




This article is talk about my speech on beam summit2020 :)
Hello, everyone. I'm very happy to share with you today. The topic shared today is “PyFlink on Beam : How does it actually works”

I will divide the content of talk into three sections:
First of all, I'd like to introduce what is Beam on Flink and what is Flink on Beam, and how we look at them..
Second, I'd like to report that What did Pyflink on Beam do, that is,I will show you How doe PyFlink on Beam actually work.
Finally, I would like to introduce the Mission and Road map of pyflink.

Before today's sharing, I'd like to make a brief introduction to myselffirst: I'm staff engineer at Alibaba. I have been involved in ASF since2016. Now I am a PMC member of Apache Flink and IoTDB, also a committer for Flink, Beam, and IoTDB. and I was very lucky to beelected as an ASF member this year.J
AndI'd like to share One of my favorite words, that is, : Be as good as I can,regardless of what it leads you.

OK, let's start the first section of talk, “Beam on Flink vs Flink on Beam”.
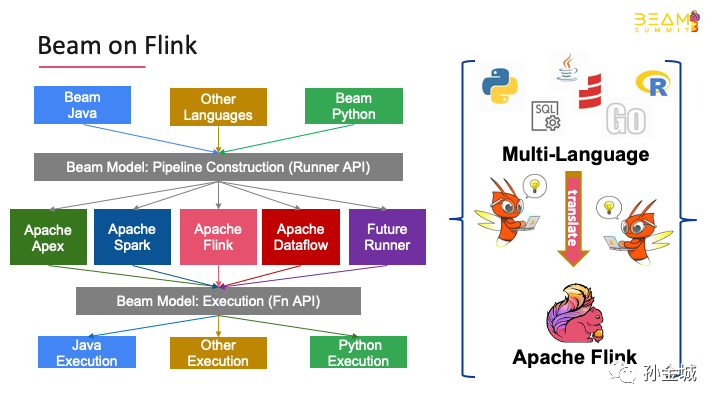
As we know Beam is an advancedunified programming model, it implement batch and streaming data processingjobs that run on any execution engine.
So Beam on Flinkmeans that using Beam API write Flink jobs.
At present, beam supports multilanguage APIs, such as python, Java, SQL, go, etc., which means that users ofany language supported by beam can write Flink jobs and use Flink'spowerful stream computing functionality to solve their business problems.
Beam will help users translate thecalculation logic described by API into Flink's job topology.
Of course, the integration of othercomputing engines in beam is similar to Beam on Flink, Such Beam on Apex, Beam on Dataflow,Beam on Spark.and so on.
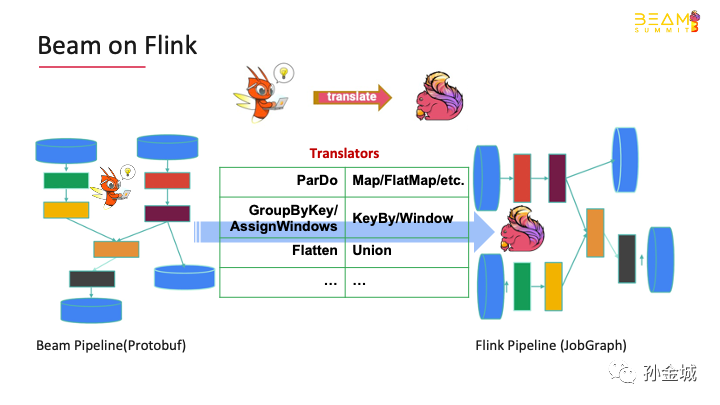
So how does beam transform the jobdescribed by user API into Flinkjob?
There are many operators in beam,such as Prado, groupbykey, flatten and so on. These operators havecorresponding translators in the beam to translate them into operators with thesame semantics of a specific engine. e.g.: For Beam on Flink,Pardo will be translated into the semantic operator of rich flatmap.There will also be corresponding translators for Aggregation and Windows.
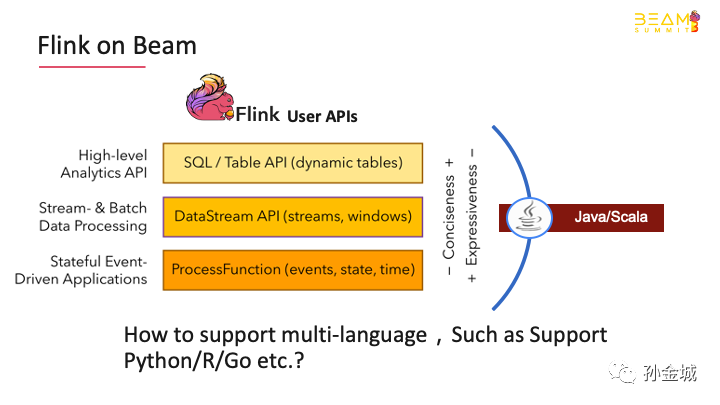
So what is Flinkon beam?Flink is developed by Java. Before Flink1.9, only Java Scala API was supported。The Flink community will expect Flinkto provide good support for multi-languages, so that, more user groups areexpected to enjoy the powerful computing power of Flink, But,howto support multi-languageinFlink,Such as Support Python/R/Go etc.?

