大家好,我是云朵君!
导读: SHAP是Python开发的一个"模型解释"包,是一种博弈论方法来解释任何机器学习模型的输出。本文重点介绍11种shap可视化图形来解释任何机器学习模型的使用方法。上篇用 SHAP 可视化解释机器学习模型实用指南(上)已经介绍了特征重要性和特征效果可视化,而本篇将继续介绍shap用于模型预测的可解释性。
👆点击关注|设为星标|干货速递👆

SHAP(Shapley Additive exPlanations) 使用来自博弈论及其相关扩展的经典 Shapley value将最佳信用分配与局部解释联系起来,是一种基于游戏理论上最优的 Shapley value来解释个体预测的方法。
从博弈论的角度,把数据集中的每一个特征变量当成一个玩家,用该数据集去训练模型得到预测的结果,可以看成众多玩家合作完成一个项目的收益。Shapley value通过考虑各个玩家做出的贡献,来公平的分配合作的收益。
下面先回顾下如何创建解释器Explaineer,并计算SHAP。
数据集
标准的 UCI 成人收入数据集。
import shap
X,y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)复制

创建Explainer并计算SHAP值
在SHAP中进行模型解释需要先创建一个explainer,SHAP支持很多类型的explainer(例如deep, gradient, kernel, linear, tree, sampling),本文使用支持常用的XGB、LGB、CatBoost等树集成算法的tree为例。
deep:用于计算深度学习模型,基于DeepLIFT算法 gradient:用于深度学习模型,综合了SHAP、集成梯度、和SmoothGrad等思想,形成单一期望值方程 kernel:模型无关,适用于任何模型 linear:适用于特征独立不相关的线性模型 tree:适用于树模型和基于树模型的集成算法 sampling :基于特征独立性假设,当你想使用的后台数据集很大时,kenel的一个很好的替代方案
explainer = shap.TreeExplainer(model)复制
然后计算shap_values
值,计算非常简单,直接利用上面得到的解释器解释训练样本X
,这里有两种形式:
输出numpy.array数组
shap_values = explainer.shap_values(X)复制

输出shap.Explanation对象
shap_values2 = explainer(X)复制

模型预测的可解释性
Force plot
Local 可解释性提供了预测的细节,侧重于解释单个预测是如何生成的。它可以帮助决策者信任模型,并且解释各个特征是如何影响模型单次的决策。
单个预测的解释可视化
