




MySQL总结
1.增删改查基本语句
1.1 select语句
select * from emp where ... group by... having ... order by...
1.2 连接查询
内连接
select e.ename, e.sal, d.dname from emp e inner join dept d on e.deptno = d.deptno where e.sal > 2000;
左外连接
select e.ename, e.sal, d.dname from e right join dept d on e.deptno = d.deptno;
右外连接
select e.ename, e.sal, d.dname from e right join dept d on e.deptno = d.deptno;
*内连接,左外连接,右外连接的区别
内连接要求必须有筛选条件,并且两个表的比较字段的数据量必须是相同的。如果两边有一个不存在,那么不显示查询结果。
左外连接和右外连接没有上述要求,它们是选择一个主表进行比较。左连接以左边的表为准和右边的表比较,和左边相等的不相等的都会显示出来,右表符合条件的显示,不符合条件的不显示。右连接恰恰相反。
1.3 子查询
select empno, ename from emp where empno in(select mgr from emp where mgr is not null);
在from
语句中使用子查询,可以将该子查询看做是一张表。
select e.empno, e.ename from emp e join(select distinct mgr from emp where mgr is not null)m on e.empno = m.mgr;
1.4 insert语句
insert into 表名(字段...) values(值...)
注意主键的唯一性,插入的时候保证主键不能重复
1.5 update/alert语句
update
属于DML(数据查询语句)
update 表名 set 字段名称1 = 需要修改的值, 字段名称2 = 需要修改的值2 where...
alert
增加删除修改表结构,不影响表中的数据
alert ... add ...
1.6 常见约束
非空约束 not null
唯一约束 unique
主键约束 primary key
外键约束 foreign key
*主键约束和外键约束
每个表都应该有主键,主键用来记录唯一性,单一主键由一个字段构成,复合主键由多个字段构成。只要不是复合主键每个值都重复,就不算重复。
外键用于维护表之间的关系,主要是为了保证参照完整性。如果表中的某个字段为外键字段,那么该字段的值必须来自于参照的表的主键。存在外键的表就是子表,参照表就是父表,所以存在一个父子关系,也就是主从关系。
2.索引
2.1 存储引擎
MyISAM引擎
特征:
——使用三个文件表示每个表
格式文件——存储表结构的定义
数据文件——存储表行的内容
索引文件——存储表上索引
——灵活的AUTO_INCREMENT 字段处理
——可被转换为压缩,只读表来节省空间
不支持事务,不支持外键,表级锁,支持的索引类型:全局索引,B-Tree,R-Tree,采用非聚簇索引,索引文件的数据域存储指向数据文件的指针。辅索引和主索引基本一致,但是辅助索引不保证唯一性。
InnoDB引擎
每个 InnoDB 表在数据库目录中以.frm 格式文件表示 InnoDB 表空间 tablespace 被用于存储表的内容 提供一组用来记录事务性活动的日志文件 用 COMMIT(提交)、SAVEPOINT 及 ROLLBACK(回滚)支持事务处理 提供全 ACID 兼容 在 MySQL 服务器崩溃后提供自动恢复 多版本(MVCC)和行级锁定 支持外键及引用的完整性,包括级联删除和更新 聚簇索引,辅索引的数据域存储主键的值
Memory引擎
在数据库目录内,每个表均以.frm 格式的文件表示。 表数据及索引被存储在内存中。 表级锁机制。 不能包含 TEXT 或 BLOB 字段。
*选择合适的存储引擎
