




大家好!
前文回顾:Pandas案例精进 | 自动分割汇总表写入到子表中
本文是承接上一篇的实战案例,没看过的小伙伴建议先点击👆上方链接查看前文
Pandas案例需求
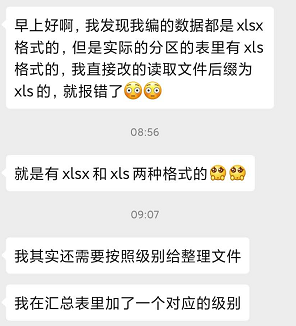
现在的新需求跟之前的区别有:
汇总表多了级别字段,需要根据不同的级别对应不同的文件夹:
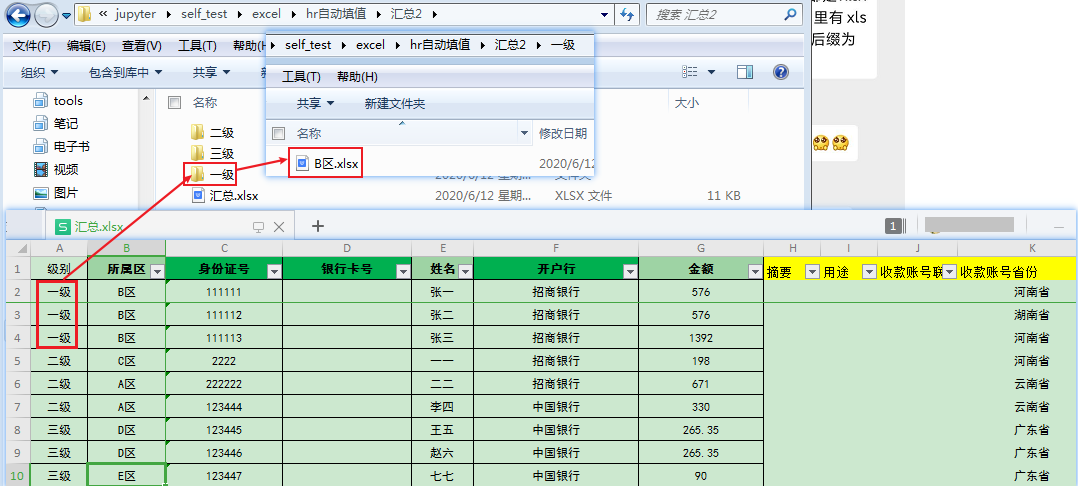
所属区的xlsx文件有时可能是xls,并不一定是xlsx的。
各级别文件夹中存在一些不能匹配汇总表的垃圾文件需要删除。
汇总表中所有的对应项目并不是都在级别文件夹中存在,不存在的只提示哪些不存在,无需额外处理。
下面是我的实现过程:
数据加载
import os
import pandas as pd
excel_dir = os.getcwd()
data = pd.read_excel(f"{excel_dir}/汇总.xlsx", sheet_name='明细')
data复制
本文直接设置excel_dir
为工作目录,大家如果代码和数据不在同一文件夹,可以根据自己的情况更改设置文件路径。
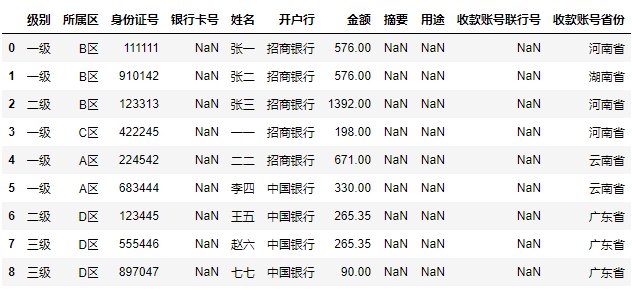
遍历计算出每级别所涉及的区
level_areas = {}
for i, row in data.iterrows():
areas = level_areas.setdefault(row['级别'], set())
areas.add(row['所属区'])
level_areas复制
执行结果
{'一级': {'B区'}, '二级': {'A区', 'C区'}, '三级': {'D区', 'E区'}}复制
删除多余文件+转换xls
这里会用到win32com.client
库,需要额外安装。
pip install pywin32复制
也可使用国内清华源来加快Python库的安装速度。
pip install pywin32 -i https://pypi.tuna.tsinghua.edu.cn/simple复制
安装后使用
import win32com.client as win32
for level in data['级别'].unique():
areas = level_areas[level]
files = os.listdir(f"{excel_dir}/{level}")
for file in files:
tag = file.replace(".xlsx", "").replace(".xls", "")
filename = f"{excel_dir}/{level}/{file}"
if not tag in areas:
print(f"删除文件:{filename}")
os.remove(filename)
elif file.endswith(".xls"):
print(f"将 {filename} 转换为 {filename}x")
excel = win32.gencache.EnsureDispatch('Excel.Application')
try:
wb = excel.Workbooks.Open(filename)
wb.SaveAs(f"{filename}x", FileFormat=51) #FileFormat = 51 is for .xlsx extension
print("转换成功")
finally:
wb.Close() #FileFormat = 56 is for .xls extension
excel.Application.Quit()
os.remove(filename)复制
上述代码可以实现删除级别文件夹多余的文件并将xls转换为xlsx。
比如将 一级/B区.xls
转换为 一级/B区.xlsx
注意:使用pywin32转换excel文件格式时,绝对路径的盘符后面的分隔符必须是反斜杠\,后面的路径分隔符用正斜杠或反斜杠都可以。
遍历出级别和区域
for (level, area), df in data.groupby(['级别', '所属区']):
print(level, area)
df = df.iloc[:, 2:]
display(df)复制
执行结果

写出结果
最后,利用openpyxl
库将结果分别写入各级别、各Excel文件中。
from openpyxl import load_workbook
for (level, area), df in data.groupby(['级别', '所属区']):
print(level, area)
df = df.iloc[:, 2:]
out_file_name = f"{excel_dir}/{level}/{area}.xlsx"
if not os.path.exists(out_file_name):
print(out_file_name, "文件不存在,跳过")
continue
print("准备写出到:", out_file_name)
workbook = load_workbook(filename=out_file_name)
sheet = workbook.active
# 先删除第4行之后的旧数据,预计1000行完全够用
sheet.delete_rows(idx=4, amount=1000)
# 然后再进行添加数据
for row in df.values.tolist():
sheet.append(row)
print(row)
print(f"保存到{out_file_name}文件中")
workbook.save(filename=out_file_name)
workbook.close()复制

小结
估计有朋友觉得本文为了处理几个Excel写了这么多行代码,也没看出来有啥效果。
但是上面只是示例数据,而群友真正工作要处理的数据有几百个文件夹,用代码处理的优势一下子就体现出来了。
不如看看反馈吧:
文章转载自泰迪教育,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1245次阅读
2025-04-27 16:53:22
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
727次阅读
2025-04-30 15:24:06
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
590次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
503次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
475次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
470次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
360次阅读
2025-04-18 10:01:22
给准备学习国产数据库的朋友几点建议
白鳝的洞穴
277次阅读
2025-05-07 10:06:14
国产数据库图谱又上新|82篇精选内容全览达梦数据库
墨天轮编辑部
273次阅读
2025-04-23 12:04:21
XCOPS广州站:从开源自研之争到AI驱动的下一代数据库架构探索
韩锋频道
270次阅读
2025-04-29 10:35:54
