




一.项目简介 背景
数据实时同步整体架构是首先maxwell监听各个表的binlog写入rabbitmq,然后是python消费rabbitmq,进行数据的预处理(字典项/生成id)写入到下游base数据库。
上周发现一个公司股东,元素company_inv表有20条,下游有4条,也就是出现了数据同步丢失的bug。
手动更新了一下数据库的入库时间,maxwell监控到了变化,正常写入到了队列。根据以往经验,很大概率是maxwell新增了监控的表进程重启,造成内存buffer丢失。
消费到入库这块程序是有重试加报警机制,上线的时候每个表的数据量和上游也做过对比,出现的问题应该不大。
开发此工具有两个目的:
一是为了给数据实时同步上双保险,即使数据出现了丢失,通过对比也可以找到这部分差异的数据,重新推送到mq队列;
二是解决数据增量发布的问题。之前我们同步是每个表全量导出导入,从预生产导入生产,任务比较耗时。
二.问题分解
2.1 数据一致性的条件
我们想一下,如何判定数据同步到下游是一致的?假如有10个字段
1.针对同一个id,比对10个字段的值是不是全部相等(相当于比较11列)
2.id/md5字段(相当于比较2列)
这2个方法在实时数据同步里实际上行不通,第1个是因为我们数据同步中间加了转换操作,
第二个是md5字段我们上游表也没有,追加md5字段也不现实。
现在有一个折中的方案。
我们数据实时同步,必备的条件是我们上游表的主键id必须对应到下游表的src_auto_id;
上游表的update_time的字段(DEFAULT CURRENT_TIMESTAMP ON
UPDATE CURRENT_TIMESTAMP)
必须同步到下游(下游表该字段不再是DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP)
为什么这样做?举一个例子,当上游表有一条记录
id colA update_time
1 xx 2021-08-11 10:00:59
对应到我们下游应该是这样:
src_auto_id colA update_time z_update_time
1 xx 2021-08-11 10:00:59 2021-08-11 10:01:59
如果id=1 上游的update_time=2021-08-11 10:00:59,下游的update_time=2021-08-11 10:01:00,
这时候数据同步对id=1这条记录是失败的,如果update_time相等则是成功的
这样我们后面比较的时候可以做到通用化,因为上游发生了数据变化,这个时间戳肯定会自动更新。
相当于我们将比对id/md5这样的逻辑转化成了比对id:src_auto_id,update_time:update_time的逻辑
同理针对数据增量发布,表结构是完全一样,这个逻辑转化成了比对id:id,update_time:update_time的逻辑
2.2 如何比对?
关键就是找到差异的数据
1.上游有下游无:需要重新读取上游推送到到队列/写入到下游表
2.上游有下游有:update_time不相等的推送到队列/重新更新到下游表
3.上游无下游有:找到并删除下游表差异的数据。
也就是找insert/delete/update的数据。
程序设计的时候我们可以对主键id进行切分,比如5000一个批次,分别读取上游表的主键和下游表的src_auto_id,update_time字段
0,5000区间内 找到insert/delete/update
...
5000,10000区间内 找到insert/delete/update
...