Interms of multi language support, beam is excellent, and the beam portabilityframework is very mature and highly abstract in design.
Flinkcan re-use the infrastructure provided by the beam portability framework interms of multi-language support. In other words, we caneasy to re-use the basic service and data structure, at Flinkrunner and FN API level. This will make it very easy for Flinkto support multi-languages, which will be show you in the following contents.

BeamonFlinkmeansUserscan use the beam API to write Flink jobsof any calculation logic,i.e.,From the usability of Flinkfunctionality, it is the same as Flinkon Beam.
So how do users choose to use beamAPI or FlinkAPI to develop Flinkjobs?
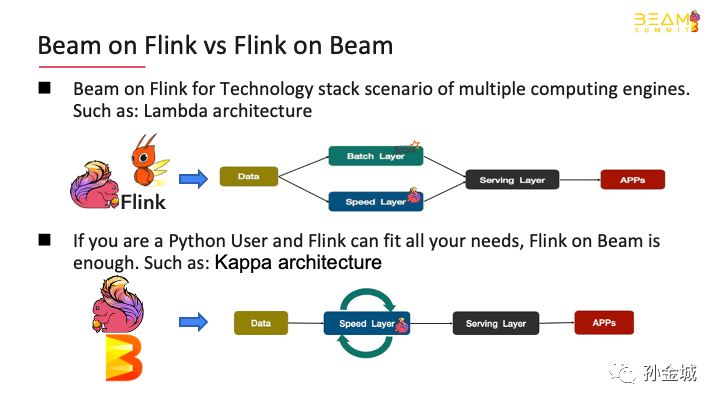
This decision has a lot to do withyour company's existing technology architecture and specific business.
For example, If your businessinvolves multiple computing engines, such as, spark for batch, and Flinkfor streaming,Then Beam on Flink is your best choice.
And if Flinkcan solve all your business needs, you only want choose the developmentlanguage, such as Python, Java , SQL, then using Flink on Beam is enough.

