




#发现之前没有推送过这篇文章,只在菜单展示过,看过的同学可以略过了。非常欢迎大家留言交流。
1、Hadoop 1.x架构
Hadoop1.x序列版本中,HDFS持续维持单NameNode多dataNode架构,主要具有两个功能:命名空间管理(Namespace)和块存储管理(Block Storage)服务。
其中命名空间管理主要维护了这个文件系统的目录树结构Namespace;块存储管理分为Block Management和Physical Storage,Block Management主要维护从Block到DataNode的映射关系,Physical Storage是数据的物理存储管理。Namespace和BlockManagement由NameNode统一维护,这部分称为metadata;Physical Storage分发到多个DataNode进行分布式管理。
Namespace:
支持对目录树的增删改查更新功能;
Block Storage:
处理DataNode向NameNode注册的请求,维护DataNode列表,处理DataNode周期性心跳;
处理来自DataNode的块汇报信息,维护块的位置信息;
处理与块的增删改查;
管理副本放置策略及块复制和删除;
物理存储,DataNode本地文件系统对块数据管理,进行本地文件系统读写。
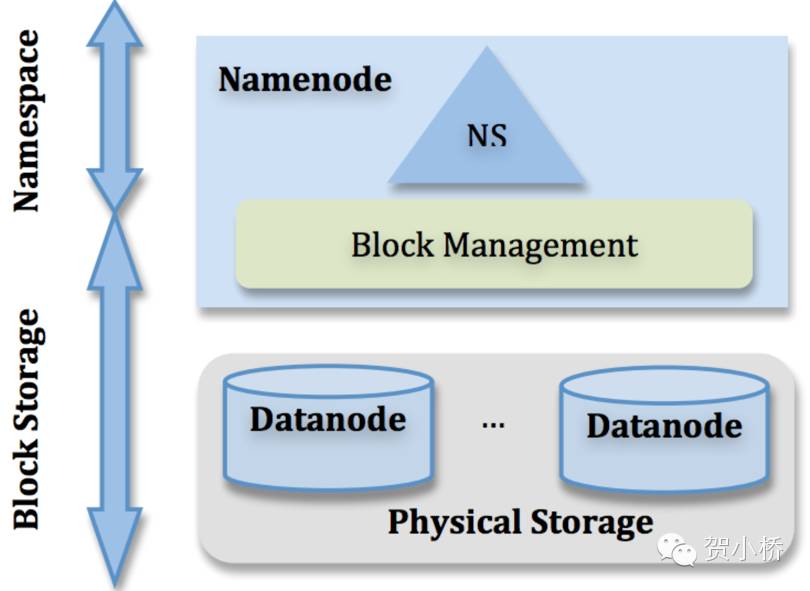
图1 HDFS1架构图示
Hadoop1.x序列版本,在整个HDFS架构中,仅存在单一命名空间,由单独NameNode管理,负责对单独命名空间进行统一管理。NameNode在整个HDFS中起到核心作用,虽然改进架构里引入了对NameNode的冷备(Secondary NameNode)和HA/热备(Standby NameNode),但是NameNode本身功能的复杂及元数据的集中式管理模式始终存在,也是NameNode单点失效SPOF的隐患所在。
2、Hadoop 1.x存在的问题
2.1 Hadoop 1.x制约因素
正如前面所述,由于NameNode在内存中维护了所有元数据metadata,因此单个NameNode所能存储对象数目受NameNode所在JVM的Heap Size限制。从Hortonworks的信息看:
A typical large deployment at Yahoo! includes an HDFS cluster with 2700-4200 datanodes with 180 million files and blocks, and address ~25 PB of storage.
At Facebook, HDFS has around 2600 nodes, 300 million files and blocks, addressing up to 60PB of storage.
