




简述
Kudu 是 Cloudera 开源的新型列式存储系统,对实时数据分析支撑良好,同时具备实时 增删改 能力,也是 Apache Hadoop 生态圈成员。
本文主要介绍 CloudCanal 迁移同步关系型数据库(MySQL、Oracle、PostgreSQL) 数据到 Kudu 的能力, 从技术方案和使用角度介绍 CloudCanal 如何达成此类能力。
技术点
可选择的方案
市面上主流迁移同步数据到 Kudu 有三种选择
依赖 SQL 层
Kafka Connector
直连
选用类似 DataX 、Canal 这类开源中间件,同时 Kudu 搭建上层 SQL 引擎如 Hive、Impala ,构建数据迁移同步系统
选用 Kafka + Flume + Kudu 实现数据同步
如 StreamSets 直接将数据从源端数据库写入目标端 Kudu 存储
各方案特点
依赖 SQL 层
Kafka Connector
直连
Hive 基于 MapReduce 架构,基本上很难实时同步,配合 DataX 可进行数据迁移, Impala 基于 MPP 架构,配合 DataX 和 Canal (需要自主消费) 可实现迁移和准实时同步
具备数据堆积能力,适合实时数据中转和攒批写入
路径短,依赖少,实时性好,适合在线场景
CloudCanal 的直连实现
建表
List<ColumnSchema> columns = new ArrayList(2);
columns.add(new ColumnSchema.ColumnSchemaBuilder("key", Type.INT32).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder("value", Type.STRING).build());
List<String> rangeKeys = new ArrayList<>();
rangeKeys.add("key");
Schema schema = new Schema(columns);
client.createTable(tableName, schema, new CreateTableOptions().setRangePartitionColumns(rangeKeys));复制
数据写入