OK, After a brief introduction toBeam on Flinkand Flinkon beam, let's move on to the most important part of today, what did pyflinkon beam do
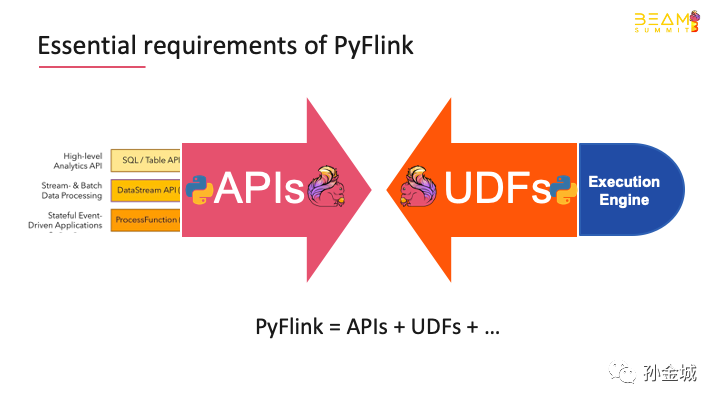
Pyflink is the Flink Python API. There are two levels ofrequirements to be solved. The first is the API level, and the other is thesupport of Python user-defined functions。
Flinkrequired to provide declarative table API SQL and stateful datastreamAPI that can be used by FlinkPython users. For Python UDF, the execution environment is required。
So,TheEssentialrequirements of PyFlinkareAPIsandUserdefinedfunctions.

For API support, we need toconsider several important aspects:
Python is only one of languageentry, and should not affect the semantics of existing Flinkoperators,
So,the most important thing at the python API level is toAlignwith Java Table&DataStream API。
Performanceis also very important, pyflink needs toShare optimization model withJava。
Atthe same time, according to the features of Flink's existing functions andarchitectures, The communication betweenJVM and PVM, support interactive programming and easy to add support new APIsshould be considered

We should to know what is the core problem to support Python API?Obviously , communication between VMs is the most important part.
So, how can we solve it? Let us talk about the API architecture of PyFlink.
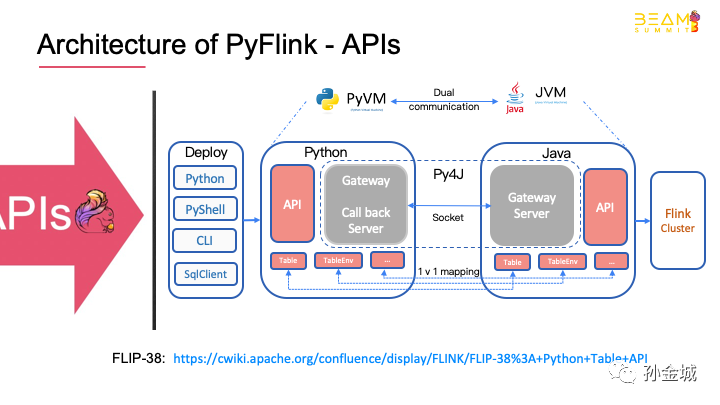
OK,let‘s take a look at the architecture of How to fit the requirements of PyFlink API.
We use py4j to solve communication problems。
Start a gateway in Python VM and a gateway server in Java VM to accept Python requests for the Python API.
Provide the class definition exactly consistent with Java API in Python API,Such as Talbe, tableEnv and so on.
This kind of API design shows that users will call Java API when writing the Python API.
Of course, Flink 1.9 provides variety ways for job deployment, such as: Python command line, Pyflink-shell, CLI and so on.
Ok,let think about the.benefits of this architecture.