注意:
当任务类型是检测数据实时同步的,update/insert这里采用更新上游的时间戳字段触发binlog,让maxwell检测到写入队列
因为这一部分数据需要经过transfer转换,transfer逻辑是在消费mq队列程序里做了配置化
三.程序任务表配置 后面有每个列的用途
CREATE TABLE `etl_publish_task_metas` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '任务id',
`from_app` varchar(50) DEFAULT NULL COMMENT '来源业务系统',
`from_db_type` varchar(50) DEFAULT NULL COMMENT '读取的数据源类型',
`from_db` varchar(20) DEFAULT NULL COMMENT '来自数据库',
`from_table` varchar(255) DEFAULT NULL,
`to_app` varchar(50) DEFAULT NULL COMMENT '写入的业务系统',
`to_db_type` varchar(20) DEFAULT NULL COMMENT '写入数据源类型',
`to_db` varchar(20) DEFAULT NULL COMMENT '写入数据库',
`to_table` varchar(255) DEFAULT NULL COMMENT '写入数据表',
`params` text COMMENT '规则',
`task_type` tinyint(2) DEFAULT '2' COMMENT '任务类型1=source2base同步;2=表到表无转换同步',
`task_desc` text COMMENT '任务描述',
`owner` varchar(100) DEFAULT NULL COMMENT '通知人',
`online_status` int(11) DEFAULT '1' COMMENT '在线状态0下线1在线',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='增量发布任务配置/实时同步检测配置表';
params参数:
pk:上游和下游对应的key
- 数据实时同步 dest的key为src_auto_id
check_col_expression:
- 这里支持了表达式(拼接 select 元素updated字段精确到了微妙 下游精确到了秒 因此支持查询表达式用于检测)
worker_num:协程池数量
- 控制在30以内 起多少线程
read_batch:5000条一个批次
- 不要过大(协程池数量*read_batch=同一时刻读取的总量 避免内存溢出)
write_batch:写入下游表的批次
- 500条提交一次 避免一条一条提交
{
"pk": {
"src": "id",
"dest": "id"
},
"worker_num": 20,
"read_batch": 5000,
"write_batch": 500,
"check_col_expression": {