Kudu 由于存储引擎限制,每张表必须要指定 Partition Column。
被设置为 Partition 的列不允许 update,如若修改 Partition Column 列的值。需要删除整行数据重新插入。
Kudu 数据写入 Kudu 支持 Insert、Update、Delete、Upsert 四种操作。
KuduTable table = client.openTable(tableName);
KuduSession session = client.newSession();
session.setTimeoutMillis(60000);
for (int i = 0; i < 3; i++) {
Insert insert = table.newInsert();
PartialRow row = insert.getRow();
row.addInt(0, i);
row.addString(1, "value " + i);
session.apply(insert);
}
session.flush();
session.close();复制
Kudu 1.6 之前,不支持 Decimal。因此源端数据类型如果是浮点数只可以选择:float、double、int、string 来承载。
Kudu 1.15 开始,提供了 varchar 类型可以与 数据库的 varchar 相互对应。在此之前应当选择 string 类型。
举个"栗子"
准备 CLOUDCANAL
SAAS 版参考自建机器客户端安装文章
(https://doc.clougence.com/docs/en/add_worker_self_maintain)
社区版参考文章 docker 安装文章(https://www.askcug.com/topic/75)
添加数据源
登录 CloudCanal 平台
数据源管理 -> 添加数据源
选择 自建数据源 ,并填写相关数据库信息,其中 网络地址 请按提示带上端口号
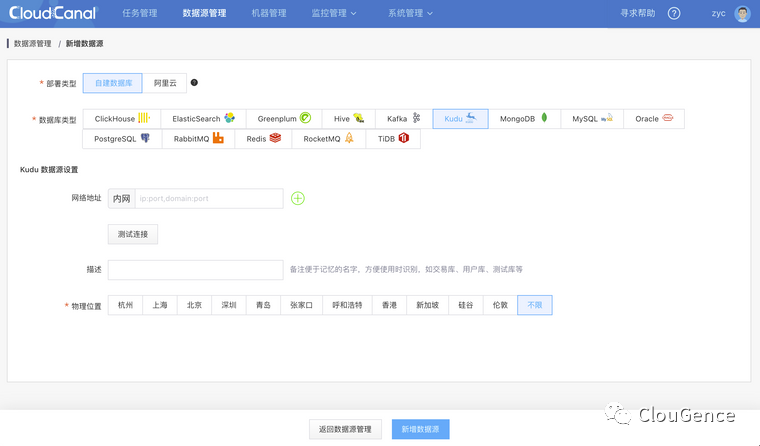
kudu-client 默认访问的是 7051 端口,并非提供 Web 界面的 8051
如果 Kudu 是集群化部署,那么在配置网络地址时需要填写集群 ip:port 列表用 英文逗号 间隔
创建任务
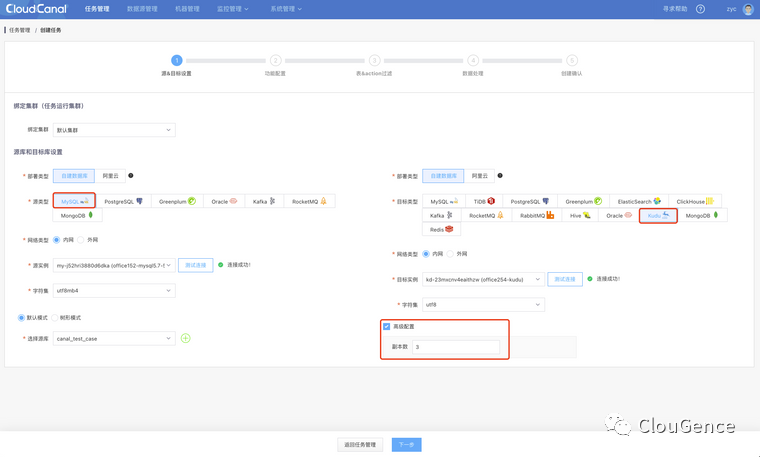
任务管理管理 -> 创建任务
高级选项要求 Kudu 至少 3 副本, 可根据 Kudu 集群情况来修改对应配置
点击 下一步
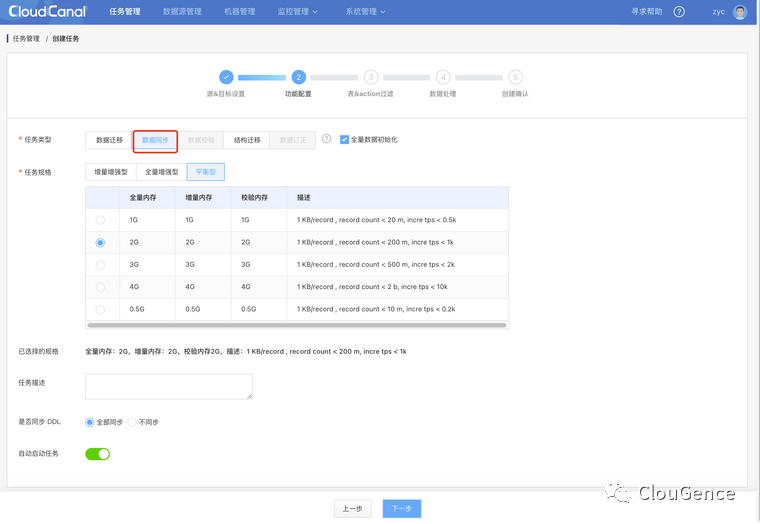
选择 数据同步
点击 下一步
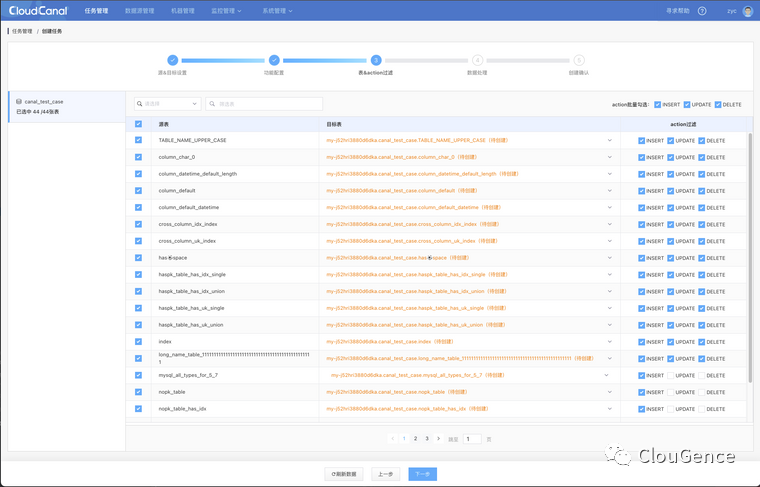
选择要同步的表和操作
点击 下一步
确认创建
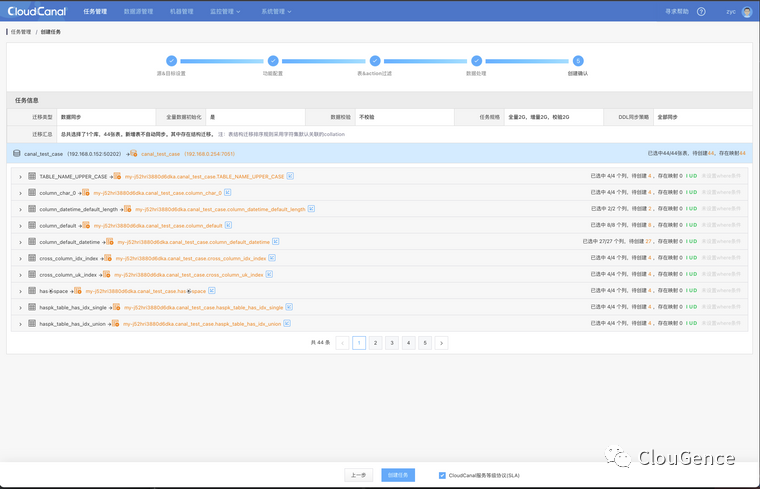
任务自动进行结构迁移、全量迁移、增量同步,稳定运行
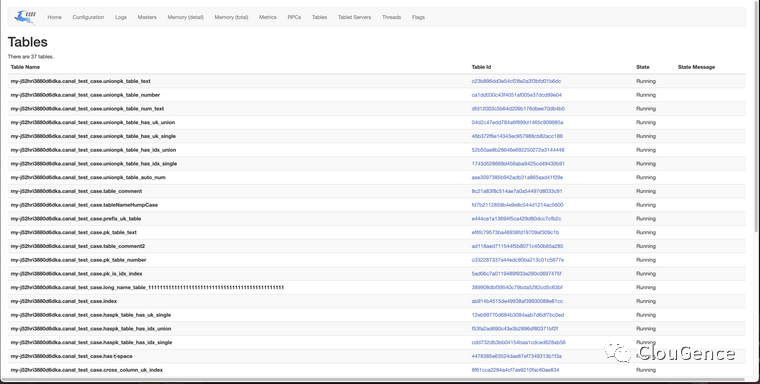
结构迁移跑完之后,Kudu 控制台可看到对应表
使用 Impala 来查询位于 Kudu 中的数据,外表建表语句如下,创建完毕之后使用正常 SQL 语句查询即可
CREATE EXTERNAL TABLE `canal_test_case_column_default` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'my-j52hri3880d6dka.canal_test_case.column_default',
'kudu.master_addresses' = '192.168.0.254:7051')复制
增量同步过程中对源端数据进行增删改,数据可实时同步到 Kudu

能力和限制
支持 MySQL、PostgreSQL、Oracle 作为源端到 Kudu 的同步
支持主键变更同步,转换为 Kudu 删除在插入
对端 Kudu 要求 1.6 版本
不支持源端 无主键表
不支持 DDL 增量同步
总结
本文简单介绍了 CloudCanal 如何将主流关系型数据库迁移同步数据到 Kudu 的能力。各位小伙伴,如果觉得还不错,请点赞、评论加转发吧。
更多精彩
社区快讯
我们创建 CloudCanal 微信粉丝群啦,在里面,你可以得到最新版本发布信息和资源链接,你能看到其他用户一手评测、使用情况,你更能得到热情的问题解答,当然你还可以给我们提需求和问题。快快加入吧。
扫描下方二维码,添加我们小助手微信拉您进群,接头语(“CloudCanal yyds”)