SHAP force plot 提供了单一模型预测的可解释性,可用于误差分析,找到对特定实例预测的解释。
# 如果不想用JS,传入matplotlib=True
shap.force_plot(explainer.expected_value,
shap_values[0,:],
X_display.iloc[0,:])复制

尝试分析此图。
模型输出值:-5.89 基值:模型输出与训练数据的平均值(explainer.expected_value) 绘图箭头下方数字是此实例的特征值。如Age=39,Education-Num=13 将预测推高的特征用红色表示,将预测推低的特征用蓝色表示 箭头越长,特征对输出的影响越大。通过 x 轴上刻度值可以看到影响的减少或增加量。
多个预测的解释可视化
如果对多个样本进行解释,将上述形式旋转90度然后水平并排放置,得到力图的变体,我们可以看到整个数据集的 explanations :
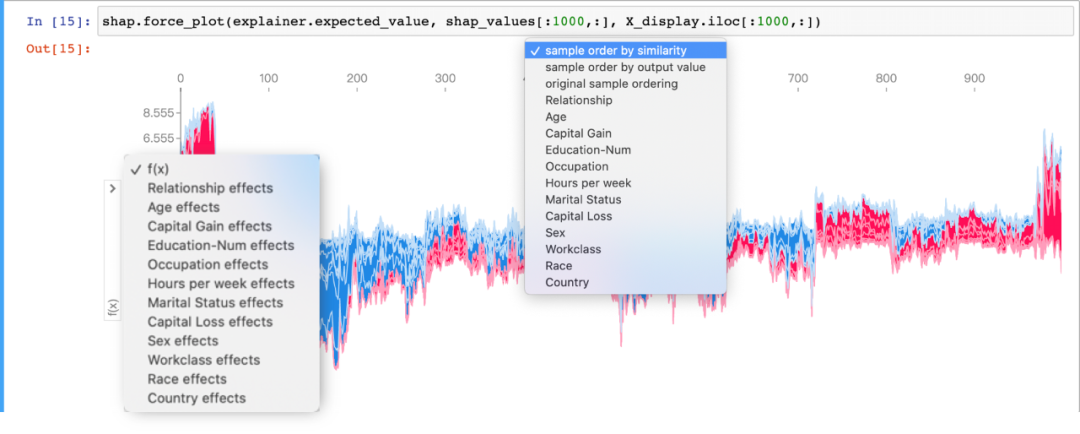
通过上图中上方和左方选项卡,可以任意选择单个变量的多个样本对模型输出结果的影响。如下Age前80个样本,对模型输出结果f(x)
的影响。
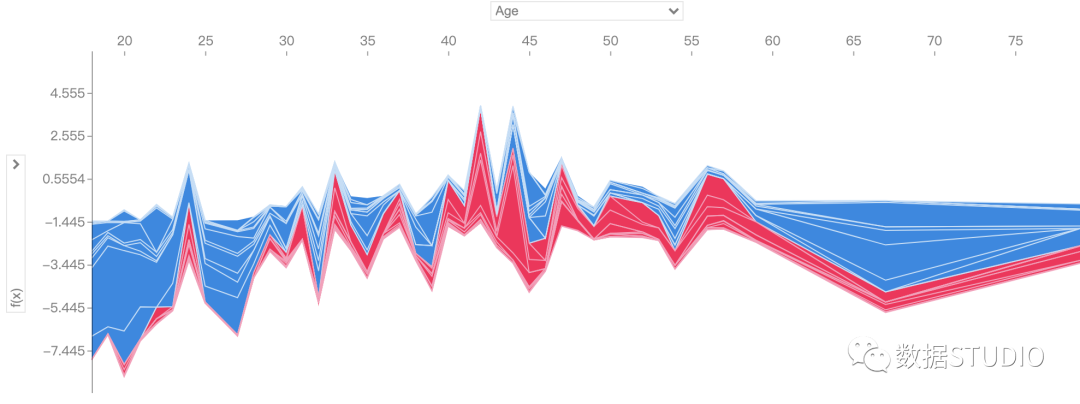
Interaction Values
interaction value
是将SHAP值推广到更高阶交互的一种方法。树模型实现了快速、精确的两两交互计算,这将为每个预测返回一个矩阵,其中主要影响在对角线上,交互影响在对角线外。这些数值往往揭示了有趣的隐藏关系(交互作用)。
shap_interaction_values = explainer.shap_interaction_values(X)
shap.summary_plot(shap_interaction_values, X)复制
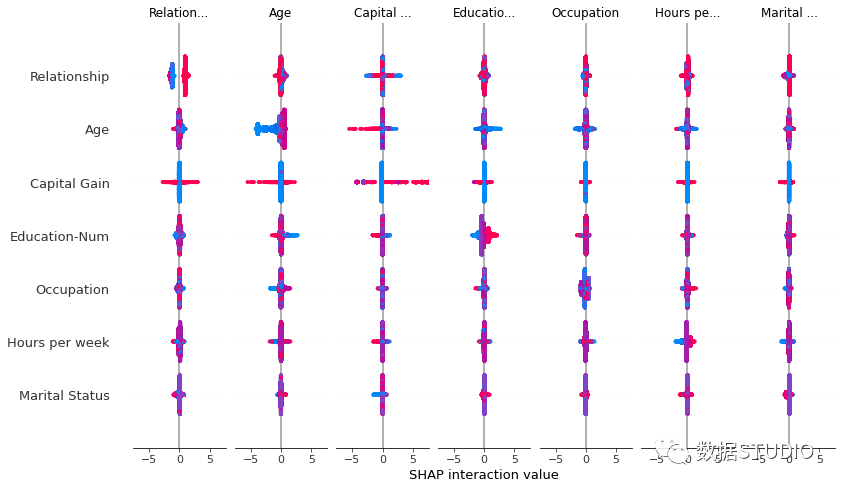
Decision plot
SHAP 决策图显示复杂模型如何得出其预测(即模型如何做出决策)。决策图是 SHAP value 的文字表示,使其易于解读。
决策图显示的信息与力图基本相同,都可以有效地解释上述模型的预测。而且很容易识别出主要影响的大小和方向。
决策图比力图更清晰和直观,尤其是要分析的特征比较多的时候。在力图中,当预测变量的数量较多时,信息可能看起来非常紧凑。
explainer = shap.TreeExplainer(model)
expected_value = explainer.expected_value
# 限制20个样本
features = X.iloc[range(20)]
# 展示第一条样本
shap_values = explainer.shap_values(features)[1]