从Yahoo!和Facebook的数据来看,Heap占用在50G~80G。
随着集群规模增长和数据积累,Heap占用会持续增长,此时NameNode的SPOF问题会愈发突出。主要表现在:
扩展性:主要受NameNode单点Heap Size物理限制,只能进行垂直扩展,集群规模和数据规模的持续增长一定使NameNode碰到天花板;(Heap)
性能:整个文件系统的读写请求处理能力强依赖单NameNode处理能力;(全局锁)
隔离性:单一对NameNode负载过高应用,会影响到整个集群的服务能力;(SPOF)
可用性:主要表现在SPOF问题。当前HDFS HA方案(QJM/NFS)目前看基本能够满足NameNode failover问题;启动时间长&Full GC风险依然存在。(元数据规模)
2.2 备选解决方案
从扩展性角度看,两种可能的备选方案可以解决Hadoop 1.x存在的诸多问题:
NameNode垂直扩展;
NameNode水平扩展;
其中继续增加Heap Size对NameNode进行垂直扩展方案依然存在问题,主要表现在三个方面:
1、启动时间变长;
2、Namenode在Full GC时,如果发生错误将会导致整个集群宕机。
3、大JVM Heap调试困难,而优化Namenode的内存使用成本高收益少。
所以社区尝试通过NameNode水平扩展解决上面的问题,Federation应运而生。
3、Hadoop 2.x Federation方案特点
社区在发起解决NameNode扩展性问题起始,曾就包括Federation、分布式元数据管理(ceph/Lustre)等方案进行过讨论。最后决定选择Federation,主要还是基于其几个主要特点:
1、实现简单且能快速满足需求;
2、NameNode的所有特性不受影响,实现上几乎没有改动;
3、向后兼容,可以无缝支持Hadoop 1.x架构的配置;
除了社区federation方案外,业界也出现了各种自有的解决办法。
Baidu HDFS2将元数据管理通过主从架构的集群形式提供服务,本质上是将原生NameNode管理的Namespace和BlockManagement进行物理拆分,架构如图2所示。其中Namespace负责管理整个文件系统的目录树及文件到BlockID集合的映射关系,BlockID到DataNode的映射关系是按照一定的规则分到多个FMS分布式管理,这种方案与Lustre有相似之处(Hash-based Partition)。
优点:支持多命名空间,轻量命名空间管理,统一数据管理;
缺点:多增至少一次RPC带来的性能开销;
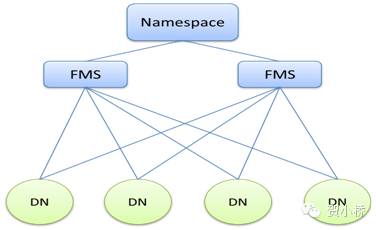
图2 Baidu HDFS2改进架构
Taobao HDFS2采用另外的思路,借助高速存储设备,将元数据通过外存设备进行持久化存储,保持NameNode完全无状态,实现NameNode无限扩展的可能性,架构如图3所示。
优点:扩展性非常好,快速启动,在线升级等;
缺点:性能损失代价高,尤其体现在元数据的读写操作从内存到持久化设备,复杂度高,运维成本高。
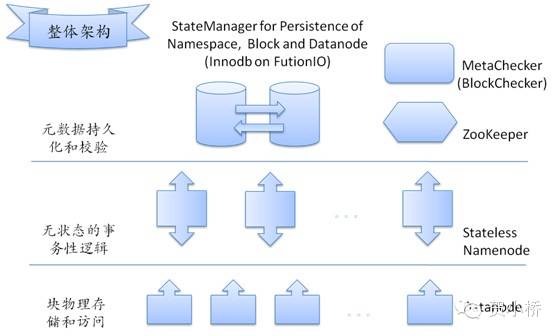
图3 Taobao HDFS2改进架构
其他对元数据分布式管理,如XFS;持久化存储管理,如元数据存储到HBase;这些方案大多大同小异,这里不再一一详述。
4、Federation架构
4.1 Federation