MyISAM表适合于大量的数据读而少量数据更新的混合操作,可使用压缩的只读表。
InnoDB适合较多数据更新。它使用行锁机制,提供了良好的并发机制。
Memory存储非永久需要的数据,或者能够从基于磁盘的表中重新生成的数据。
2.2 索引分类
全局索引(FULLTEXT)
:全局索引,目前只有 MyISAM 引擎支持全局索引,它的出现是为了解决针对文本的模糊查询效率较低的问题,并且只限于 CHAR、VARCHAR 和 TEXT 列。哈希索引(HASH)
:哈希索引是 MySQL 中用到的唯一 key-value 键值对的数据结构,很适合作为索引。HASH 索引具有一次定位的好处,不需要像树那样逐个节点查找,但是这种查找适合应用于查找单个键的情况,对于范围查找,HASH 索引的性能就会很低。默认情况下,MEMORY 存储引擎使用 HASH 索引,但也支持 BTREE 索引。B-Tree 索引
:B 就是 Balance 的意思,BTree 是一种平衡树,它有很多变种,最常见的就是 B+ Tree,它被 MySQL 广泛使用。R-Tree 索引
:R-Tree 在 MySQL 很少使用,仅支持 geometry 数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种,相对于 B-Tree 来说,R-Tree 的优势在于范围查找。从逻辑上来分:
普通索引,唯一索引,主键索引,组合索引(指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀原则),全文索引
关于锁:https://blog.csdn.net/weixin_39651041/article/details/79985715
*索引失效的情况
如果使用索引后比不使用索引的效率还差,那么 MySQL 就不会使用索引。
如果 SQL 中使用了 OR 条件,OR 前的条件列有索引,而后面的列没有索引的话,那么涉及到的索引都不会使用。
explain select * from emp where sno = '111' and cid = '01';如果sno字段使用了索引而cid未使用索引的话,索引失效。
索引列参与了运算,函数计算,模糊查询(like函数的第一个字符为%),隐式转换,is not null 索引失效
复合索引
最左前缀特性(底层B+Tree从左往右优先排序):必须使用复合索引的第一个字段
*聚簇索引和非聚簇索引
聚簇索引是按照每张表的主键构造一颗B+数,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页,这个特性决定了索引组织表中的数据也是索引的一部分,每张表只能拥有一个聚簇索引。InnoDB通过主键聚集数据,如果没有主键,InnoDB会选择非空的唯一索引代替。如果没有这样的索引,InnoDB会隐式的定义一个主键来作为聚簇索引。
聚簇索引优点:
数据访问快,支持索引覆盖; 聚簇索引对于主键的排序查找和范围查找速度非常快;
聚簇索引缺点:
插入速度严重依赖于插入顺序,按照主键的顺序插入最快,否则会出现页分裂,严重影响性能。
更新主键的代价很高,因为将导致被更新的行移动。
二级索引需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
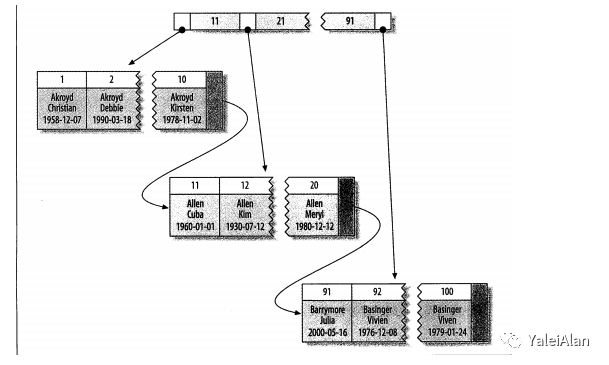
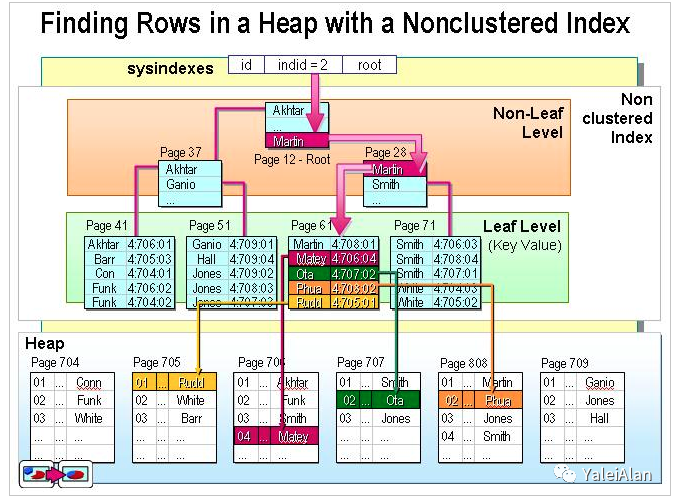
非聚簇索引在聚簇索引之上进行创建。辅助索引叶子节点存储的不再是行的物理位置而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页。
3. 事务
事务保证批量的 DML 要么全成功,要么全失败。
事务特性:原子性,隔离性,一致性,持久性(ACID):
原子性由undo log日志保证,它记录了需要回滚的日志信息事务回滚时撤销已经成功的sql
一致性由其他三特性保证
隔离性由MVCC保证
持久性由内存和redo log保证,宕机的时候可以有redo log恢复操作
*什么是MVCC?