For Python UDF support, we alsohave some requirements.
In the future, Flinkshould support not only Python language, but also R, Go and other languages,so, we should share the same architecture for every language which Flinkwant to support.
Flinkis a framework and distributed processing engine for stateful computationsover unbounded and bounded data streams.
And Python UDF should be stateful.
In addition, python dependencymanagement, python UDF deployment mode, and maintenance and monitoring arealso very important requirements
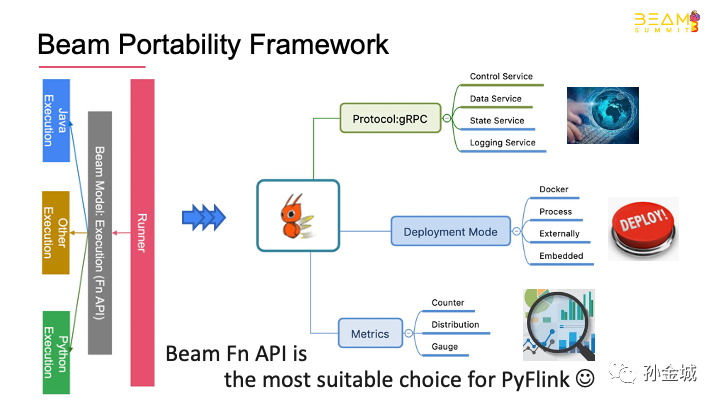
Beam‘s existing architecture meetsalmost all of the above UDF support requirements.
Beam’s portability frameworkintroduces well-defined, language-neutral data structures and protocols betweenthe SDK and runner. It ensures that SDKs and runners can work with each otheruniformly. At the execution layer, the Fn API is provided which is forlanguage-specific user-defined function execution. The FnAPI is highly abstract and it includes several generic components such ascontrol service, data service, state service, logging service, etc. which makeit not only available for Beam, but also third part projects which requiremulti-language support.
So,Beam is best chiose for Flink to provide Python language support.