shap.decision_plot(expected_value, shap_values,
features_display)复制
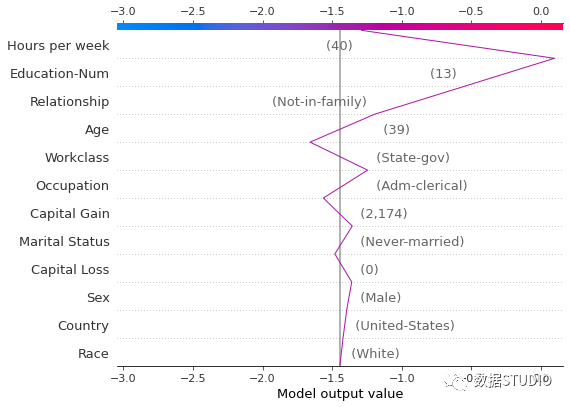
决策图中间灰色垂直直线标记了模型的基础值,彩色线是预测,表示每个特征是否将输出值移动到高于或低于平均预测的值。特征值在预测线旁边以供参考。从图的底部开始,预测线显示 SHAP value 如何从基础值累积到图顶部的模型最终分数。
shap_values = explainer.shap_values(features)
y_pred = (shap_values.sum(1) + expected_value) > 0
misclassified = y_pred != y[select]
shap.decision_plot(expected_value, shap_values,
features_display,
link='logit',
highlight=misclassified)复制
决策图支持将对
link='logit'
数几率转换为概率。使用虚线样式
highlight=misclassified
突出显示一个错误分类的观察结果。
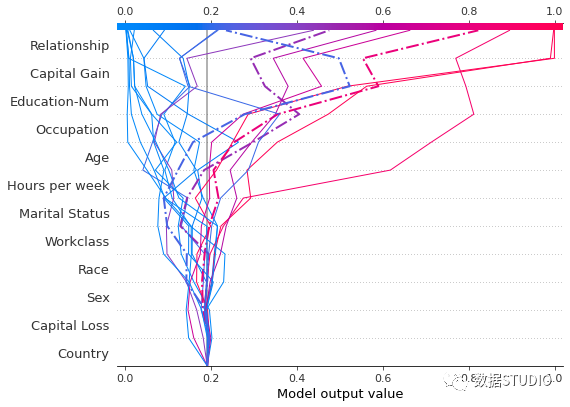
通过单独绘制来检查错误分类的观察结果。绘制单个观测值时,会显示其相应的特征值。
shap.decision_plot(expected_value,
shap_values[misclassified],
features_display[misclassified],
link='logit',
highlight=0)复制
错误分类观察的力图如下所示。在这种情况下,决策图和力图都可以有效地显示模型如何得出其决策。
shap.force_plot(expected_value,
shap_values[misclassified],
features_display[misclassified],
link='logit',
matplotlib=True)复制
决策图的基本作用
大量特征效果清晰展示。 可视化多输出预测。 显示交互的累积效果。 探索一系列特征值的特征效果。 进行异常值检测。 确定典型的预测路径。 比较和对比几个模型的预测。
如需要具体了解每种作用的方法,建议去官网决策图查看每种作用所举的例子。
使用 SHAP 值进行异常值检测
这里只介绍一个异常检测的例子。
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=random_state)
d_train = lgb.Dataset(X_train, label=y_train)
