




什么是爬虫
网络爬虫就是自动访问互联网,并且批量下载数据的程序。
浏览网页的过程
在用户浏览网页的过程中,我们会看到许多好看的图片。这个过程如下:输入网址后经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析后,返回html、js、css等文件,这些文件经过浏览器解析,用户便可以看到图片了。因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的提取。
爬虫三个主要步骤
抓取/网络请求 解析 存储 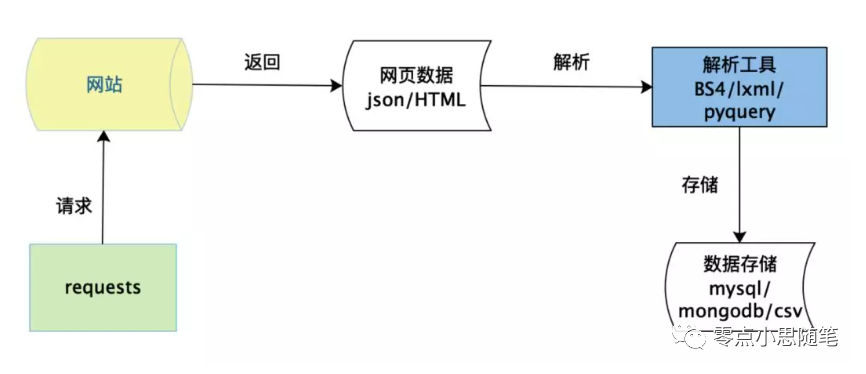
1、网络请求库-requests
安装:pip install requests
中文文档:https://docs.python-requests.org/zh_CN/latest/
GET 请求
import requests
def fetch():
url = 'https://kuaixun.stcn.com/index.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/90.0.4430.212 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
# 返回状态码,一般返回200为成功
status_code = response.status_code
# 获取文本
text = response.text
# 返回json
j_data = response.json()
# 获取二进制
content = response.content
print(status_code)
print(text)
print(content)
print(j_data)
if __name__ == '__main__':
fetch()复制
POST请求
import requests
def fetch():
cookies = {
'XIAOEID': 'e0214a010e4dd3c584193b4512735f0d',
'cookie_channel': '883-894-895-4573',
'xiaoe_admin_is_login': '1',
'mobile_manage': '0',
'dataUpJssdkCookie': '{"wxver":"","net":"","sid":""}',
'appsc': 'appRfC9CrZ96800',
'with_app_id': 'appRfC9CrZ96800',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8',
'Origin': 'https://admin.xiaoe-tech.com',
'Referer': 'https://admin.xiaoe-tech.com/order_manage/order_list',
}
# 表单信息
data = {
"phone": "",
"ship_receiver": "",
"ship_phone": "",
"is_click": "true",
"created_at": "2021-07-04||2021-08-03",
"purchase_name": "",
"nick_name": "",
"order_id": "",
"resource_type": -1,
"transaction_id": "",
"out_order_id": "",
"user_id": "",
"order_state": -1,
"order_type": -1,
"wx_app_type": -1,
"pay_way": -1,
"use_collection": -1,
"sales_state": -1,
"page_size": 10,
"page_index": 2,
"tab_type": -1
}
url = 'https://admin.xiaoe-tech.com/order_manage/get_order_list'
response = requests.post(url, headers=headers,cookies=cookies, data=data)
results = response.json()
print(results)
if __name__ == '__main__':
fetch()复制
GET请求和POST请求的区别:
GET请求发送数据小。浏览器对URL的长度有限制,所以GET请求不能代替POST请求发送大量数据。 POST请求不能被浏览器缓存。 POST请求相对GET请求更安全。
2、解析
内容解析根据返回数据类型可以分为两类:
html json
html 解析使用 xpath 定位法,安装:pip install lxml
xpath 文档:https://www.runoob.com/xpath/xpath-syntax.html
from lxml import html
# 请求返回内容
tree = html.fromstring(response.text)
# xpath 用法请参考文档
results = tree.xpath()复制
json 格式解析:
json.dumps:将 Python 对象编(dict、list, tuple等)码成 JSON 字符串(object、string等) json.loads:将已编码的 JSON 字符串解码为 Python 对象
text = response.text