多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁和写锁就不冲突了,不同的事务session会看到自己特定版本的数据,版本链
MVCC只在READ committed和repeatable read两个隔离级别下进行工作,read uncommited总是读取最新的行,而不是符合当前事务版本的数据行。而serializable则会对所有读取的行都加锁。
聚簇索引记录中两个必要的隐藏列:
trx_id:用来存储每次对某条聚簇索引记录进行修改的时候的事务id
Roll_pointer:存储一个指针,指向上一个版本的位置,通过它来获取上一个版本的记录信息。
开启事务,回滚事务,提交事务,set autocommit
事务的隔离级别:
脏读取:一个事务开始读取了某行数据,但是另外一个事务已经更新了此数据但没有能够及时提交,这就出现了脏读取。
不可重复读:在同一个事务中,同一个读操作对同一个数据的前后两次读取产生了不同的结果,这就是不可重复读。
幻象读:幻像读是指在同一个事务中以前没有的行,由于其他事务的提交而出现的新行。

4. 视图
视图相当于一个窗口。从窗口可以看到内部数据库。
数据库第一范式:数据库表中不能出现重复记录,每个字段是原子性的不能再分。
第二范式:第二范式是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖
第三范式:建立在第二范式基础上的,非主键字段不能传递依赖于主键字段。
5.数据库调优
explain查看语句的执行情况

ID:查询顺序号
select_type:select子句的类型
table:表名
type:优化sql的重要字段,判断sql性能和优化程度的重要指标
const:一次命中 system:表中只有一行数据 Eq_ref:唯一性索引扫描,对于每个索引值有唯一记录 ref:非唯一性索引扫描 range:检索范围 index:只遍历索引树 All:全表扫描
Possible_key:可能会用到的索引
key_len:索引字段长度
key:使用的索引
rows:估算sql返回结果集需要扫描读取的行数
filtered:返回查询到的行所占总行的百分比
extra:几种排序方式
insert的优化:向同一张表中插入多条数据,最好一次性插入,减少数据库连接和断开的时间
最好将索引和数据文件在不同的磁盘上存放
MySQL支持两种方式的排序,filesort(文件排序)和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。 使用count的时候注意它默认不会统计NULL值。 查询时,尽量使用查询的字段名。
MySQL总结
1.增删改查基本语句
1.1 select语句
select * from emp where ... group by... having ... order by...
1.2 连接查询
内连接
select e.ename, e.sal, d.dname from emp e inner join dept d on e.deptno = d.deptno where e.sal > 2000;
左外连接
select e.ename, e.sal, d.dname from e right join dept d on e.deptno = d.deptno;
右外连接
select e.ename, e.sal, d.dname from e right join dept d on e.deptno = d.deptno;
*内连接,左外连接,右外连接的区别
内连接要求必须有筛选条件,并且两个表的比较字段的数据量必须是相同的。如果两边有一个不存在,那么不显示查询结果。
左外连接和右外连接没有上述要求,它们是选择一个主表进行比较。左连接以左边的表为准和右边的表比较,和左边相等的不相等的都会显示出来,右表符合条件的显示,不符合条件的不显示。右连接恰恰相反。
1.3 子查询
select empno, ename from emp where empno in(select mgr from emp where mgr is not null);
在from
语句中使用子查询,可以将该子查询看做是一张表。
select e.empno, e.ename from emp e join(select distinct mgr from emp where mgr is not null)m on e.empno = m.mgr;
1.4 insert语句
insert into 表名(字段...) values(值...)