d_test = lgb.Dataset(X_test, label=y_test)
params = {
"max_bin": 512, "learning_rate": 0.05,
"boosting_type": "gbdt", "objective": "binary",
"metric": "binary_logloss", "verbose": -1,
"min_data": 100, "random_state": 1
"boost_from_average": True, "num_leaves": 10 }
model = lgb.train(params, d_train, 10000, valid_sets=[d_test],
early_stopping_rounds=50, verbose_eval=1000)
explainer = shap.TreeExplainer(model)
expected_value = explainer.expected_value[1]
features = X_test.iloc[range(20)]
features_display = X_display.loc[features.index]
shap_values = explainer.shap_values(features)[1]
y_pred = model.predict(X_test)
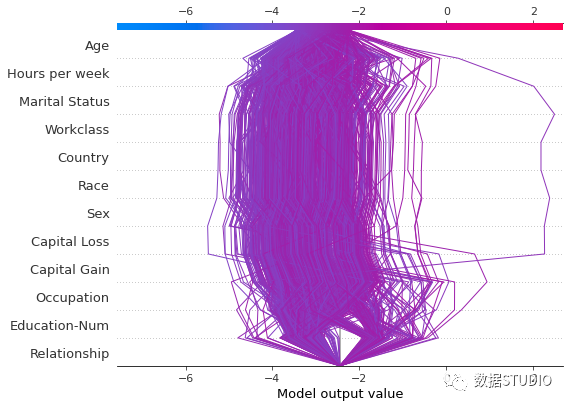
r = shap.decision_plot(expected_value,
explainer.shap_values(T)[1],
X_test[(y_pred >= 0.03) & (y_pred <= 0.1)],
feature_order='hclust',
return_objects=True)复制
将决策图叠加在一起有助于根据 SHAP value 定位异常值。在上图中,你可以看到一个不同数据集的示例,用于使用SHAP决策图进行异常值检测。
Heatmap plot
热图旨在使用监督聚类和热图显示数据集的总体子结构。监督聚类涉及的不是通过数据点的原始特征值而是通过它们的 shap values 对数据点进行聚类。默认使用 shap.utils.hclust_ordering 进行聚类。
绘图时,将 SHAP 值矩阵传递给热图绘图函数。得到的图中, x 轴上是实例、y 轴上是模型输入以及色标上是编码的 SHAP 值。默认情况下,样本使用 shap.order.hclust
排序,它基于层次聚类并根据解释相似性对样本进行排序。
这将因相同原因和具有相同模型输出的样本被分组在一起,如下图中对capital gain影响较大的人被分组在一起了。
shap.plots.heatmap(shap_values)复制
