




去年在公司碰到过一个问题:MySQL的一个表已经创建好索引了,但是查询的时候,并没有走索引,而是全表扫描的,这时候,真非常懵圈,为什么会这样呢?这是MySQL的bug,一定是!我赶紧去提交一波bug!后来经过dba的一顿神仙操作,终于知道的问题的所在了,索引建的不好,垃圾冗余索引太多,MySQL的优化器认为全表扫描比走索引要快。经过一顿问,查资料,终于知道了!下面我就来讲一下。
一、MySQL到底是如何选择索引的
这里我有一个数据表:
CREATE TABLE `test` (`a` int NOT NULL,`b` int NOT NULL,`c` char(1) NOT NULL,`d` decimal(15,2) NOT NULL,`e` char(15) NOT NULL,PRIMARY KEY (`a`),KEY `index1` (`b`,`d`),KEY `index2` (`b`),KEY `index3` (`b`,`d`,`b`)) ENGINE=InnoDB复制
在查询字段b的时候,理论上可以使用3个索引,index1,index2,index3。那么MySQL优化器是怎么从三个索引中进行选择的呢?
MySQL中,大家都知道我们用的B+树当数据结构,但是怎么使用,还是需要依赖数据库的优化器。
二、优化器是如何选择的呢?
优化器的选择是基于cost,哪个索引的成本越低,优先使用哪个索引
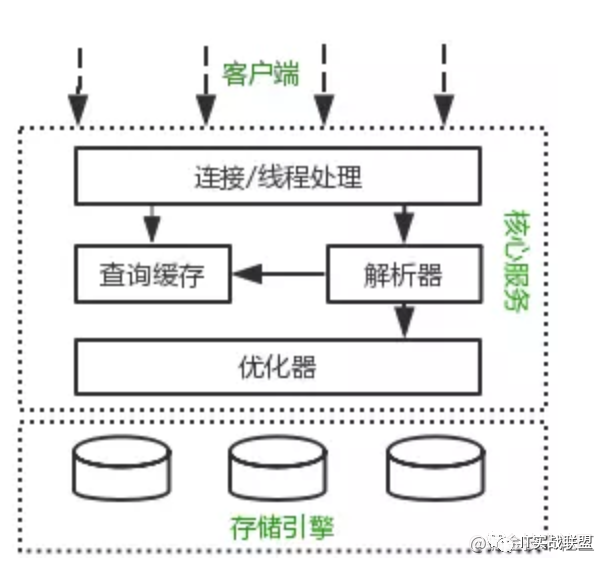
大家学过MySQL的执行流程都知道数据库是由上图这几部分组成,也就是Server层和引擎层(如:InnoDB,MyISAM...)。Server层负责解析,优化,执行等,负责SQL语句的具体执行过程。引擎层负责存储具体的数据,还有用于在内存中存储临时结果集的TempTable引擎。
SQL优化器会分析所有可能执行计划,选择一个成本最低的执行,这种优化器称之为CBO(Cost-based Optimizer,基于成本的优化器)
一条SQL的计算成本:Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
其中,CPU Cost是计算的开销,比如索引键值的比较,记录值的比较,结果集的排序等。
IO Cost表示引擎层的IO的开销,MySQL8.0可以通过区分一张表的数据是否在内存中,分别计算读取内存IO开销以及读取磁盘IO的开销。
我们可以查询一下Server Cost和Engine Cost
select * from mysql.server_cost复制
复制
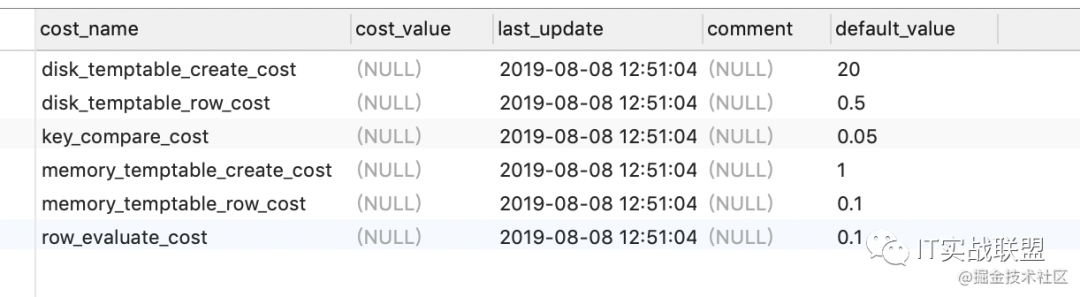 含义如下:
含义如下:
disk_temptable_create_cost:创建磁盘临时表的成本,默认为20。
disk_temptable_row_cost:磁盘临时表中每条记录的成本,默认为0.5。
key_compare_cost:索引键值比较的成本,默认为0.05,成本最小。
memory_temptable_create_cost:创建内存临时表的成本:默认为1。
memory_temptable_row_cost:内存临时表中每条记录的成本,默认为0.1。
row_evaluate_cost:记录间的比较成本,默认为0.1。
这里我们可以看到,MySQL优化器认为如果一条SQL需要创建基于磁盘的临时表,则成本是最大的,其成本是基于内存临时表的20倍。而索引键值的比较,记录之间的比较,其实开销是非常低的,单如果要比较的记录数比较多,则成本会变得非常大。
而表engine_const记录了存储引擎各种操作的成本,这里包括了所有IO Cost
select * from mysql.engine_cost复制
复制
 含义如下:
含义如下:
io_block_read_cost:从磁盘读取一个页的成本,默认值为1。
memory_block_read_cost:从内存读取一个页的成本,默认值为0.25。
所以,从磁盘读取的开销是内存开销的4倍。
这里我们通过EXPLAIN FORMAT=json可以开启查看各个成本的值
EXPLAIN FORMAT=jsonselect * from user{"query_block": {"select_id": 1,"cost_info": {"query_cost": "1052378.90"},"table": {"table_name": "user","access_type": "index","key": "sindex","used_key_parts": ["uname","pwd","addr","tel","regtime","age"],"key_length": "528","rows_examined_per_scan": 9678349,"rows_produced_per_join": 9678349,"filtered": "100.00","using_index": true,"cost_info": {"read_cost": "84544.00","eval_cost": "967834.90","prefix_cost": "1052378.90","data_read_per_join": "4G"},"used_columns": ["id","uname","pwd","addr","tel","regtime","age"]}}}复制
复制
read_cost 表示就是从 InnoDB 存储引擎读取的开销;
eval_cost 表示 Server 层的 CPU 成本;
prefix_cost 表示这条 SQL 的总成本;
data_read_per_join 表示总的读取记录的字节数。
所以,到这里,我们应该都知道,MySQL是如何选择索引了。回到开头,为什么我们的查询会全表扫描呢?因为索引创建的并不是很好,而且冗余索引创建的太多,比如创建了一个联合索引(a,b,c)但是我查询条件是a=?and c=?这时候,走到索引只能走到a这个字段,而且由于查询列还有比如d,e,f,所以我们就需要回表查询。这样MySQL优化器通过计算,认为二级索引回表查询(当回表的记录数非常大时)比全表查询成本要高。所以选择全表查询。
三、这里我们需要如何优化呢?
这里先介绍一下冗余索引
什么是冗余索引?
MySQL允许在相同列上创建多个索引。比如创建index(a,b,c) index2(a,b),这其实就是冗余索引。创建冗余索引MySQL需要单独维护重复的索引,并且优化器查询优化的时候需要进行考虑,这是比较浪费性能的。
所以大多数情况下都不需要冗余索引,应该尽量去拓展已有的索引而不是创建新的索引。当然,事无绝对,如果一个索引变的太大,会导致影响其他索引的查询性能,这就需要去创建冗余索引。比如我们需要额外增加一个很长的varchar列来扩展字段的时候,这性能可能就比较低了,至于拓展索引还是创建新的索引,就需要自己去测试判断了,一般都是dba的活。而且绝大多数冗余的索引其实都是未使用的索引,这样的索引完全就是累赘,所以可以删除。可以使用Percona Toolkit中的pt-index-usage来读取查询日志,并对日志中的每条查询进行EXPLAIN操作,然后打印出关于索引和查询的报告。这样就可以找出哪个索引是未使用的,从而进行删除。
所以,这里我们dba去查询出发现冗余索引特别多,进行删除,同时因为用到的索引创建的也有问题,进行索引优化,扩展索引从而解决了这个问题。
作者:Five在努力
链接:https://juejin.cn/post/7001078247521779742
感谢您抽出

.

.

阅读本文


