上一篇文章说了下ES的安装和启动过程,今天看下它的常用命令。
1、获取ES的基本信息
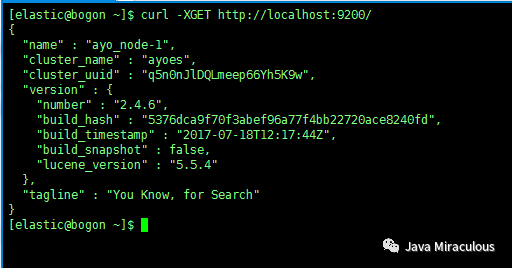
curl –XGET http://localhost:9200/
注释:curl你知道,但你大概率不知道-XGET是个什么玩意,其实-X是curl命令的一个参数,它指定了http请求的方法,GET就是以GET方式对后面的地址发起http请求,当然curl还有很多其他的参数,有兴趣的可以自己私下看看。
2、获取集群中节点的信息
curl -XGET http://localhost:9200/_cluster/state/nodes/
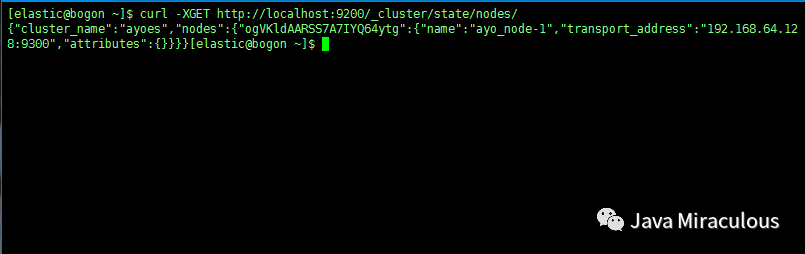
看着是不是有点费眼?运行下面这个命令试试:
curl -XGET http://localhost:9200/_cluster/state/nodes/?pretty
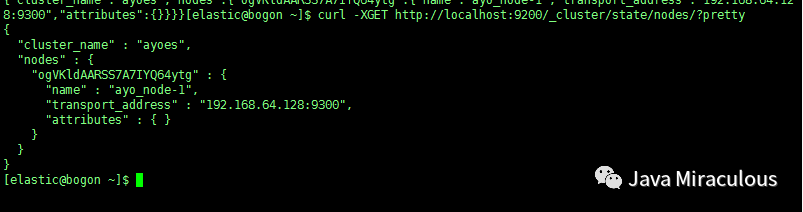
是不是顺眼多了?
注释:pretty是将查询出来的结果换行,可读性更高。
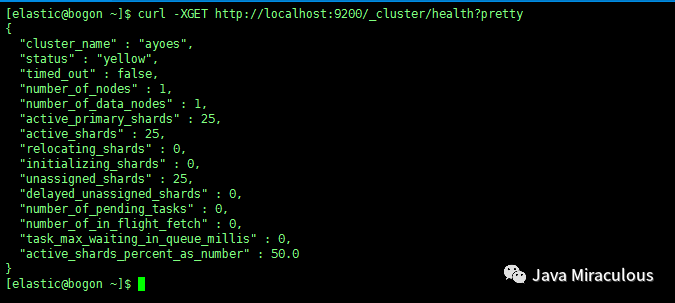
3、获取集群的状态
curl -XGET http://localhost:9200/_cluster/health?pretty
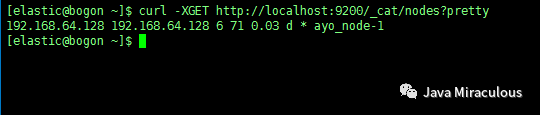
4、获取节点简要信息
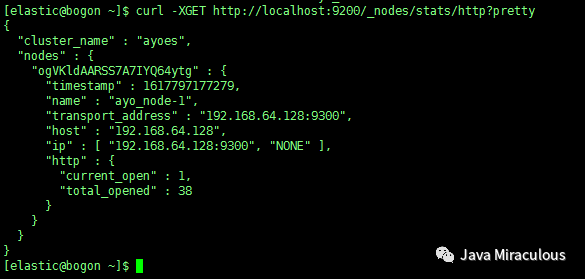
5、获取节点详细信息
curl -XGET http://localhost:9200/_nodes/stats/http?pretty
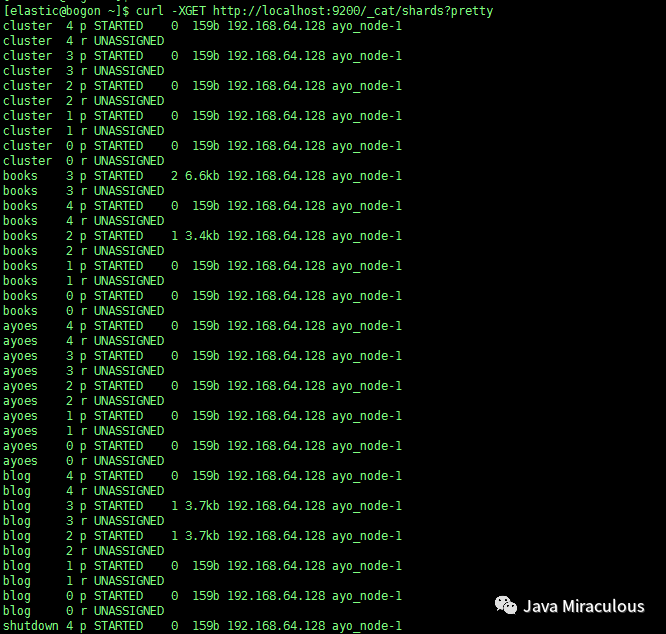
6、获取集群分片状态
curl -XGET http://localhost:9200/_cat/shards?pretty
7、建立一个名为blog的索引和名为article的类型
curl -XPUT http://localhost:9200/blog/article/3 -d '{"title": "New version of Elasticsearch released!", "content": "Version 1.0 released today!", "tags": ["announce", "elasticsearch", "release"] }'
注释:
什么是索引?