注意主键的唯一性,插入的时候保证主键不能重复
1.5 update/alert语句
update
属于DML(数据查询语句)
update 表名 set 字段名称1 = 需要修改的值, 字段名称2 = 需要修改的值2 where...
alert
增加删除修改表结构,不影响表中的数据
alert ... add ...
1.6 常见约束
非空约束 not null
唯一约束 unique
主键约束 primary key
外键约束 foreign key
*主键约束和外键约束
每个表都应该有主键,主键用来记录唯一性,单一主键由一个字段构成,复合主键由多个字段构成。只要不是复合主键每个值都重复,就不算重复。
外键用于维护表之间的关系,主要是为了保证参照完整性。如果表中的某个字段为外键字段,那么该字段的值必须来自于参照的表的主键。存在外键的表就是子表,参照表就是父表,所以存在一个父子关系,也就是主从关系。
2.索引
2.1 存储引擎
MyISAM引擎
特征:
——使用三个文件表示每个表
格式文件——存储表结构的定义
数据文件——存储表行的内容
索引文件——存储表上索引
——灵活的AUTO_INCREMENT 字段处理
——可被转换为压缩,只读表来节省空间
不支持事务,不支持外键,表级锁,支持的索引类型:全局索引,B-Tree,R-Tree,采用非聚簇索引,索引文件的数据域存储指向数据文件的指针。辅索引和主索引基本一致,但是辅助索引不保证唯一性。
InnoDB引擎
每个 InnoDB 表在数据库目录中以.frm 格式文件表示 InnoDB 表空间 tablespace 被用于存储表的内容 提供一组用来记录事务性活动的日志文件 用 COMMIT(提交)、SAVEPOINT 及 ROLLBACK(回滚)支持事务处理 提供全 ACID 兼容 在 MySQL 服务器崩溃后提供自动恢复 多版本(MVCC)和行级锁定 支持外键及引用的完整性,包括级联删除和更新 聚簇索引,辅索引的数据域存储主键的值 Memory引擎
在数据库目录内,每个表均以.frm 格式的文件表示。 表数据及索引被存储在内存中。 表级锁机制。 不能包含 TEXT 或 BLOB 字段。
*选择合适的存储引擎
MyISAM表适合于大量的数据读而少量数据更新的混合操作,可使用压缩的只读表。
InnoDB适合较多数据更新。它使用行锁机制,提供了良好的并发机制。
Memory存储非永久需要的数据,或者能够从基于磁盘的表中重新生成的数据。
2.2 索引分类
全局索引(FULLTEXT)
:全局索引,目前只有 MyISAM 引擎支持全局索引,它的出现是为了解决针对文本的模糊查询效率较低的问题,并且只限于 CHAR、VARCHAR 和 TEXT 列。哈希索引(HASH)
:哈希索引是 MySQL 中用到的唯一 key-value 键值对的数据结构,很适合作为索引。HASH 索引具有一次定位的好处,不需要像树那样逐个节点查找,但是这种查找适合应用于查找单个键的情况,对于范围查找,HASH 索引的性能就会很低。默认情况下,MEMORY 存储引擎使用 HASH 索引,但也支持 BTREE 索引。B-Tree 索引
:B 就是 Balance 的意思,BTree 是一种平衡树,它有很多变种,最常见的就是 B+ Tree,它被 MySQL 广泛使用。R-Tree 索引
:R-Tree 在 MySQL 很少使用,仅支持 geometry 数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种,相对于 B-Tree 来说,R-Tree 的优势在于范围查找。从逻辑上来分:
普通索引,唯一索引,主键索引,组合索引(指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀原则),全文索引
关于锁:https://blog.csdn.net/weixin_39651041/article/details/79985715
*索引失效的情况
*聚簇索引和非聚簇索引
聚簇索引是按照每张表的主键构造一颗B+数,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页,这个特性决定了索引组织表中的数据也是索引的一部分,每张表只能拥有一个聚簇索引。InnoDB通过主键聚集数据,如果没有主键,InnoDB会选择非空的唯一索引代替。如果没有这样的索引,InnoDB会隐式的定义一个主键来作为聚簇索引。
