Facebook社交平台及其旗下应用Instagram、Oculus和WhatsApp灯停摆超过6小时,造成公司直接损失超过5亿人民币,究竟是什么原因造成的?IT界正热衷于各种猜测,但大多数观察家认为,Facebook的中断原因是一个配置错误的路由器导致整个Facebook的网络出现了错误,这涉及到BGP(Border Gateway Protocol,边界网关协议)的故障,该协议与域名服务器(DNS)合作,将流量导向互联网上的特定IP地址。这一情况也得到了Facebook基础设施副总裁Santosh Janardhan的验证 "......计算设施之间的数据流量是由路由器管理的,路由器会计算出所有传入和传出数据的发送位置。而且......我们的工程师经常需要将部分骨干网断开进行维护...... 结果导致了这次大事故。即在其中一次例行维护工作中,我们发出了一条命令,目的是评估全球骨干网容量的可用性,无意中却关闭了我们骨干网的所有连接,有效地切断了Facebook全球数据中心的连接。虽然Facebook系统设计有命令审计环节、以防止类似的错误,但该审计工具的一个错误没有正确地阻止该命令。......这一变化导致我们的数据中心和互联网之间的服务器连接完全断开。而这种连接的完全丧失造成了第二个问题,使事情变得更糟"。有消息称,由于BGP中断使Facebook IT人员无法进入Facebook园区内的实体建筑,因此中断持续时间较长,因为他们无法获得访问证书。这种情况也得到了 Janardhan的验证:"这些设施的设计考虑到了高水平的物理和系统安全。它们很难进入,而一旦你进去了,硬件和路由器的设计是很难修改的,即使你有物理访问权。"但Janardhan说,没有证据表明存在恶意活动,也没有暴露用户信息。尽管Facebook对此次故障做出了解释,但关于其实际原因的大量、不同的传言却不绝于耳。令人困惑的是:究竟为什么路由器会被错误地配置?如果这是一个无心之失,那么我们由如何能避免这个问题?一些专家将昨天的故障归咎于BGP。毕竟,引发故障的是BGP,而不是DNS服务器。Cloudflare工程总监Celso Martinho和边缘网络技术负责人Tom Strickx在Cloudflare网站的一篇文章中写道:“这本身不是一个DNS问题,但DNS故障是我们看到的Facebook大故障的第一个症状。”还有人说,BGP是一个过时的协议,其时代已经过去。我们在1996年就在使用BGPv4,25年后的今天,我们仍然在使用同样的版本,该协议几乎没有任何重大的改进和发展。一年前的CenturyLink故障也归咎于BGP,该故障导致全球范围内一系列依赖其服务的大型网站崩溃。在那次故障中,一个名为flowspec的BGP功能被错误地配置了。Flowspec负责为互联网上的对等路由器之间重新分配流量,以减轻分布式拒绝服务(DDoS)攻击和其他安全问题。
当然,我们也不能忽视一个奇怪的巧合:在举报人Frances Haugen(一位前Facebook雇员)在全国电视上对Facebook社区网站将利润置于用户安全之上的做法提出批评后,促使世界各地的政治家对Facebook进行批评之时,甚至Haugen当天在向美国参议院小组委员会作证的时候,Facebook系统就崩溃了。
这次故障背后是否有任何违规行为可能永远不会清楚。"我们不知道Facebook和它的其他财产是如何或为什么持续中断的,但这些变化一定是来自公司内部,因为Facebook在内部管理这些记录。在这一点上,任何人都无法猜测这些改变是恶意的还是意外的。" 因为Facebook不会让我们知道它们是如何运营这些网络的。
2. 那么,DNS服务是罪魁祸首吗?
