




背景
本文为MM2架构与实战全解系列的第二篇文章,主要介绍MM2当前支持的运行模式、配置文件语法及参数集、metrics监控指标等内容。穿插介绍kafka connect框架及confluent公司connectors连接器。
MirrorMaker2.0运行模式
* As a dedicated MirrorMaker cluster.* As a Connector in a distributed Connect cluster.* As a standalone Connect worker.
运行专用MirrorMaker集群
#does not require an existing Connect cluster. Instead, a high-level driver manages a collection of Connect workers.$ ./bin/connect-mirror-maker.sh mm2.properties
运行standalone模式
#In this mode, a single Connect worker runs MirrorSourceConnector.#This does not support multinode clusters, but is useful for small workloads or for testing.$ ./bin/connecti-standalone.sh worker.properties connector.properties
运行distributed模式
#If you already have a Connect cluster, you can configure it to run MirrorMaker connectors.#There are four such connectors:MirrorSourceConnector、MirrorSinkConnector、MirrorCheckpointConnector、MirrorHeartbeatConnectorConfigure these using the Connect REST API:PUT connectors/us-west-source/config HTTP/1.1{"name": "us-west-source","connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector","source.cluster.alias": "us-west","target.cluster.alias": "us-east","source.cluster.bootstrap.servers": "us-west-host1:9091","topics": ".*"}
我们都知道MM2是基于kafka connect框架实现的,熟悉该框架几个核心概念,对于理解该框架运行机制很有必要,如下:
Connectors:the high level abstraction that coordinates data streaming by managing tasksTasks:the implementation of how data is copied to or from KafkaWorkers:the running processes that execute connectors and tasks

confluent公司platform产品内置120+connectors,用于kafka与其他系统之间同步数据。虽然提供的有开源社区版本,但是值得注意的是:开源协议并不是常见的Apache 2.0 License,而是Confluent Community License(即允许免费下载、修改和重新分发代码,但不允许将软件作为 SaaS 产品提供,如 KSQL-as-a-service)。
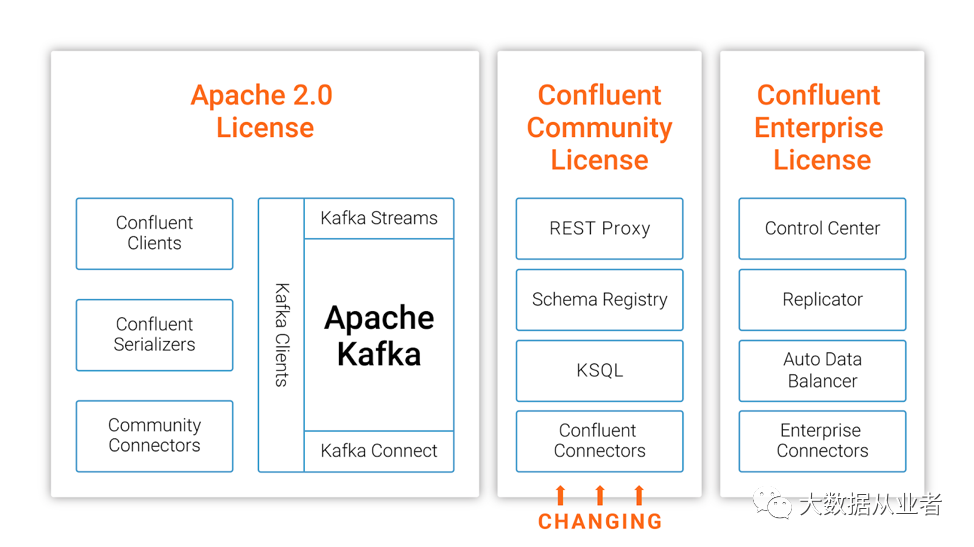
MirrorMaker2.0配置文件语法
默认为connect-mirror-maker.properties(可自定义),内容包括三个模块:
1. MirrorMaker settings
可以定义集群级别、数据流级别
# 集群级别clusters = us-west, us-east # defines cluster aliasesus-west.bootstrap.servers = broker3-west:9092us-east.bootstrap.servers = broker5-east:9092topics = .* # all topics to be replicated by defaulttopics.exclude = .*[\-\.]internal, .*\.replica, __.*groups = .*groups.exclude = console-consumer-.*, connect-.*, __.*##检查新建topicsrefresh.topics.enabled = truerefresh.topics.interval.seconds = 600##检查新建groupsrefresh.groups.enabled = truerefresh.groups.interval.seconds = 600##同步topic configsync.topic.configs.enabled = true##同步aclsync.topic.acls.enabled = true##心跳监测emit.heartbeats.enabled = trueemit.heartbeats.interval.seconds = 1heartbeats.topic.replication.factor = 3##checkpoint设置emit.checkpoints.enabled = trueemit.checkpoints.interval.seconds = 60checkpoints.topic.replication.factor = 3##同步group offsetsync.group.offsets.enabled = truesync.group.offsets.interval.seconds = 60offset-syncs.topic.replication.factor = 3# 数据流级别us-west->us-east.enabled = true # flow from us-west to us-eastus-west->us.east.topics = foo.