




背景
我正在吭哧吭哧地热火朝天搞kafka双活方案呢,突然有个项目需求:使用flume采集mysql数据到kafka、使用flume采集sftp数据到kafka。没办法,不想搞也得搞啊,谁让当时将flume集成到平台内的人是咱呢。本文先介绍如何使用flume采集mysql数据到kafka。
Flume架构
Apache Flume是Apache软件基金会的顶级项目,是一个分布式、可靠且可用的系统,用于高效地收集、聚合大量日志数据,并将其从许多不同的源移动到集中的数据存储。由于数据源是可定制的,Flume可用于传输大量事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件以及几乎所有可能的数据源。
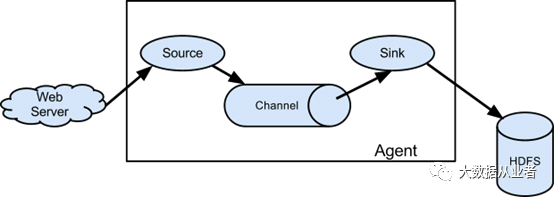
Flume事件定义为具有字节负载和可选字符串属性集的数据流单元。Flume代理是一个(JVM)进程,它承载事件从外部源流向下一个目标(hop)的组件。
flume-ng-sql-source插件
Flume最新版本为1.9.0,虽然官方支持众多source、sink端,遗憾的是并不支持mysql source。不过,天无绝人之路,到github搜索一通,果然有大牛实现了相关插件。详细地址: https://github.com/keedio/flume-ng-sql-source
注意:更改pom.xml flume-ng-core版本为1.9.0,默认为1.7.0。
编译打包即可:
mvn clean package –DskipTests
将打包jar拷贝到flume/lib下,如图:

除此之外,还需要下载个mysql-connector-java.jar到flume/lib下,如图:

废话不多说,直接上配置文件
[root@felixzh apache-flume-1.9.0-bin]# catmysql-flume-kafka.confagent.sources = sql-sourceagent.sinks = k1agent.channels = chagent.sources.sql-source.type=org.keedio.flume.source.SQLSourceagent.sources.sql-source.hibernate.connection.url=jdbc:mysql://localhost:3306/ke?useUnicode=true&characterEncoding=utf-8&useSSL=falseagent.sources.sql-source.hibernate.connection.user=rootagent.sources.sql-source.hibernate.connection.password=felixzhagent.sources.sql-source.hibernate.dialect= org.hibernate.dialect.MySQLDialectagent.sources.sql-source.hibernate.driver_class= com.mysql.jdbc.Driveragent.sources.sql-source.hibernate.connection.autocommit= trueagent.sources.sql-source.table =ke_logsizeagent.sources.sql-source.columns.to.select= *# Query delay, each configured milisecondthe query will be sentagent.sources.sql-source.run.query.delay=10000# Status file is used to save last readedrow#储存flume的状态数据,因为是增量查找agent.sources.sql-source.status.file.path =/home/bigdata/apache-flume-1.9.0-bin/flume-statusagent.sources.sql-source.status.file.name =sql-source.statusagent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSinkagent.sinks.k1.topic = mysql-flumeagent.sinks.k1.brokerList = felixzh1:9092agent.sinks.k1.batchsize = 200agent.sinks.kafkaSink.requiredAcks=1agent.sinks.k1.serializer.class =kafka.serializer.StringEncoderagent.sinks.kafkaSink.zookeeperConnect=felixzh1:2181agent.channels.ch.type = memoryagent.channels.ch.capacity = 10000agent.channels.ch.transactionCapacity =10000agent.channels.hbaseC.keep-alive = 20agent.sources.sql-source.channels = chagent.sinks.k1.channel = ch
mysql表为ke_logsize,条数为25744。
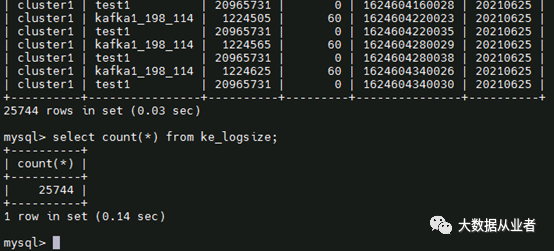
创建kafka测试使用topic
[root@felixzh1 kafka_2.12-2.7.1]#bin/kafka-topics.sh --zookeeper felixzh1:2181 --topic mysql-flume --create--partitions 1 --replication-factor 1
启动flume任务
[root@felixzh apache-flume-1.9.0-bin]#./bin/flume-ng agent -n agent -c conf/ -f mysql-flume-kafka.conf-Dflume.root.logger=INFO,console


消费kafka测试topic数据,共计25744条
[root@felixzh1 kafka_2.12-2.7.1]#bin/kafka-console-consumer.sh --bootstrap-server felixzh1:9092 --topicmysql-flume --from-beginning
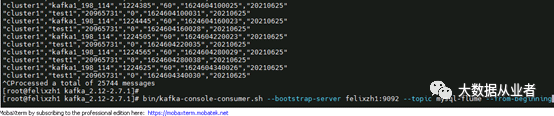
至此,完结!