至少,前所未有的中断时间应被视为一个迹象,表明该问题超出了简单的DNS服务中断,而是发生了一些重大事件,不仅使他们的内部DNS服务瘫痪,而且使支持互联网上流量最大的网站的高度复杂的网络运营团队无法在短时间内解决这个问题。
DNS是到达互联网上任何网站的第一步。它的失败将阻止一个网站的访问性,即使网站本身和它所承载的基础设施是可用的。在Facebook的案例中,他们在内部托管其DNS名称服务器,为其域名存储权威性记录。Facebook维护着四个名称服务器(每个都由许多物理服务器提供服务)--a、b、c和d,如图1所示。
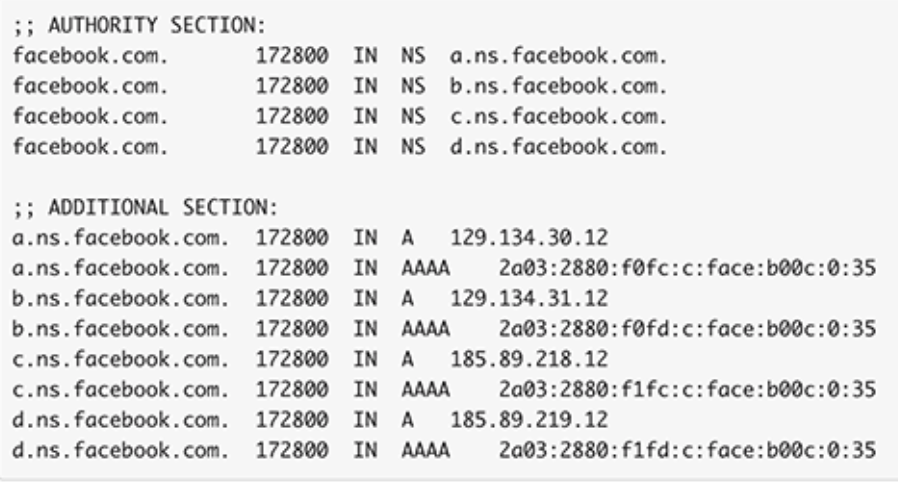
图1-Facebook-nameservers-IPv4-IPv6
这些命名服务器中的每一个都由不同的IP前缀,或互联网 "路由"(后面会详细介绍)覆盖,涵盖了一系列的IP地址。
大约在UTC时间15:40,Facebook的服务开始下线,因为用户无法通过DNS将其域名解析为IP地址。

图2. 由于DNS错误,对facebook.com的访问失败了
当这种情况发生时,可以看到,由于Facebook的名字服务器变得不可达,通过DNS层次查询facebook.com的A记录也失败了(见图3)。
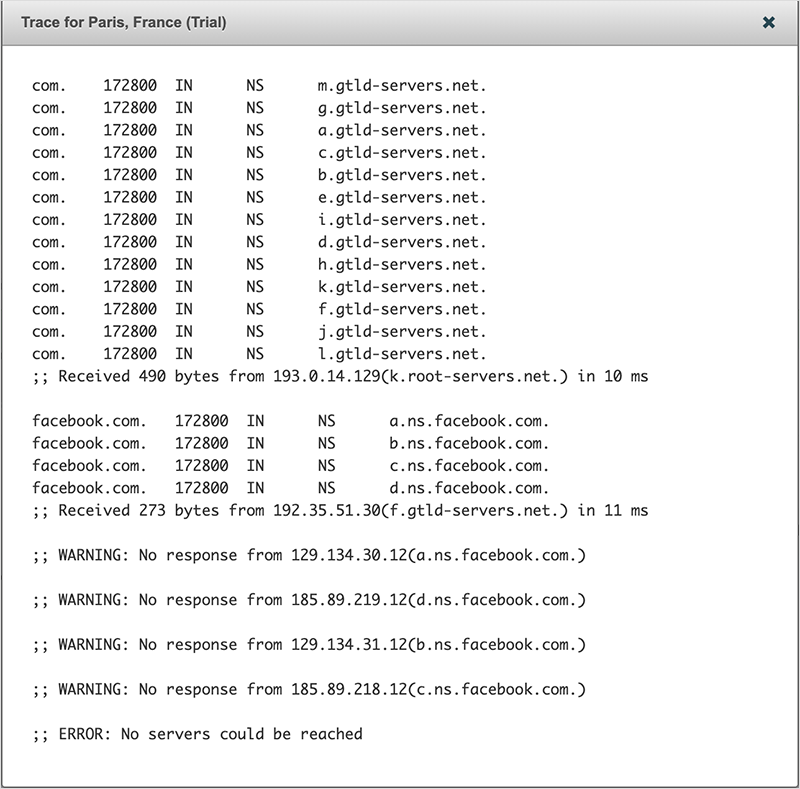
图3. 由于命名服务器无反应,DNS跟踪测试失败
DNS对于网站和网络应用的可及性是如此关键,以至于大多数主要的服务提供商都不会乱用它。例如,亚马逊虽然自己是顶级公共云供应商之一,AWS也提供DNS服务,但不在自己的基础设施上而是在两个独立的外部DNS服务(Oracle的Dyn和Neustar的UltraDNS)上为amazon.com存储权威的DNS记录。
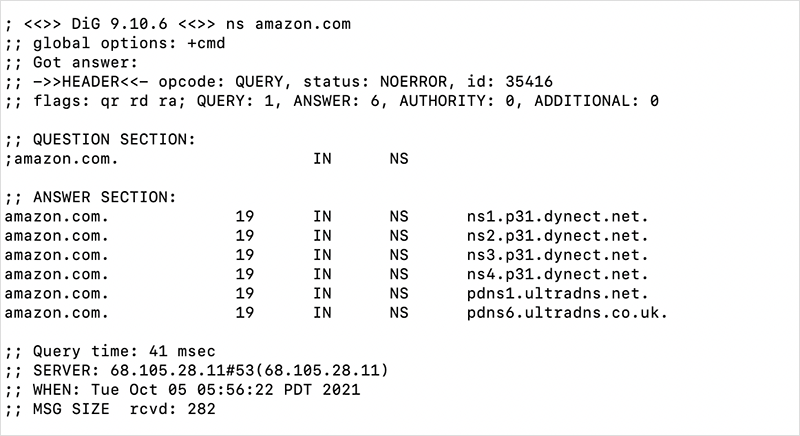
图4. 第三方DNS服务托管的Amazon.com域名记录
