




最近,在v2ex上刷到一个帖子:一位网友面了几个程序员,发现他们对MySQL的distinct关键字有误解,而是还是那种3-5年工作经验的。
帖子的具体内容如下:
都认为这是一个函数,可以这样用:
select distinct(name), age from test;
目的是给 name 去重。虽然没有报错,但是其实上面的 sql 最终被解析成:
select distinct (name), age from test;
就是说 distinct 不是一个函数,而是 select 的一部分,结果是给 name,age 的组合数据去重,name 加括号在这里没有什么意义。是那种工作了 3~5 年工作经验的,不知道 v 友们又没有发现这个问题。
因此,我们在网上找了一篇基础的文章给大家回顾一下,希望对各位同学后面找工作有所帮助。
select distinct expression[,expression...] from tables[where conditions];复制
这里的expressions可以是多个字段。本文的所有操作都是针对如下示例表的:
CREATE TABLE `person` (`id` int(11) NOT NULL AUTO_INCREMENT ,`name` varchar(30) NULL DEFAULT NULL ,`country` varchar(50) NULL DEFAULT NULL ,`province` varchar(30) NULL DEFAULT NULL ,`city` varchar(30) NULL DEFAULT NULL ,PRIMARY KEY (`id`))ENGINE=InnoDB;复制
1.1 只对一列操作
这种操作是最常见和简单的,如下:
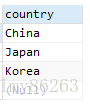
select distinct country from person复制
结果如下:
1.2 对多列进行操作
select distinct country, province from person复制
结果如下:
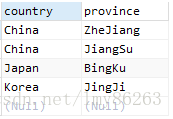
从上例中可以发现,当distinct应用到多个字段的时候,其应用的范围是其后面的所有字段,而不只是紧挨着它的一个字段,而且distinct只能放到所有字段的前面,如下语句是错误的:
SELECT country, distinct province from person; // 该语句是错误的复制
抛出错误如下:
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘DISTINCT province from person’ at line
1.3 针对NULL的处理
从1.1和1.2中都可以看出,distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的。
1.4 与ALL不能同时使用
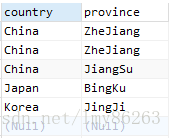
默认情况下,查询时返回所有的结果,此时使用的就是all语句,这是与distinct相对应的,如下:
select all country, province from person复制
结果如下:
1.5 与distinctrow同义
select distinctrow expression[,expression...] from tables [where conditions];复制
这个语句与distinct的作用是相同的。
1.6 对*的处理
*代表整列,使用distinct对*操作,sql如下:
select DISTINCT * from person复制
相当于
select DISTINCT id, `name`, country, province, city from person;复制
来源:https://urlify.cn/a6b6bq 复制
1、GitHub 标星 3.2w!史上最全技术人员面试手册!FackBoo发起和总结
5、37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...