*, bar.* # override the default aboveus-west->us.east.groups = foo.*, bar.* # override the default above##定制target topic分隔符us-west->us-east.replication.policy.separator = _ #default(.)##如果需要定制特殊映射关系,可以参考DefaultReplicationPolicy类实现ReplicationPolicy和Configurable两个接口,详见源码##https://github.com/apache/kafka/blob/trunk/connect/mirror-client/src/main/java/org/apache/kafka/connect/mirror/DefaultReplicationPolicy.java
2. Kafka Connect and connector settings
MirrorMaker2.0基于Kafka Connect框架实现,可以自定义Kafka Connect框架级别参数、每个connector worker-level级别参数
# 框架级别参数# Setting Kafka Connect defaults for MirrorMakertasks.max = 5 # 默认框架参数开箱即用(out-of-the-box),唯独task.max需要依情况设置(建议至少为2,需考虑硬件资源、复制topic-partitions数目)# connector work-level级别参数# Use the format of {cluster}.{config_name}us-west.offset.storage.topic = my-mirrormaker-offsets
3. Kafka producer, consumer, and admin client settings
MirrorMaker2.0内部使用Kafka producer、consumer、admin客户端。自定义这些客户端参数很有必要。
设置格式:
* {source}.consumer.{consumer_config_name}* {target}.producer.{producer_config_name}* {source_or_target}.admin.{admin_config_name}
consumer举例:us-west cluster (from which to consume)us-west.consumer.isolation.level = read_committedus-west.admin.bootstrap.servers = broker57-primary:9092producer举例:us-east cluster (to which to produce)us-east.producer.compression.type = gzipus-east.producer.buffer.memory = 32768admin举例:us-east.admin.bootstrap.servers = broker8-secondary:9092
MirrorMaker2.0监控metrics
强烈建议监控mm2进程metrics,以确保所有定义的数据流正常。mm2继承了kafka connect框架所有connect metrics(如source-record-poll-rate)。
mm2自身metrics位于kafka.connect.mirror metric group。
# MBean: kafka.connect.mirror:type=MirrorSourceConnector,target=([-.w]+),topic=([-.w]+),partition=([0-9]+)record-count # number of records replicated source -> targetrecord-age-ms # age of records when they are replicatedrecord-age-ms-minrecord-age-ms-maxrecord-age-ms-avgreplication-latency-ms # time it takes records to propagate source->targetreplication-latency-ms-minreplication-latency-ms-maxreplication-latency-ms-avgbyte-rate # average number of bytes/sec in replicated records# MBean: kafka.connect.mirror:type=MirrorCheckpointConnector,source=([-.w]+),target=([-.w]+)checkpoint-latency-ms # time it takes to replicate consumer offsetscheckpoint-latency-ms-mincheckpoint-latency-ms-maxcheckpoint-latency-ms-avg