索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。你可以把索引看成关系型数据库的表。
什么是类型(文档类型)?
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。文档类型让我们轻易地区分单个索引中的不同对象。
什么是文档?
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
什么是标识符?
其实相当于你插入这条记录的id,比如article后面的3。
命令中的-d参数,此参数后面跟的值将作为请求负载的文本,也就是Request body,注意一定要符合json规范,不然会报错!

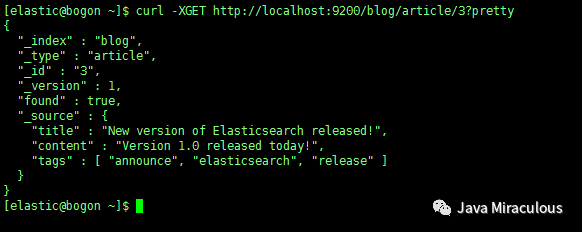
8、根据标识符检索文档
curl -XGET http://localhost:9200/blog/article/3?pretty
9、根据标识符更新文档
curl -XPOST localhost:9200/blog/article/3/_update -d '{"script":"ctx._source.content=\"new content\""}'
注释:
这里有个坑,出现了更新失败,经查证原因如下:
在最新版本的Elasticsearch中,基于安全考虑(如果用不到,请保持禁用),默认禁用了动态脚本功能.如果被禁用,在使用脚本的时候则报以下的错误:
scripts of type [inline], operation [update] and lang [groovy] are disabled

script.inline: on
script.indexed: on
script.file: on
配置完后重启Elasticsearch即可。
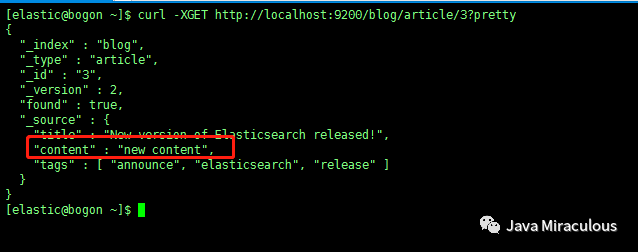
然后再更新,成功:

查询下,发现已经更新:
10、更新一个不存在的字段
curl -XPOST localhost:9200/blog/article/3/_update -d '{"script":"ctx._source.counter += 1"}'
但是你会发现报错了:

注释:
这里需要做下判断,给个默认值,然后更新即可:
curl -XPOST localhost:9200/blog/article/3/_update -d '{"script":"if(!ctx._source.containsKey(\"counter\")) ctx._source.counter=0;ctx._source.counter += 1"}'

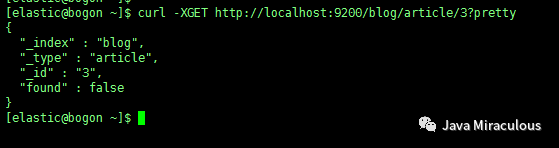
11、根据标识符删除文档
curl -XDELETE localhost:9200/blog/article/3

再查询下,发现已经没有了:
12、使用URI请求查询来搜索
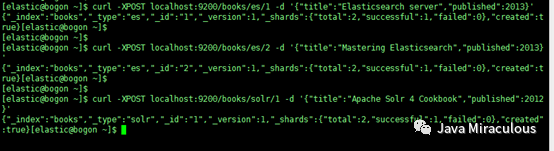
示例数据:
curl -XPOST localhost:9200/books/es/1 -d '{"title":"Elasticsearch server","published":2013}'
curl -XPOST localhost:9200/books/es/2 -d '{"title":"Mastering Elasticsearch","published":2013}
curl -XPOST localhost:9200/books/solr/1 -d '{"title":"Apache Solr 4 Cookbook","published":2012}'
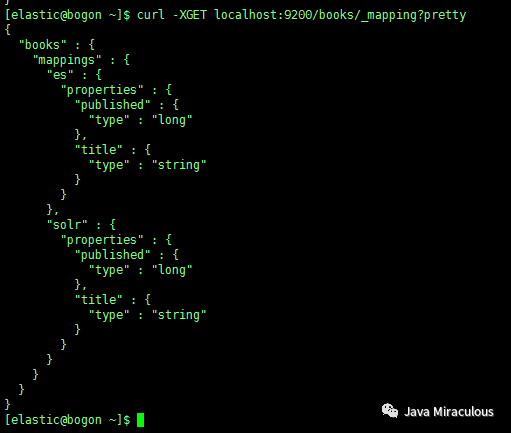
查询整个索引的映射:
curl -XGET localhost:9200/books/_mapping?pretty
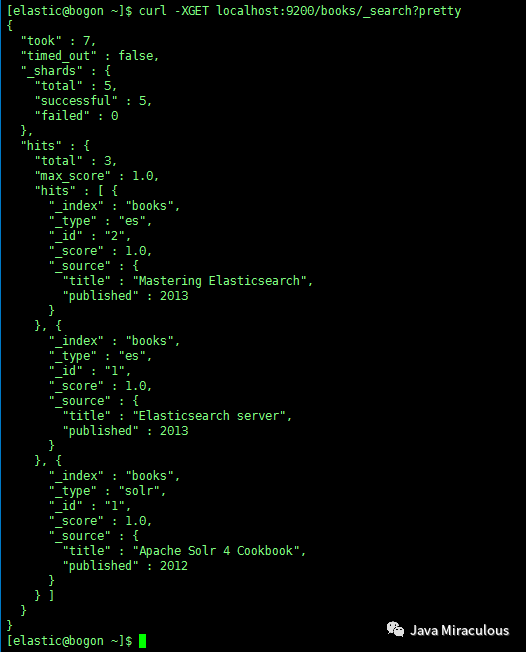
查询索引信息:
curl -XGET localhost:9200/books/_search?pretty
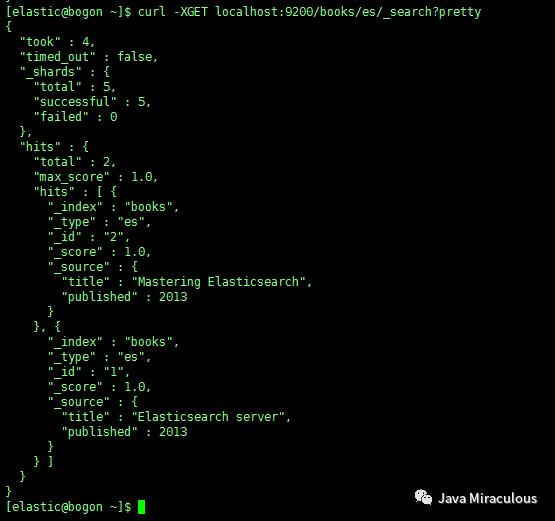
还可以添加类型进行搜索:
curl -XGET localhost:9200/books/es/_search?pretty
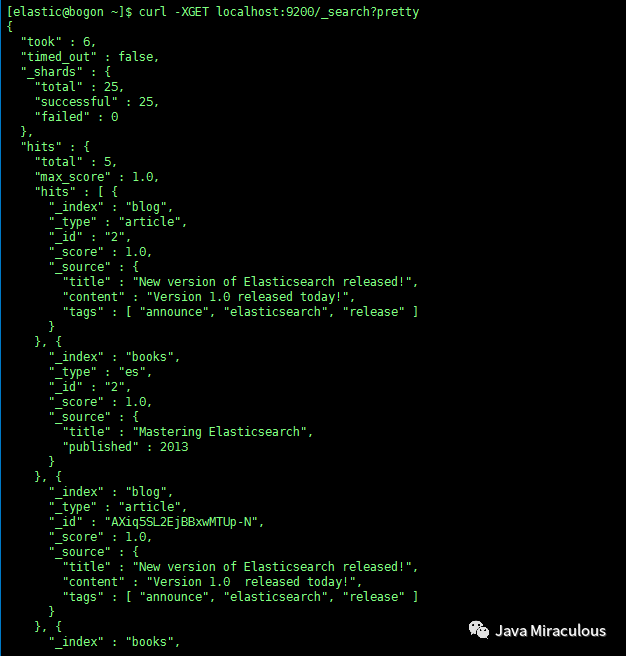