OK, let's take a look at the UDF architecture of pyflink. In the architecture of UDF, we should consider not only the communication between Java VM and python VM, but also the different requirements in the compile part and runtime part.
In the pic, we show the behavior of Java VM in grey and python VM in blue.
First, let‘s look at the compile part. The design of local is a pure API mapping. We still use py4j to solve the communication problem, that is, every Python API executed as shown in the pic will call the corresponding API of Java.
To support UDF,we need to add the API of UDF registration[ˌredʒɪˈstreɪʃn].
And also need to add the dependency management APIs, such as, a series of add methods, e.g.: add_python_file().
After finish the python job development, the Java API builds the job graph. And submit the job to the cluster by CLI or other ways.
Then, Let's take a look at behavior of Python and Java opertors at runtime.
First, on the Java side, Jobmaster assigns jobs to task manger, and task manager will execute tasks.
Task involves the execution of Java and python operators. In Python UDF operators, we will design various gRPC services for communications between Java VM and python VM, such as data service for business data communication, state service for Python UDF to call Java state backend, of course, it also provides logging and metrics and other services.
These services are built based on the FN-API of beam. At last, the user's UDF is executed in the python worker.
Then use the gRPC service to return
the results to Java VM. I‘d like to call this part of the design: Flink on beam
Of course, The worker of Python is not only a process mode, but also a docker mode or even an external service cluster.
Well, this is the architecture that pyflink introduced Python UDF already support in 1.10.
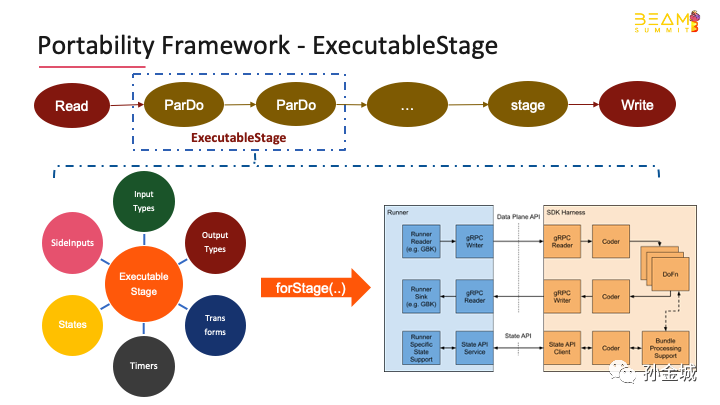
The most important thing about PyFlinkon beam is how to execute Python UDF with infrastructure of Beam. let's have alook at how we use Beam’s portability framework in PyFlinkfor Python user-defined function execution. As we know that a job is usuallymade up of multiple operators, each operator represents a specific computelogic, e.g. reading data from external storage system, performing a series oftransformations on the input data and writing the results to another externalstorage system.
Most computing engines areimplemented in one language, such as Flinkwriten by Java. However, the user-definedtransformation logic may be written in other languages, such as Python, Go,etc. Take the above pipeline as an example, supposing that ParDorepresents use-defined Python function. An ExecutableStage was introduced in Beam which containsall the necessary information about the use-defined Python function, such as:the input/output data types, the user-defined function payload, the state andtimers used in the user-defined function, etc.
Besides, Beam has provided a Javalibrary which could be used to manage the language-specific executionenvironment. "forStage()" will according to theinformation defined in ExecutableStage to spawn[spɔːn] the necessary process(called SDKharness) to execute the user-defined function, establish the connectionsbetween runner and SDK harness, for example, data channel for datatransmission, state channel for state access.
One thing to note that foreliminate unnecessary communication and serialization/deserialization overheadbetween the runner and the SDK harness we can wrap multiple operators into an ExecutableStage and executed together.
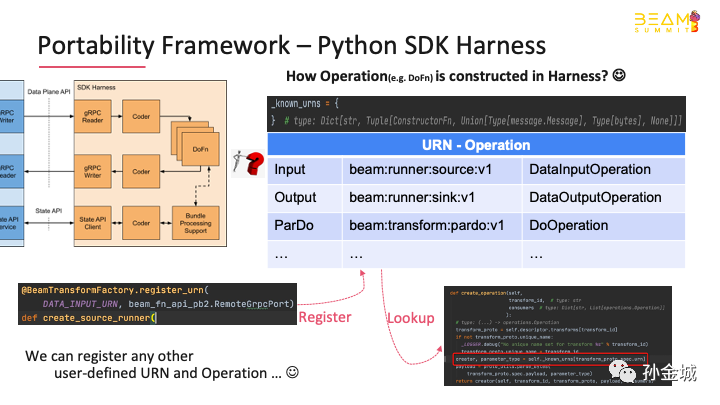
Beam’s portability framework alsoprovides multiple SDK harness which are used to execute user-defined functionswritten in different languages, such as Java/Python/Go.
For each SDK harness, it supportsto execute multiple kinds of functions, for example, ParDo,Flatten, etc. Different functions have different execution patterns and so theSDK harness has defined one specific Operation class to execute it. But how canwe clearly define the execution logic of each function in the beam? This isbeam's plug-in management of operation.
To tell which kind of functions toexecute, a URN is defined for each type of function.
Regarding to the Python SDK harnesswhich is currently used in PyFlink, it works as following:
During the startup phase, thePython SDK harness will establish the URN and Operation mapping for all thebuilt-in operations. The key point here is that it supports to register customURN and operations.
During the initialization phaseof processing a new bundle, the runner will send the URN together with thefunction payload to the SDK harness. The SDK harness could construct thecorresponding Operation according to the given URN. The Operation is then usedto execute the user-defined function logic with the input data.
Which means that we can registerany other user-defined URN and create any other Operation.
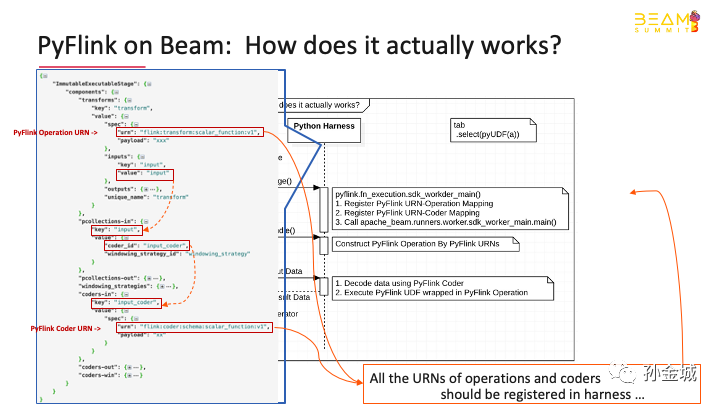
Let’s take a lookat how PyFlink on Beam actuallyworks. The picture shows the basicworkflow. A specific Flinkoperator was used to execute the Python user-defined functions defined in PyFlink.In the initialization phase, the Flink operator constructs an ExecutableStage which contains all the necessaryinformation about the Python user-defined functions to be executed.
Next, the Flinkoperator will start up the Python SDK harness. This is achieved by calling theJava library provided by Beam’s portability framework. The entrypointof the Python SDK harness is provided by PyFlink. It wraps the entrypointof Beam’s Python SDK harness. The main purpose of providing a custom entrypointin PyFlink is to register the custom operations andcoders used by PyFlink.
Lastly, the Flinkoperator could send input data to the Python SDK harness. The Python SDKharness executes Flink’s Python user-defined functions and sentback the execution results.
Let's shows an example of the ExecutableStage instance.
We can see that it contains thepayload of the Python function,
besides, it also contains a specialURN which indicates that this is a Flink scalar function.
We can see that it alsocontains the URNs and payload of theinput and output coder.
Of course, there are many details,but the most important thing about pyflink on beam are built Executable Stage andAdd Operations/Coders by registering URNs…