聚簇索引优点:
聚簇索引缺点:
非聚簇索引在聚簇索引之上进行创建。辅助索引叶子节点存储的不再是行的物理位置而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页。
最左前缀特性(底层B+Tree从左往右优先排序):必须使用复合索引的第一个字段 如果使用索引后比不使用索引的效率还差,那么 MySQL 就不会使用索引。
如果 SQL 中使用了 OR 条件,OR 前的条件列有索引,而后面的列没有索引的话,那么涉及到的索引都不会使用。
explain select * from emp where sno = '111' and cid = '01';如果sno字段使用了索引而cid未使用索引的话,索引失效。
索引列参与了运算,函数计算,模糊查询(like函数的第一个字符为%),隐式转换,is not null 索引失效
复合索引
插入速度严重依赖于插入顺序,按照主键的顺序插入最快,否则会出现页分裂,严重影响性能。
更新主键的代价很高,因为将导致被更新的行移动。
二级索引需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
数据访问快,支持索引覆盖; 聚簇索引对于主键的排序查找和范围查找速度非常快;
3. 事务
事务保证批量的 DML 要么全成功,要么全失败。
事务特性:原子性,隔离性,一致性,持久性(ACID):
原子性由undo log日志保证,它记录了需要回滚的日志信息事务回滚时撤销已经成功的sql
一致性由其他三特性保证
隔离性由MVCC保证
持久性由内存和redo log保证,宕机的时候可以有redo log恢复操作
*什么是MVCC?
多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁和写锁就不冲突了,不同的事务session会看到自己特定版本的数据,版本链
MVCC只在READ committed和repeatable read两个隔离级别下进行工作,read uncommited总是读取最新的行,而不是符合当前事务版本的数据行。而serializable则会对所有读取的行都加锁。
聚簇索引记录中两个必要的隐藏列:
trx_id:用来存储每次对某条聚簇索引记录进行修改的时候的事务id
Roll_pointer:存储一个指针,指向上一个版本的位置,通过它来获取上一个版本的记录信息。
开启事务,回滚事务,提交事务,set autocommit
事务的隔离级别:
脏读取:一个事务开始读取了某行数据,但是另外一个事务已经更新了此数据但没有能够及时提交,这就出现了脏读取。
不可重复读:在同一个事务中,同一个读操作对同一个数据的前后两次读取产生了不同的结果,这就是不可重复读。
幻象读:幻像读是指在同一个事务中以前没有的行,由于其他事务的提交而出现的新行。
4. 视图
视图相当于一个窗口。从窗口可以看到内部数据库。
数据库第一范式:数据库表中不能出现重复记录,每个字段是原子性的不能再分。
第二范式:第二范式是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖
第三范式:建立在第二范式基础上的,非主键字段不能传递依赖于主键字段。
5.数据库调优
explain查看语句的执行情况

ID:查询顺序号
select_type:select子句的类型
table:表名
type:优化sql的重要字段,判断sql性能和优化程度的重要指标
Possible_key:可能会用到的索引
key_len:索引字段长度
key:使用的索引
rows:估算sql返回结果集需要扫描读取的行数
filtered:返回查询到的行所占总行的百分比
extra:几种排序方式
const:一次命中 system:表中只有一行数据 Eq_ref:唯一性索引扫描,对于每个索引值有唯一记录 ref:非唯一性索引扫描 range:检索范围 index:只遍历索引树 All:全表扫描 insert的优化:向同一张表中插入多条数据,最好一次性插入,减少数据库连接和断开的时间
最好将索引和数据文件在不同的磁盘上存放
MySQL支持两种方式的排序,filesort(文件排序)和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。 使用count的时候注意它默认不会统计NULL值。 查询时,尽量使用查询的字段名。