亚马逊不仅使用外部服务来托管其记录,而且值得注意的是:它使用了两个供应商。为什么这一点值得注意?作为一个重要的互联网基础设施,DNS已经臭名昭著地成为恶意行为者的攻击目标,如2016年对Dyn的大规模DDoS攻击或2018年对亚马逊的DNS服务Route 53的路由劫持事件。通过使用两个不同的供应商托管,也就是有了灾备,即使其中一个供应商因任何原因不可用,亚马逊可以确保其网站可以访问。
3. 为什么Facebook不将其DNS记录转移到外部DNS服务商,让其服务重新上线?
由顶级域名(TLD)服务器(在这种情况下,com.TLD)提供服务的DNS名称服务器记录可以是长期的记录——鉴于应用程序和网站运营商不经常移动他们的记录,这是有道理的。不像A和AAAA记录,主要网站的记录经常变化非常频繁,因为DNS可以用来平衡整个应用程序基础设施的流量,并将用户指向最佳的服务器以获得最佳体验。就Facebook而言,其DNS名称服务器记录有两天的保存期限(见图5),这意味着即使将记录转移到外部服务,一些用户有可能需要两天时间才能到达Facebook,因为原来的名称服务器记录将继续在互联网的某些地方存在,直到过期。
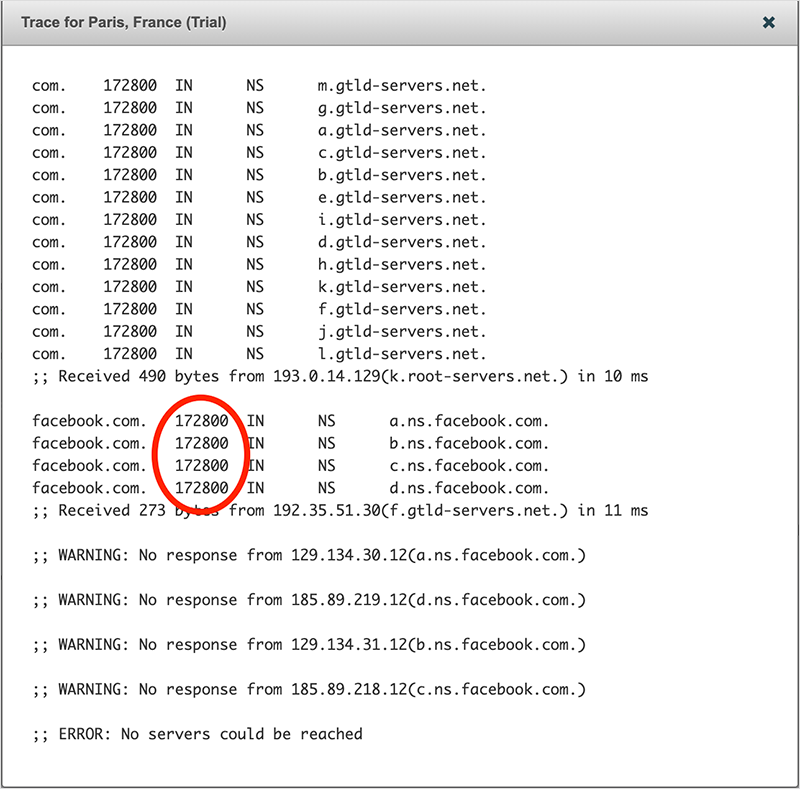
图5. Facebook的名字服务器记录有172800秒(48小时)的到期时间因此,在事件开始后转移到二级供应商并不是Facebook解决这个问题的实际选择。最好是集中精力让服务恢复正常。4. 为什么Facebook的内部DNS服务一开始就出现了问题?在故障发生的前一刻,Facebook发布了一系列的BGP路由撤销(几乎都是立即撤销的),涵盖了其数百个前缀,这实际上是将其DNS名称服务器从互联网上移除。根据互联网服务提供商在互联网上的位置,它们几乎立即或在10分钟后看到这些路由变化。虽然大多数被撤销的路由被重新公布,但那些涵盖其DNS名称服务器的路由却没有(有一个例外)。在中断之前,有7个(IPv4)前缀覆盖其内部的DNS服务被大量广播。