"src": "z_update_time",//上游更新时间戳 如果写了类似substr(z_update_time,1,10)表达式,对应的dest也需要是表达式
"src_update_key":"z_update_time",//上游更新的列
"dest": "z_update_time"//上游update_time字段对应下游的字段 substr(z_update_time,1,10)
}
}
四.配置文件 和上一步任务配置表相关
考虑到程序需要新增不同的任务,这里我们配置了全局的数据库连接配置,和gosqltask一样 db_global.json
里面host/密码统一走环境变量
db_global.json,这里面格式如下:
{
"from": {
"mysql": {
"pre_dw_z_pe":{
"host": "PROD_ZPE_MYSQL_HOST",
"user": "root",
"password": "PROD_ZPE_MYSQL_PASSWORD",
"db": "z_pe",
"port": 3306,
"charset": "utf8"
}
}
},
"to": {
"mysql": {
"test_dw_z_pe":{
"host": "TEST_ZPE_MYSQL_HOST",
"user": "root",
"password": "TEST_ZPE_MYSQL_PASSWORD",
"db": "z_pe",
"port": 3306,
"charset": "utf8"
},
}
}
}
from是一个大map,下面的key代表了数据库类型的各个不同的读取配置
to是一个大map,下面的key代表了数据库类型的各个不同的写入配置
举例:
from.mysql.pre_dw_z_pe,这个意思就是读取pre_dw(预生产)mysql.z_pe数据库
pre_dw_z_pe($from_app_$from_db)分别对应了任务表from_app/from_db
from后面的mysql 对应着任务表from_db_type的字段
同理:
to.mysql.test_dw_z_pe,这个意思就是写入test_dw(测试环境)mysql.z_pe数据库
test_dw_z_pe($to_app_$to_db)分别对应了任务to_app/to_db
这样设计的好处是,添加检测任务或者离线同步任务的时候,程序可以自动从全局配置文件里
去获取各自的任务配置srcConfKey和destConfKey而无需修改代码。
新增任务的时候往数据库插入一条记录即可:
srcConfKey := fmt.Sprintf("from.%s.%s_%s",p.taskInfo.FromDbType,p.taskInfo.FromApp,p.taskInfo.FromDb)
destConfKey := fmt.Sprintf("to.%s.%s_%s",p.taskInfo.ToDbType,p.taskInfo.ToApp,p.taskInfo.ToDb)
五.gopuser代码流程图及代码目录
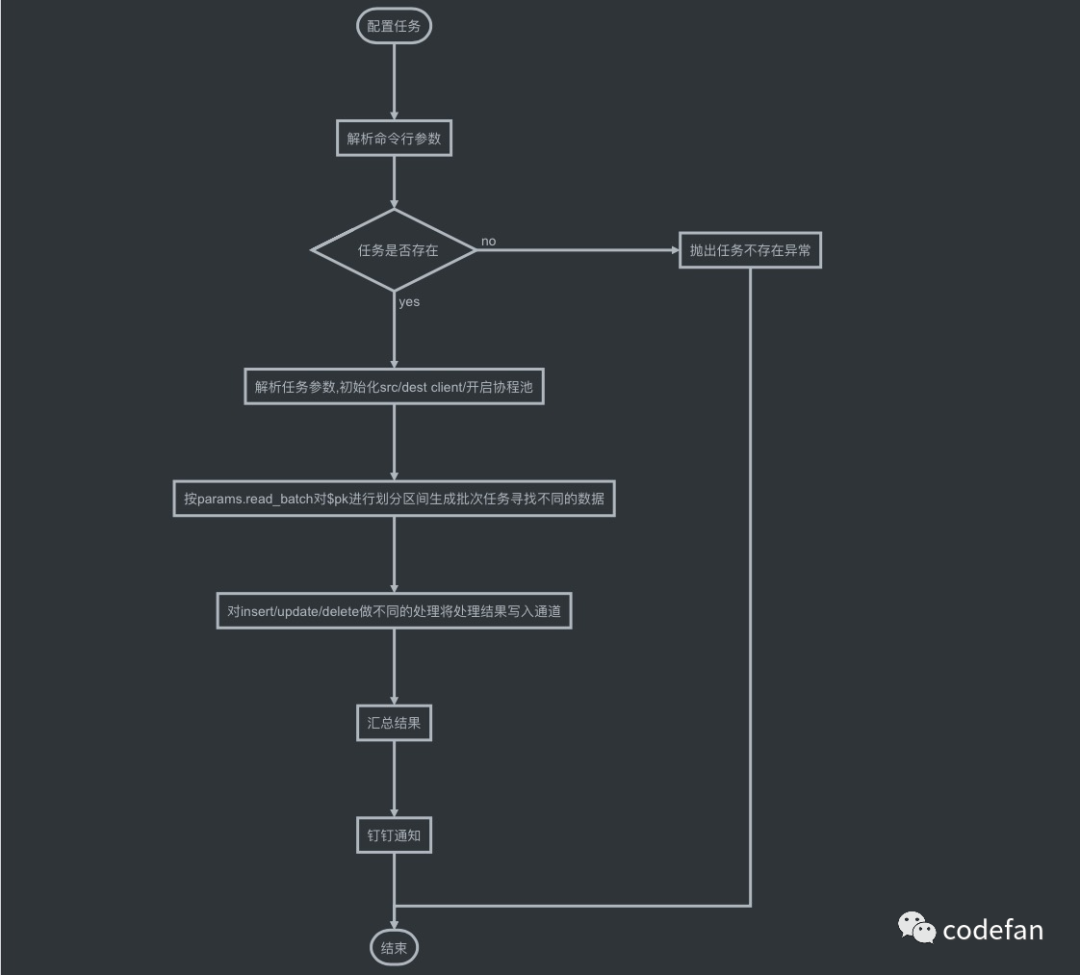
代码目录
.