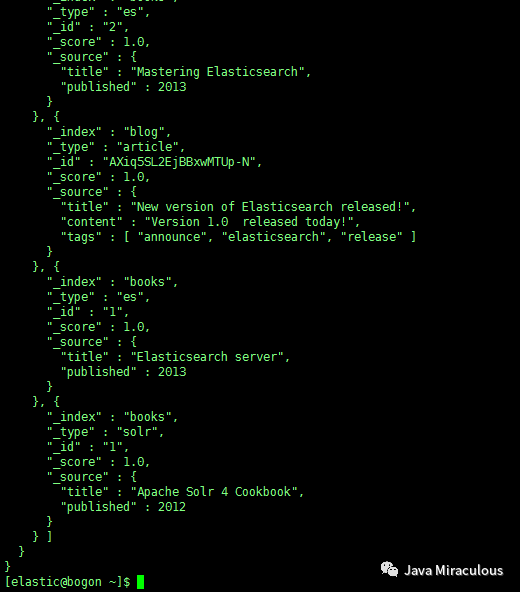
不指定索引和类型将查询集群中的所有索引数据:
curl -XGET localhost:9200/_search?pretty
如果想找到books索引中title字段包含elasticsearch一词的所有文档,可以这样查询:
curl -XGET localhost:9200/books/_search?pretty&q=title:elasticsearch
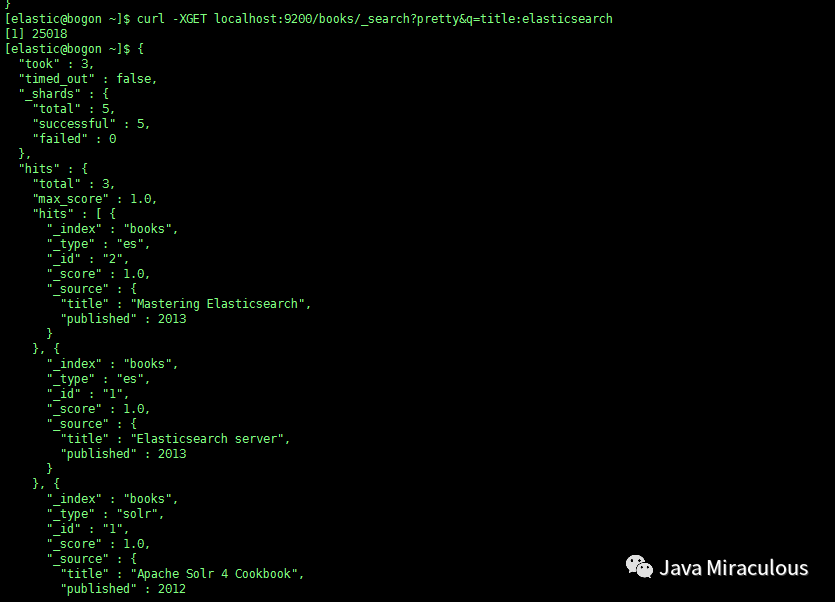
注释:
took:单位毫秒,标识请求花了多少时间
timed_out:有没有超时
shards:执行请求时查询的分片信息
total:查询的分片数量
successful:成功返回结果的分片数量
failed:失败的分片数量
hits
total:查询返回的文档总数
max_score:计算所得的最高分
hits:返回文档的hits数组
_index:索引
_type:类型
_id:标识符
_score:得分
_source:这是发送到索引的JSON对象
为了看到title字段上的短语“Elasticsearch Server”建立的索引具体是什么,可以执行下面的命令:
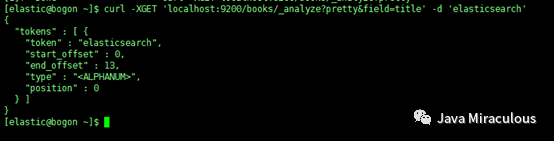
curl -XGET 'localhost:9200/books/_analyze?pretty&field=title' -d "Elasticsearch Server"(注意,这里有个坑,就是,如果后面加参数并且要和pretty配合使用的时候,整个表达式需要用单引号括起来,不然报错,因为在linux系统中,&字符是会被linux shell解析的)。
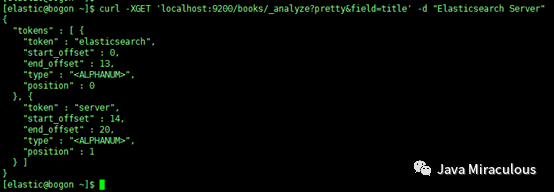
可以看到,Elasticsearch把文本分为两个词,第一个标记值(tokenvalue)为elasticsearch,第二个标记值为server,现在看看查询文本是如何被分析的,运行下面的命令:
curl -XGET 'localhost:9200/books/_analyze?pretty&field=title' -d 'elasticsearch'