Here is an example on how weregister the custom operations and coders used in PyFlink.We can see that it’s very simple. We have added a few functions which are usedto create custom operations and coders. The functions are decorated with thedecorators defined in Beam’s Python SDK harness. The decorator contains twoparameters: the URN and a custom protobuf-based parameter.

Of course, another very importantfeature is Python dependency management, we can talk about it in another speechin the future …

Built Executable Stage and Add Any Operations/Coders by registering URNs…It is easy to add multi-language support Base on Beam.

Ok, at the end of my part, let's take a look at the future plan of pyflink. The Roadmap and Mission of PyFlink
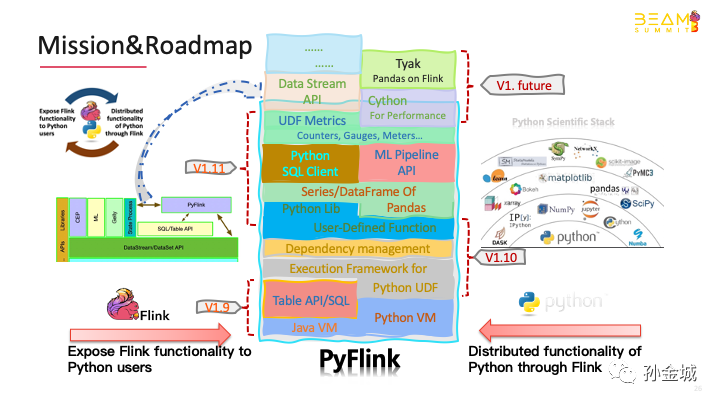
Pyflink always aims to expose the Flink functionality to Python users and integrate Python functionality into Flink.
First, solve the communication problem between Python VM and Java VM, then expose the Java table API to Python users. which is the done in Flink 1.9.
Next, we need to prepare for the integration of Python functionality into Flink by integrate Apache beam. Then provide the execution environment of Python UDF, and add python The dependence management for the user-defined-funciton, which is what Flink 1.10 does. In order to further expand the distributed function of Python ecosystem, pyflink will provide the support of pandas series and dataframe data structure, that is, users can directly use the UDF of pandas in pyflink.
At the same time, we add Python UDFs support in SQL client, in order to let users have more ways to use pyflink.
For machine learning problems of Python users, we have to add ml pipeline API of Python. And the metrics of Python UDF is very important for the production, so pyflink will add the metric management of Python UDF.
These will be released in Flink 1.11.
However, these features are just the tip of the iceberg of PyFlink.
In the future, we need to carry out performance optimization, graph computing API, Pandas native API,and so on...
This is the roadmap of Pyflink. And let's looking forward it.

Thank you! :)