上面的关键路由是/24那些路由,因为这些路由更具体,会被优先考虑。/23路由是/24路由的保护伞或 "覆盖 "。最后,/17路由是Facebook的名称服务器'a'和'b'的覆盖路由,覆盖了129.134.30.0/23、129.134.30.0/24和129.134.31.0/24等路由。所有这些都在UTC 15:39左右从全球路由表中消失了,除了/17(后面会有更多的介绍)。为了说明从互联网服务提供商和中转提供商的角度来看,这次中断是如何发生的,他们将用户流量导向Facebook,我们对Cogent公司的路由表进行了快照,它在10月4日12:00 UTC和16:00 UTC的中断前是这样的。Facebook在12:00 UTC有309个前缀广告,在16:00 UTC有259个前缀。只有以下前缀是 "失踪 "的。129.134.25.0/24
129.134.26.0/24
129.134.27.0/24
129.134.28.0/24
129.134.29.0/24
129.134.30.0/23
129.134.30.0/24
129.134.31.0/24
129.134.65.0/24
129.134.66.0/24
129.134.67.0/24
129.134.68.0/24
129.134.69.0/24
129.134.70.0/24
129.134.71.0/24
129.134.72.0/24
129.134.73.0/24
129.134.74.0/24
129.134.75.0/24
129.134.76.0/24
129.134.79.0/24
157.240.207.0/24
185.89.218.0/23
185.89.218.0/24
185.89.219.0/24
2a03:2880:f0fc::/47
2a03:2880:f0fc::/48
2a03:2880:f0fd::/48
2a03:2880:f0ff::/48
2a03:2880:f1fc::/47
2a03:2880:f1fc::/48
2a03:2880:f1fd::/48
2a03:2880:f1ff::/48
2a03:2880:f2ff::/48
2a03:2880:ff08::/48
2a03:2880:ff09::/48
2a03:2880:ff0a::/48
2a03:2880:ff0b::/48
2a03:2880:ff0c::/48
2a03:2881:4000::/48
2a03:2881:4001::/48
2a03:2881:4002::/48
2a03:2881:4004::/48
2a03:2881:4006::/48
2a03:2881:4007::/48
2a03:2881:4009::/48
69.171.250.0/24 |
所有这些前缀都覆盖了Facebook的名字服务器,只有最后一个例外。图6显示了以名字服务器'c'为目的地的流量被第一跳互联网放弃了,因为服务提供商在其路由表中没有路由,无法将流量送到目的地。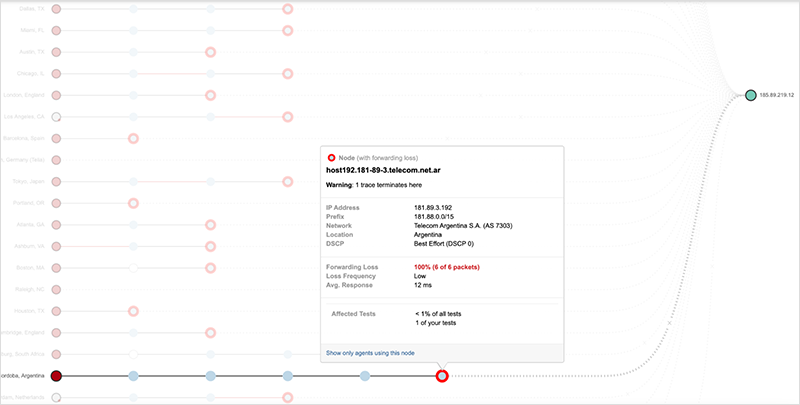
图6. 前往Facebook名称服务器的流量在第一跳互联网上被丢弃覆盖Facebook 50%的DNS的/17前缀仍在广播中,并在服务提供商的路由表中,但如图8所示,通过该路由指向Facebook名称服务器'a'的所有流量在Facebook的边缘被丢弃。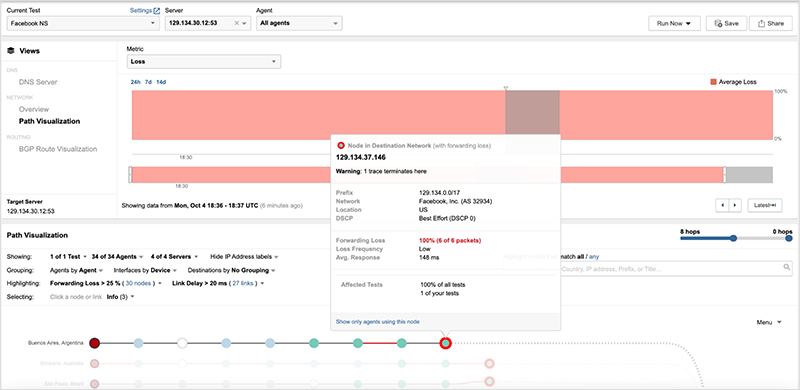
图7. 在Facebook网络边缘路由器的DNS流量被丢弃这个广告路由失败的原因可能是它没有被设置为处理到DNS服务的流量(因为在停电之前,/23和更重要的是,/24s被积极使用)--或者它可能表明Facebook的网络有问题,也许阻止流量在内部路由。在2019年谷歌网络的一次重大故障中也出现了类似的行为。在该事件中,BGP广告继续将流量路由到他们的网络,但流量在谷歌的网络边缘下降,因为他们的内部网络被禁用,边界路由器没有内部路由来发送流量到目标服务器。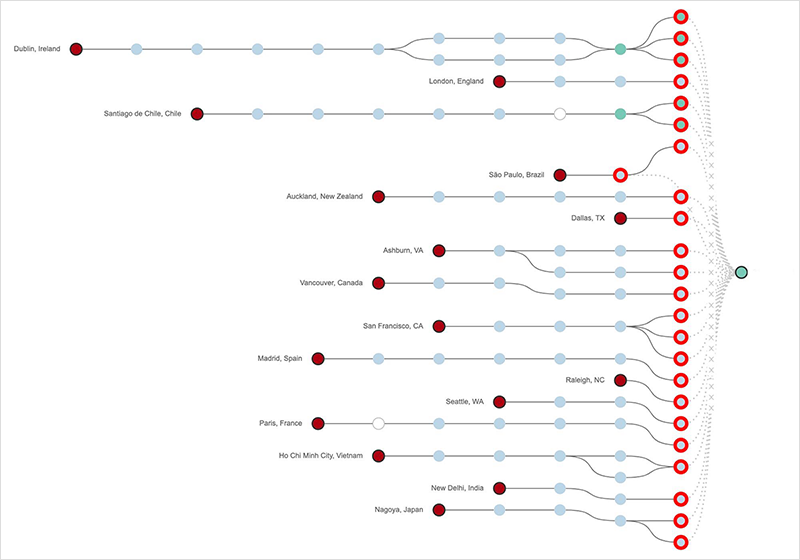
图8. 2019年事件中,谷歌网络边缘的所有流量下降最后,为了更全面地了解Facebook的网络状况,让我们看看被撤销的路由列表中的最后一个前缀,即69.171.250.0/24,它是facebook.com的众多前缀中的一个。这个路由并没有像DNS前缀那样被撤销。图9显示了该前缀在整个停电期间的重大和持续的路由跳动的影响,实际上使该路由无法使用。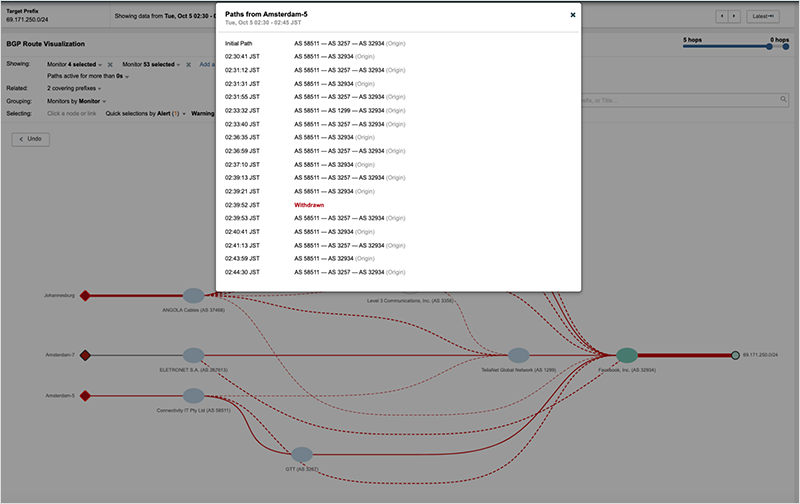
图9. 观察到69.171.250.0/24前缀的连续路由跳动 这个路由不稳定的情况被保留了这么久,也许说明了DNS服务以外的东西出了问题,即BGP出了问题。5. 为什么Facebook一开始就撤销了其服务的路由?虽然我们不知道引发这一事件的配置更新的具体原因,但路由的撤销和改变并不罕见。BGP不仅仅是流量在互联网上被路由的方式。它也是网络运营商塑造通往其服务的流量的强大工具。在高流量网络的运行过程中,BGP变更是正常的操作。原因包括对服务进行修改(例如,将流量路由到不同的前缀,以对服务的某些部分进行维护)、为用户优化性能的流量工程、改变对等者、改变对等关系的性质,以及其他操作活动。路由也可能由于网络配置更新出错、路由器错误或为单个对等体的变化被广泛推送而意外地被撤销。6. 为什么Facebook在七个多小时内无法恢复其服务的路由?即使DNS是推倒这一切的多米诺骨牌,即使一组无赖的BGP撤消是推倒的源头,就像任何BGP路由变化一样,它可以再次被改变。但历史告诉我们,持续时间最长、破坏性最大的故障往往是由控制平面的一些问题造成的。不管是由于人为错误还是错误,如果网络运营商控制网络的机制(对其进行修改造成的)被破坏或切断,这时事情就会变得非常非常糟糕。就拿谷歌停电事件来说。在那次持续了大约四个小时的事件中,一次维护操作无意中关闭了谷歌网络中一个区域的所有网络控制器。没有了控制器,网络基础设施实际上是无头的,无法对流量进行路由。谷歌的网络工程师无法迅速恢复网络,因为他们对网络控制器的访问取决于被关闭的网络。缺乏对网络管理系统的访问肯定会阻止Facebook回滚任何有问题的变化。访问可能是由于一些网络变化,而这些变化是导致中断的原始路由撤销的一部分,也可能是由于服务依赖性(例如,如果他们的内部DNS是访问认证服务或其他关键系统的依赖性)。值得注意的是,在DNS瘫痪之前就观察到了连接问题(见图10)。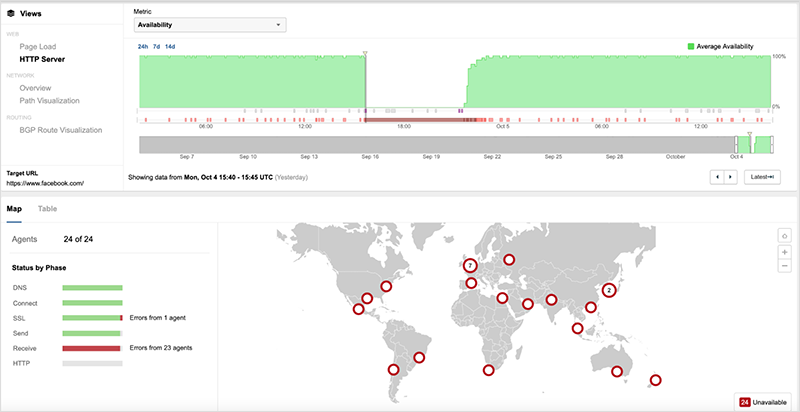
除了数以百万计的用户受到影响外,关于服务提供商问题的报告在故障期间也比比皆是。互联网服务供应商和中转供应商会在几个方面受到影响。首先,Facebook占了大量的互联网流量--所有对其DNS服务器的查询都会被供应商放弃,因为他们没有通往该服务的路线。同时,更多的DNS查询(以及网络流量)会冲击DNS供应商(和ISP),因为DNS本身是有弹性的,当对一个名字服务器的查询失败时,DNS解析器会尝试其他名字服务器--但没有用。通常情况下是一个单一的查询,在中断期间会翻两番。更不用说那些因焦急的用户试图到达网站而产生的浏览器刷新了。据报道,Facebook的首席技术官在给员工的电子邮件中也提到了事件发生后对其网络的压力。8. 这次中断事件可以避免吗?
所有这些都引发了关于如何避免这次故障的问题。例如,为什么Facebook的所有系统都在内部运行?为什么它们在危机中如此无法进入?为什么审计工具会出现错误?为什么一个工程师在摆弄全球骨干网的容量?
至少,Facebook的崩溃应该成为一个警钟,而且不仅仅是对Facebook而言。像世纪互联这样的其他故障已经表明,其他系统也是按照类似的思路运作的,即使在这个零信任和网络战的时代。
正如Santosh Janardhan今天写道。"每一次这样的失败都是一个学习和改进的机会,我们从这次失败中可以学到很多。"
https://www.futuriom.com/articles/news/speculation-swirls-around-facebook-outage/2021/10
https://www.thousandeyes.com/blog/facebook-outage-analysis
https://eveningreport.nz/2021/10/05/what-caused-the-unprecedented-facebook-outage-the-few-clues-point-to-a-problem-from-within-169249/






