




首先请大家谅解,尤其是消金和财务的同仁,作为服务台的工作很细很碎,你们的问题我正在处理,很快就会上线。

在年前放假的前两天,同业的征征叫住了笔者,指着某票据交易所的界面问道,这上面的数据能不能复制下来。
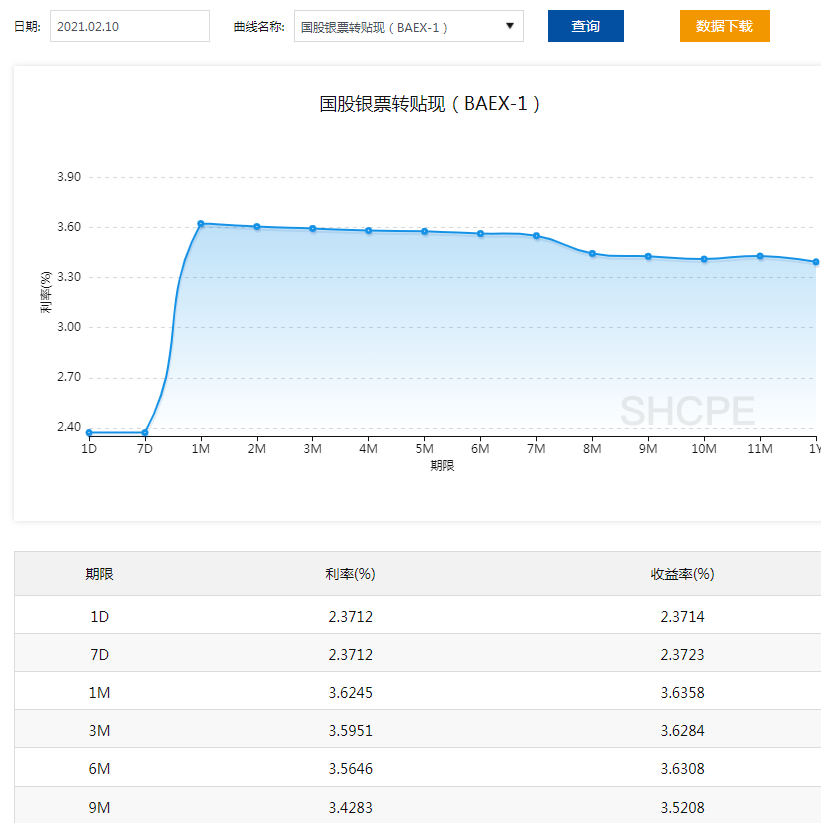
笔者看了一下这个破界面,心里暗道这个不直接可以选中复制,然后粘贴到excel里不就OK,但毕竟是同业部提出来的问题,肯定没那么简单,所以征征指出了一个严肃的问题:

这个网页没有批量导出的功能,也就是说如果他要看一个月的利率或者收益率,需要像个傻子一样依次点击日期,再复制粘贴到表里,2021年第一季度都快过了一半了,怎么还会有这么浪费人力的系统?是可忍,孰不可忍?!
于是笔者研究了一下这个网站,打算写一个爬虫,替同业部节省一点人力资源,不要把宝贵的时间浪费在这种低端工作中。

所谓的爬虫说到底就是哲学的三个终极问题:我是谁?我从哪来?我要去哪?错了,是数据结构是什么样的?数据从哪里获取?数据最后要呈现到什么状态?

首先看数据结构:从图上看,数据非常简单,不同的日期、期限有着不同的利率和收益率,而且只有工作日有数据,节假日与周末没有数据。
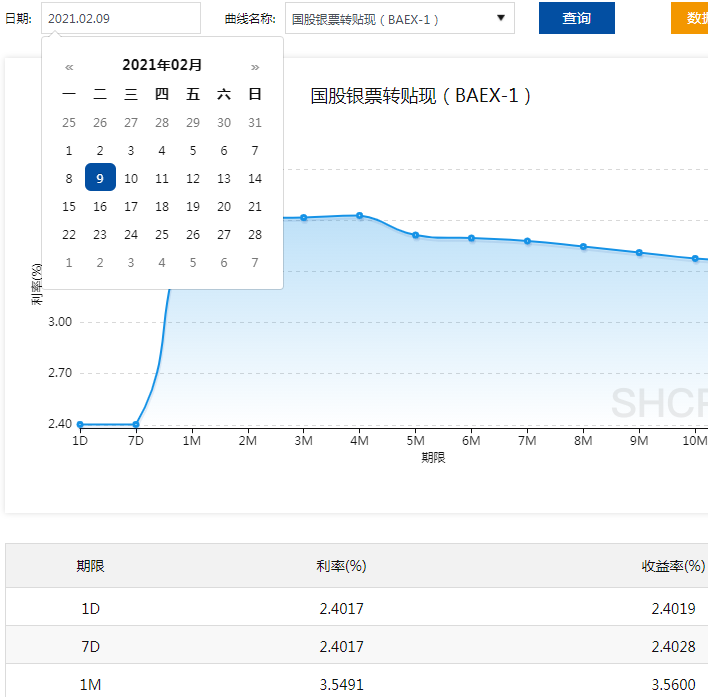
再看数据如何获取?
这个网页是个明显的动态网页,而且有反爬虫机制,使用最简单的urllib库直接就被503拒绝掉,此时有两种方案:方案A,使用selenium库,模拟点击日期,然后复制数据,最后导出。但是这个方法有很大的缺陷,首先是要在电脑上安装高版本的谷歌浏览器(这个不难)和对应的webdriver(这个就有点麻烦了),其次点击时会调用一个谷歌浏览器进程,众所周知谷歌浏览器进程是出了名的吃内存,一旦浏览器卡住(同业的老爷机是必然会被卡住的)就前功尽弃,最重要的是这种模拟点击的方式为了绕过反爬虫机制每次操作不能太快,所以效率低下。

只能使用方案B:使用requests和fake_useragent库伪造成正常用户来获取信息。
说起来简单,干起来也不复杂,只需要导入两个库即可:

然后使用fake_useragent伪造一个正常的head:

然后重点来了,开始分析这个网页,看是如何进行交互的:
打开谷歌浏览器,打开开发者工具,刷新网页,随便查询几个日期,在Network中的XHR仔细观察,发现了端倪:虽然这是个动态网页(我猜用的Ajax),但是是用的POST请求数据,然后服务器返回了一个JSON值。
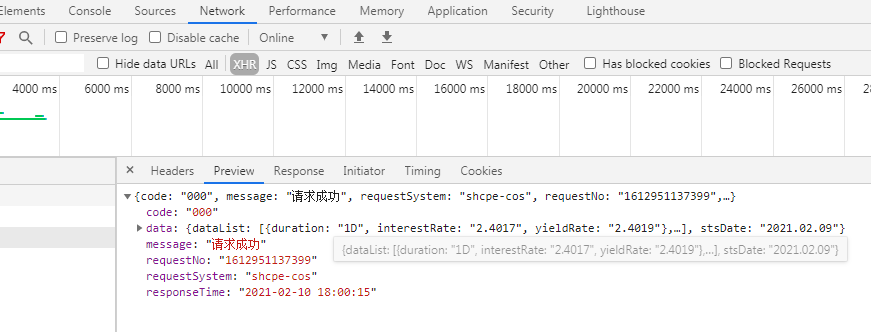
返回的值如下:

这正是我们需要的。
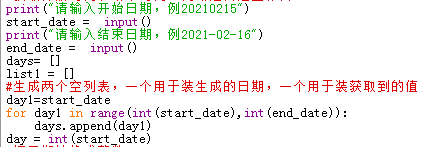
OK,需求分析完毕,正式开始整代码,首先要获取开始日期和结束日期,为了避免无效请求,要排除掉周末,所以做了如下操作:
用户输入开始和结束日期,然后生成每一天,存到一个列表中,再依次读取这个列表中的日期,拼接到伪造的POST请求中。
说起来简单,做起来就有点麻烦,关键在于Python中各种数据类型的转换非常复杂,一点也不像Java严谨(php万岁)。
首先是获取开始和结束日期,然后生成每一天,把每一天添加进循环中(之所以这么干是因为Python的循环看起来简单,用起来复杂,嵌套起来会很可怕,所以干脆拆开循环)
然后使用datetime判断是否为工作日,如果是工作日,就继续:

因为用户输入的是yyyymmdd格式(20210210),但是post请求时yyyy-mm-dd格式,所以需要进行格式转换,先转换成字符串,在提取前四位、中二位、后二位,用横杠连接:
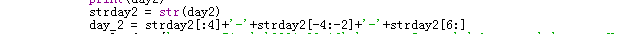
然后把拼接完毕的日期写入payload中,配合伪造的head数据向服务器请求数据:

然后使用 BeautifulSoup和lxml整理数据,再使用看起来很复杂、写起来很复杂但熟悉了以后很简单的正则表达式处理数据:

为了防止太过分,所以加点间隔时间,避免引起对方的警觉:

最后把获取的数据存到dataframe,写入到excel中,搞定!


最后,一个爬虫写了70多行也是醉了。