HDFS Federation使用了多个独立的NameNode/Namespace解决Hadoop 1.x中NameNode水平扩展问题。Namenode之间之间相互独立且相互无信息交互,每个NameNode提供独立Namespace和BlockManagement服务。DataNode被所有NameNode同时使用数据块存储。DataNode向集群中所有NameNode注册、周期性发送心跳、周期块信息汇报、处理来自所有NameNode指令,DataNode向不同NameNode的信息交互之间相互独立,互不影响。Federation架构如图4所示。
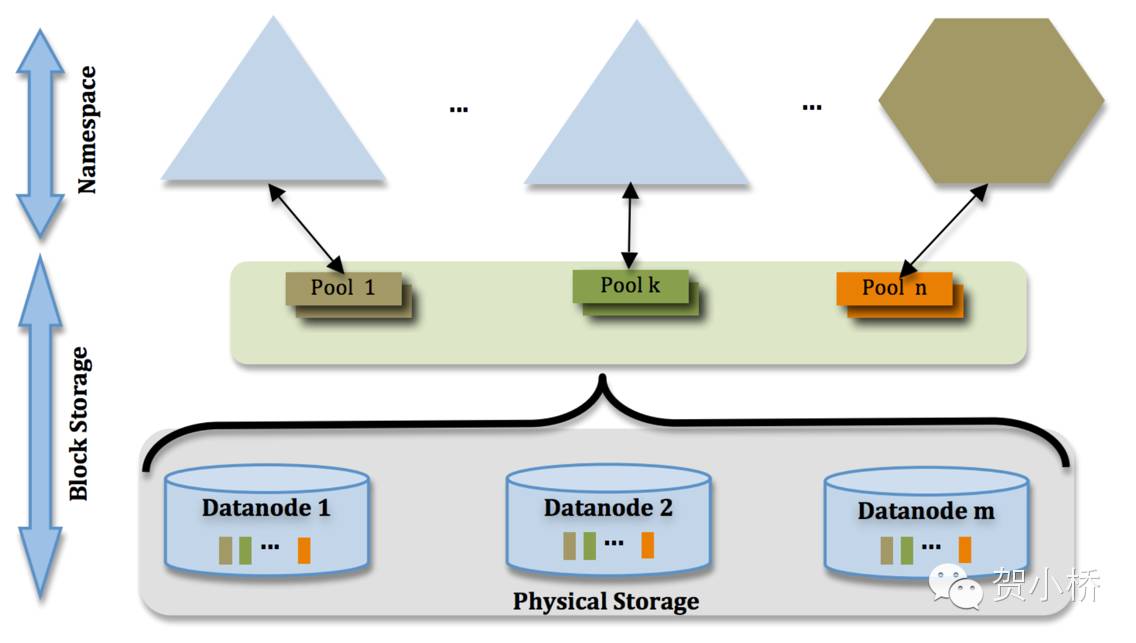
图4 HDFS2架构图示
从逻辑上看,Federation中命名空间和文件块管理还是由NameNode负责,DataNode负责文件块物理存储和访问,但是Federation允许在一个集群中运行多个NameNode,每个NameNode负责一个命名空间,每个命名空间拥有至少一个逻辑的BlockPool,命名空间和它所拥有的BlockPool统称为一个Namespace Volume。它是管理的基本单位,当一个NameNode/Namespace被删除后,其所有DataNode上对应的BlockPool也会被删除。当集群升级时,每个Namespace Volume作为一个基本单元进行升级。虽然这些命名空间从物理上看是共享集群中的DataNode,但是在每个DataNode上还是对每个命名空间的BlockPool进行了隔离的,而且DataNode需要向每个相关的NameNode进行汇报。采用Federation架构,集群失去了统一的命名空间管理,换来的是多个命名空间可自主升级的灵活性和降低集群整体不可用的风险。
BlockPool是属于单个命名空间的一组block。每一个DataNode为所有的BlockPool存储块。DataNode是一个物理概念,而BlockPool是一个重新将block划分的逻辑概念。同一个DataNode中可以存着属于多个BlockPool的多个块。BlockPool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建BlockID。同时,一个NameNode失效不会影响其下的DataNode为其他NameNode的服务。
当DataNode与NameNode建立联系并开始会话后自动建立BlockPool。每个block都有一个唯一标识,这个标识我们称之为扩展的块ID:ExtendedBlockId= BlockPoolID+BlockID。这个ID在HDFS全集群都是唯一。
DataNode中的数据结构都通过BlockPoolID索引,即DataNode中的Block,Storage等都需要通过BlockPoolID确定。
4.2 改进点
NameNode
与HDFS1相比,HDFS2对NameNode的改进非常有限,架构与HDFS1保持完全一致,为支持Federation仅增加几个ClusterID、BlockPoolID等全局信息,同时对Block进行了扩展,增加了对BlockPool的支持。
DataNode
与HDFS1中不同,HDFS2对DataNode进行了重点改进,DataNode中对应于每个NameNode都有相应的单独线程。每个DataNode会向每一个NameNode注册、周期性向所有的NameNode发送心跳、周期性汇报其所在的BlockPool的BlockReport。也是由于DataNode同所有的NameNode都会通过独立的线程各自进行交互,所以,单个NameNode的异常退出不会对DataNode或整个集群造成大面积影响。