# 先从String 转 dict 类型,最后再按字段解析
j_data = json.loads(text)复制
除了以上两种方法外,常用的还有正则表达式。
3、存储
数据存储一般存储在MySQL、MongoDB、Redis。
pip install pymysql
pip install pymongo
pip install redis复制
在字段比较多的时候推荐使用ORM来操作数据。
ORM概念:用来把对象模型表示的对象映射到基于S Q L 的关系模型数据库结构中去。这样,我们在具体的操作实体对象的时候,就不需要再去和复杂的 SQ L 语句打交道,只需简单的操作实体对象的属性和方法。
ORM框架推荐:SQLAlchemy
常见的反爬手段和解决方法
1、反爬虫领域常见的一些概念
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式,关键也在于批量 误伤:在反爬虫的过程中,错误的将普通用户识别为爬虫。误伤率高的反爬虫策略,效果再好也不能用。 拦截:成功地阻止爬虫访问。这里会有拦截率的概念。通常来说,拦截率越高的反爬虫策略,误伤的可能性就越高。因此需要做个权衡。 资源:机器成本与人力成本的总和。
2、反爬的三个方向
基于身份识别进行反爬。 基于爬虫行为进行反爬。 基于数据加密进行反爬。
3、常见基于身份识别进行反爬
3.1、通过headers字段来反爬。headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫。
通过headers字段来反爬。通过headers中的User-Agent字段来反爬 反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置,而浏览器访问服务器的时候是带有User-Agent的。 解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)。 通过referer字段或者是其他字段来反爬。 反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法。 解决方法:添加referer字段。 通过cookie来反爬。 反爬原理:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬。 解决方案:进行模拟登陆,成功获取cookies之后在进行数据爬取。
3.2、通过请求参数来反爬
通过发送请求获取请求数据。 反爬原理:通过增加获取请求参数的难度进行反爬。 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系,弄清楚请求参数来源。 通过js生成请求参数。 反爬原理:在请求过程中JS生成一个参数,大多数情况下和时间戳有关,这就导致每次请求,这个参数值都不一样。 解决方案:破解JS加密过程。 通过验证码来反爬。 反爬原理:对方服务器通过弹出验证码强制验证用户浏览行为。 解决方案:打码平台或者是机器学习的方法识别验证码。
4、常见基于爬虫行为进行反爬
4.1、基于请求频率或总请求数量
通过请求ip/账号单位时间内总请求数量进行反爬。 反爬原理:正常浏览器请求网站,速度不会太快,同一个ip/账号大量请求了对方服务器,有更大的可能性会被识别为爬虫 解决方法:对应的通过购买高质量的ip的方式能够解决问题/购买个多账号 通过同一ip/账号请求之间的间隔进行反爬。 反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间时间间隔通常比较固定同时时间间隔较短,因此可以用来做反爬。 解决方法:请求之间进行随机等待,模拟真实用户操作,在添加时间间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠。 通过对请求ip/账号每天请求次数设置阈值进行反爬。 反爬原理:正常的浏览行为,其一天的请求次数是有限的,通常超过某一个值,服务器就会拒绝响应。 解决方法:对应的通过购买高质量的ip的方法/多账号,同时设置请求间随机休眠。
4.2、基于爬取步骤设置反爬
通过js实现跳转来反爬。 反爬原理:js实现页面跳转,无法在源码中获取下一页url。 解决方法: 多次抓包获取条状url,分析规律 通过假数据反爬。 反爬原理:向返回的响应中添加假数据污染数据库。 解决方法:长期运行,核对数据库中数据同实际页面中数据对应情况,如果存在问题/仔细分析响应内容。 阻塞任务队列。 反爬原理:通过生成大量垃圾url,从而阻塞任务队列,降低爬虫的实际工作效率。 解决方法: 观察运行过程中请求响应状态/仔细分析源码获取垃圾url生成规则,对URL进行过滤。 阻塞网络IO。 反爬原理:发送请求获取响应的过程实际上就是下载的过程,在任务队列中混入一个大文件的url,当爬虫在进行该请求时将会占用网络io,如果是有多线程则会占用线程。 解决方法: 观察爬虫运行状态/多线程对请求线程计时。
5、常见基于数据加密进行反爬
5.2、对响应中含有的数据进行特殊化处理
通过自定义字体来反爬 反爬思路: 使用自有字体文件 解决思路:切换到手机版/解析字体文件进行翻译 通过css来反爬 反爬思路:源码数据不为真正数据,需要通过css位移才能产生真正数据 解决思路:计算css的偏移 通过js动态生成数据进行反爬 反爬原理:通过js动态生成。 解决思路:解析关键js,获得数据生成流程,模拟生成数据。
推荐一个自动生成代码的工具:curl(https://curl.trillworks.com/)
文章转载自零点小思随笔,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
