().split()[:-1]for symptom in symptom_list:symptoms.append(symptom)disease_to_symptom.append([disease, symptom])# 并发症complication_list = str(data[9]).strip().split()[:-1] if str(data[9]) else "未知"for complication in complication_list:complications.append(complication)disease_to_complication.append([disease, complication])# 治疗方法treat = str(data[10]).strip()[:-4]disease_dict["treatment"] = treat# 药品drug_string = str(data[11]).replace("...", " ").strip()for drug in drug_string.split()[:-1]:drugs.append(drug)disease_to_drug.append([disease, drug])# 治愈周期period = str(data[12]).strip()disease_dict["period"] = period# 治愈率rate = str(data[13]).strip()disease_dict["rate"] = rate# 费用money = str(data[14]).strip() if str(data[14]) else "未知"disease_dict["money"] = moneydiseases_infos.append(disease_dict)return set(diseases), set(symptoms), set(aliases), set(parts), set(departments), set(complications), \set(drugs), disease_to_alias, disease_to_symptom, diseases_to_part, disease_to_department, \disease_to_complication, disease_to_drug, diseases_infos
复制

复制
文章转载自网安杂谈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1195次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
872次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
683次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
584次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
573次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
556次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
489次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
465次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
458次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
352次阅读
2025-04-18 10:01:22
