






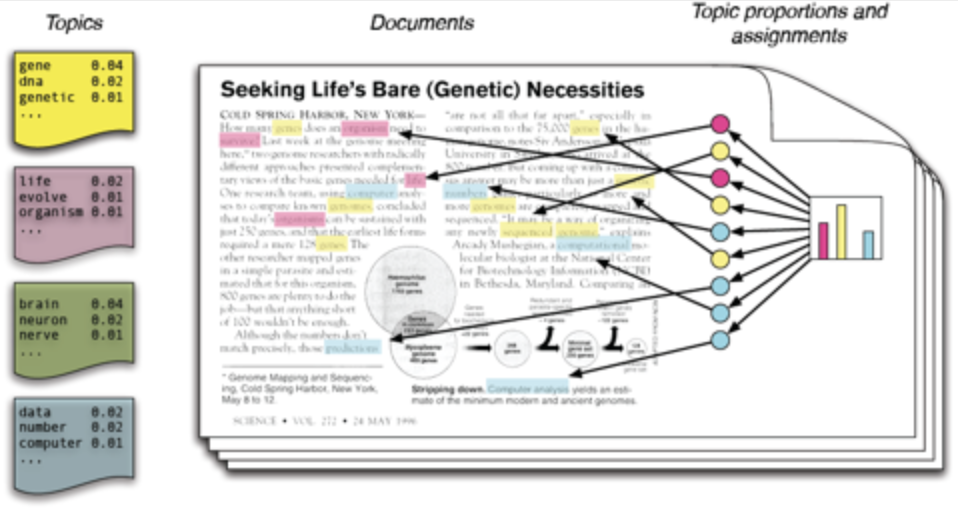

隐含狄利克雷分布LDA
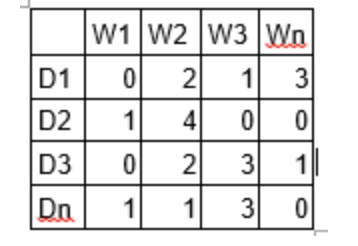
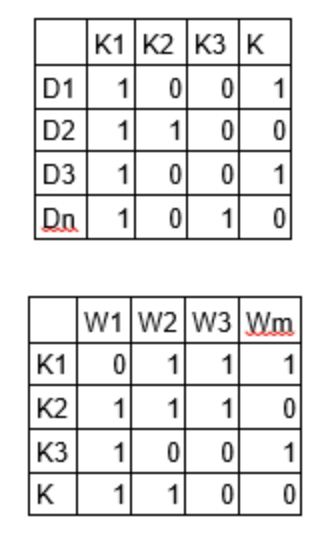
LDA的两个参数:Alpha和Beta超参数
LDA的收敛点
使用单词包的LDA应用
import pandas as pddata = pd.read_csv('abcnews-date-text.csv', error_bad_lines=False)data_text = data[['headline_text']]data_text['index'] = data_text.indexdocuments = data_text复制
print(len(documents))print(documents[:5])复制

#Loading gensim and nltk librariesimport gensimfrom gensim.utils import simple_preprocessfrom gensim.parsing.preprocessing import STOPWORDSfrom nltk.stem import WordNetLemmatizer, SnowballStemmerfrom nltk.stem.porter import *import numpy as npnp.random.seed(2018)import nltknltk.download('wordnet')复制
def lemmatize_stemming(text):return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))def preprocess(text):result = []for token in gensim.utils.simple_preprocess(text):if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:result.append(lemmatize_stemming(token))return result复制
doc_sample = documents[documents['index'] == 4310].values[0][0]print('original document: ')words = []for word in doc_sample.split(' '):words.append(word)print(words)print('\n\n tokenized and lemmatized document: ')print(preprocess(doc_sample))复制

processed_docs = documents['headline_text'].map(preprocess)processed_docs[:10]复制

dictionary = gensim.corpora.Dictionary(processed_docs)count = 0for k, v in dictionary.iteritems():print(k, v)count += 1if count > 10:break复制

dictionary.filter_extremes(no_below=15, no_above=0.5, keep_n=100000)复制
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]bow_corpus[4310]复制
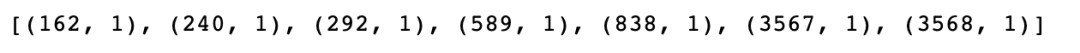
bow_doc_4310 = bow_corpus[4310]for i in range(len(bow_doc_4310)):print("Word {} (\"{}\") appears {} time.".format(bow_doc_4310[i][0], dictionary[bow_doc_4310[i][0]], bow_doc_4310[i][1]))复制

lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics=10, id2word=dictionary, passes=2, workers=2)for idx, topic in lda_model.print_topics(-1):print('Topic: {} \nWords: {}'.format(idx, topic))复制






长按关注我们

欢迎关注微信公众号“沈浩老师”

文章转载自数艺学苑,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
2480次阅读
2025-04-09 15:33:27
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1144次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
822次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
651次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
568次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
549次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
531次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
457次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
454次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
443次阅读
2025-04-30 12:17:50