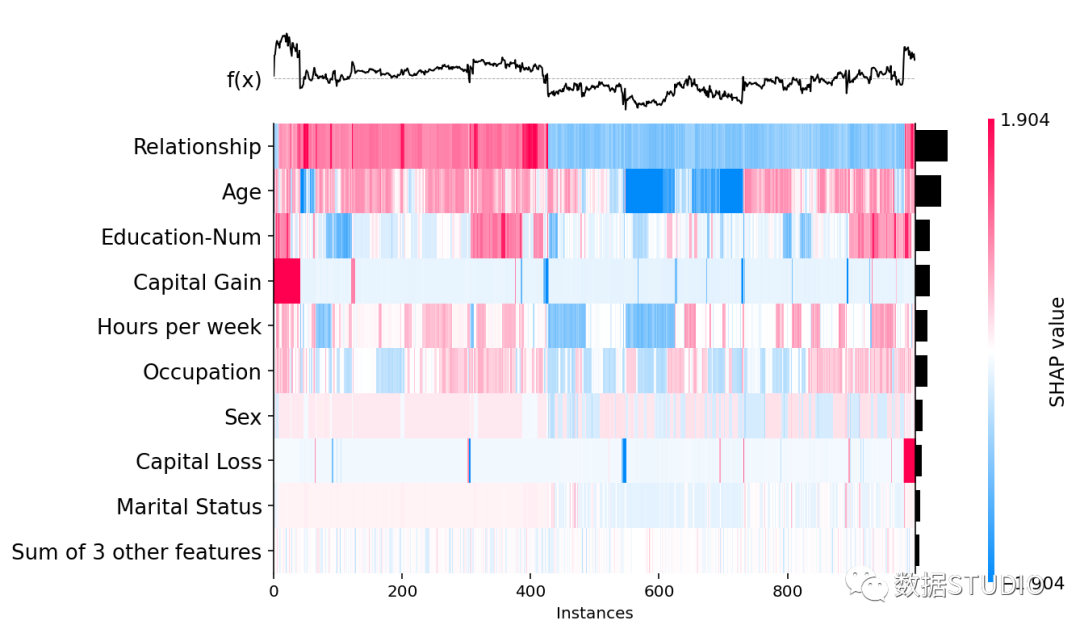
在热图矩阵上方是模型的输出,灰色虚线是基线(.base_value
),图右侧的条形图是每个模型输入的全局重要性(默认用shap.order.abs.mean
整体重要性来度量)
更改排序顺序和全局特征重要性值
通过给feature_values
参数传递一组值来改变衡量特征整体重要性的方式(以及它们的排序顺序)。默认情况下feature_values=shap.Explanation.abs.mean(0)
,还可以在所有样本中按特征的最大绝对值进行排序。
shap.plots.heatmap(shap_values2,
feature_values=shap_values.abs.max(0))复制
通过给instance_order
参数传递一组值控制实例的顺序。默认情况下,设置instance_order=shap.Explanation.hclust(0)
将具有相似解释的样本分组在一起。还可以按所有特征的 SHAP 值总和排序。
shap.plots.heatmap(shap_values2,
instance_order=shap_values.sum(1))复制
Waterfall plot
瀑布图旨在显示单个预测的解释,因此将解释对象的单行作为输入。瀑布图从底部的模型输出的预期值开始,每一行显示每个特征的是正(红色)或负(蓝色)贡献,即如何将值从数据集上的模型预期输出值推动到模型预测的输出值。
shap.plots.waterfall(shap_values2[5])复制
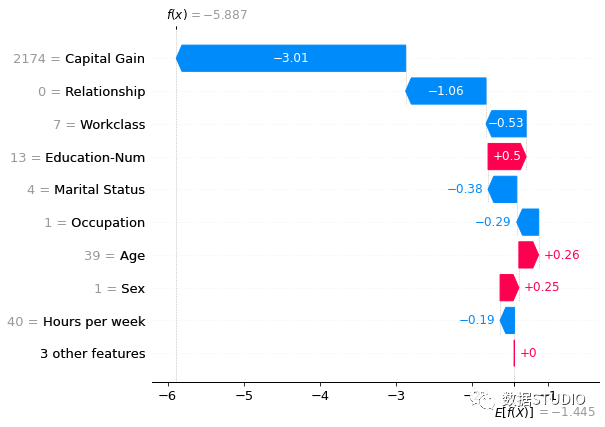
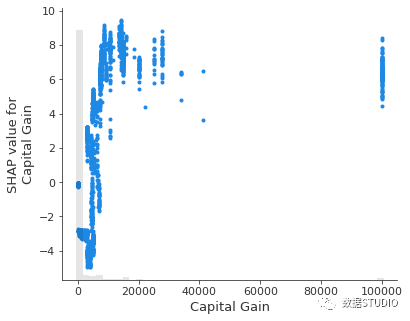
这里值得注意拥有 2,174 美元的资本收益的人会比每年赚取超过 5 万美元的人的预测概率明显低很多。这里由于waterfall
绘图仅显示了单个样本数据,因此我们无法看到资本收益变化的影响。可以使用scatter
图来展示资本收益的低值是如何比根本没有资本收益更负面地预测收入。
shap.plots.scatter(shap_values2[:,"Capital Gain"])复制
参考文章
[1] https://shap.readthedocs.io/en/latest/index.html
[2] https://www.bilibili.com/read/cv11622011

OK,今天的分享就到这里啦!
没看够?点赞在看走起来~后续更精彩~
「数据STUDIO」 正式开放有偿投稿啦!
公号菜单栏【云朵之家】-【投稿】查看~
往期推荐
长按👇关注- 数据STUDIO -设为星标,干货速递

分享
收藏
点赞
在看