├── README.md
├── bin
│ ├── build.sh
│ └── build_test.sh
├── cmd
│ └── main.go
├── config
│ ├── db_global.json
│ ├── dev.json
│ ├── prod.json
│ └── test.json
├── docs
│ └── images
│ └── process.png
├── go.mod
├── go.sum
└── pusher
├── constant.go
├── pusher.go
├── types.go
└── workerpool.go
六.运行命令
编译安装
cd 项目/bin
sh build.sh
命令行参数:
Usage of gopusher:
-UsedEnv
是否走环境变量 (default true)
-c string
配置文件目录 (default "./config/")
-e string
运行的环境-json文件前缀 dev/test/prod/local (default "dev")
-id string
任务id (default "1")
task_type=1/2代表了任务运行的不同逻辑,
1是检测rds-source到base的同步 insert/update触发更新操作 让maxwell监控到写入到消息队列
2是数据表增量同步,比如从A库a表拷贝到B库a表
1.数据实时同步的表的检测 task_type=1的
gopusher -c /data/config -e prod -id 1
2.增量发布运行命令 task_type=2
gopusher -c /data/config -e prod -id 2
七.测试结果
7.1 base_entity_basic_info 数据量83286227 9分钟12秒
结果:
[env]:prod
gopusher.task_id:3
[taskDesc]:z_pe.base_entity_basic_info同步检测
[startTime]:2021-08-23 10:40:17
[endTime]:2021-08-23 10:49:29
[costs]:9m12.182037182s
[srcTotal]:83286227
[srcMax]:85660802
[destTotal]:83286227
[destMax]:85660802
[handle]:184
[insert]:184
[update]:0
[delete]:0
7.2 list_company_fin_indicator_cal数据量11295632 20秒
[env]:prod
gopusher.task_id:42
[taskDesc]:z_pe.list_company_fin_indicator_cal同步检测
[startTime]:2021-08-23 13:04:47
[endTime]:2021-08-23 13:05:08
[costs]:20.645940025s
[srcTotal]:11295632
[srcMax]:22516480
[destTotal]:11295632
[destMax]:22516480
[handle]:0
[insert]:0
[update]:0
[delete]:0
7.3 base_elements.company_inv 总量140307254 更新了63223414条 用时1h21m49.784953125s
[env]:prod
gopusher.task_id:93
[taskDesc]:base_elements.company_inv同步检测
[startTime]:2021-08-23 12:58:30
[endTime]:2021-08-23 14:20:20
[costs]:1h21m49.784953125s
[srcTotal]:140307254
[srcMax]:208259038
[destTotal]:140307254
[destMax]:208259038
[handle]:63223414
[insert]:63222864
[update]:459
[delete]:91
更新了1249条数据 从1.4亿里找到差异推送到下游 测试结果:
[env]:prod
gopusher.task_id:93
[taskDesc]:base_elements.company_inv同步检测
[startTime]:2021-08-23 14:23:33
[endTime]:2021-08-23 14:27:52
[costs]:4m19.216474605s
[srcTotal]:140307756
[srcMax]:208260382
[destTotal]:140307756
[destMax]:208260382
[handle]:1249
[insert]:642
[update]:467
[delete]:140
7.4 list_company_trading_record 数据量5238894 8秒
[env]:prod
gopusher.task_id:48
[taskDesc]:z_pe.list_company_trading_record同步检测
[startTime]:2021-08-23 13:20:35
[endTime]:2021-08-23 13:20:43
[costs]:7.991461043s
[srcTotal]:5238894
[srcMax]:5598627
[destTotal]:5238894
[destMax]:5598627
[handle]:0
[insert]:0
[update]:0
[delete]:0
7.5 hk_list_company_fin_indicator_cal 数据量 3384989 10秒
[env]:prod
gopusher.task_id:35
[taskDesc]:z_pe.hk_list_company_fin_indicator_cal同步检测
[startTime]:2021-08-23 13:21:41
[endTime]:2021-08-23 13:21:51
[costs]:9.627576181s
[srcTotal]:3384989
[srcMax]:15697275
[destTotal]:3384989
[destMax]:15697275
[handle]:0
[insert]:0
[update]:0
[delete]:0
7.6 hk_list_company_fin_consensus 数据量1807228 2秒
[env]:prod
gopusher.task_id:32
[taskDesc]:z_pe.hk_list_company_fin_consensus同步检测
[startTime]:2021-08-23 14:37:13
[endTime]:2021-08-23 14:37:15
[costs]:2.369227239s
[srcTotal]:1807228
[srcMax]:3613394
[destTotal]:1807228
[destMax]:3613394
[handle]:1
[insert]:0
[update]:1
[delete]:0
目前全量发布数据节省很多时间,百万级别的表运行很快.
增量发布需要分析,如果每天更新的数据量和全表总量接近一致,直接使用
gosqltask工具读写速度更快,减少了查找对比的过程。
文章转载自codefan,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