Client
HDFS Federation为用户提供统一的全局HDFS访问入口,借鉴Linux提供了client-side mount table,这是通过一层新的文件系统viewfs实现的,它实际上提供了一种映射关系,将一个全局逻辑目录映射到具体的NameNode目录上,采用这种方式后,需要在客户端新增新的配置达到统一的全局访问入口。
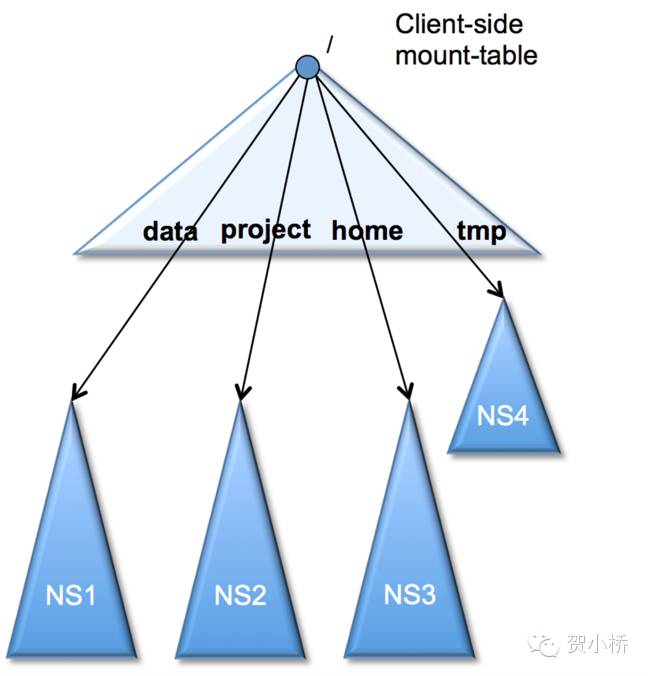
图5 client-side mount table
需要说明的是:从Namenode来看,本质上相当于多个集群共享了共同的存储资源,Federation暂不支持不同Namespace之间的rename操作,对上层应用影响面其实比较大,需要重点关注。
5、存在的问题
隔离问题:
Federation的一大特点是在不同Namespace之间实现了元数据的物理隔离,保证单个NameNode故障不会对整个集群造成全局故障。这就要求我们能够对目录进行合理划分,保证不同目录之间能够相互隔离。但是针对集群上数据规模和特点,尤其是数据仓库的量级和特点,要实现完全隔离难度非常大,需要提前对业务进行调研,合理划分目录结构进行隔离,避免不同Namespace之间出现数据交互的情况,尽可能做到对用户透明。
另外对于安全集群,当提交Job时社区原生实现是需要对多个NameNode进行安全认证后才能后续的操作,如果其中一个NameNode故障,即使不向其进行读写请求也不能正常提交,需要关注。
6、总结
经过几年的发展,Federation逐渐成熟和稳定,被广泛关注并已经在生产中被大量使用,随着集群规模和数据量的持续增长,我们也一定会面临对Federation的强需求,本文从Federation项目背景开始,简单介绍了Federation的架构、特点及与HDFS1相比新增的特性。
经过对Federation调研,从NameNode角度来看,不同Namespace的划分实际上和不同的Hadoop集群区别不大。需要重点关注不同Namespace之间rename操作暂不能支持,对实际应用的影响面其实非常大,需要提前对业务进行摸底,进行合理的目录切分,避免出现不同Namespace之间rename的强需求,或者能够对用户提供高效rename工具。理想目标是在提供Federation特性的同时能够对用户做到透明。
7、参考
[1] Apache Hadoop. https://hadoop.apache.org/.
[2] HDFS Federation. https://issues.apache.org/jira/browse/HDFS-1052.
[3] Federation Introduction. http://zh.hortonworks.com/blog/an-introduction-to-hdfs-federation/
[4] Baidu HDFS2. http://static.zhizuzhefu.com/wordpress_cp/uploads/2013/04/a9.pdf.
[5] Taobao HDFS2. https://github.com/taobao/ADFS.
利益声明:无
免责声明:文中图片均引用自参考。内容表述不妥或者有错误的地方,欢迎指正。
题图:Apache Hadoop
--------------------------------------
如对内容感兴趣,需要订阅请长按二维码:

