




python自动化部署docker容器消费kafka
一. 使用场景
1.上一篇我们实现了在开发环境下通过指定id来进行消费和生产,这一节我们将项目打包为docker镜像,来实现不同机器的部署,这样当有新的消费需求的时候我们可以通过配置规则到数据库中快速启动
2.目前很实用的就是通过maxwell监听各业务方的mysql数据库的binlog写入kafka,然后消费kafka写入到集群
二.我们复制一个新任务将kafka的配置改写为测试环境kafka集群
192.168.6.67:6667,192.168.6.68:6667
插入一条数据
INSERT INTO `kafka_producer_mock_rules` (`id`, `from_app`, `bootstrap_servers`, `group_id`, `auto_offset_reset`, `enable_auto_commit`, `batch_size`, `topic`, `partition_num`, `value_rule`, `to_app`, `sink_type`, `sink_params`, `developer`, `developer_mobile`, `online_status`, `create_time`, `update_time`)
VALUES
(3, 'localhost', '192.168.6.67:6667,192.168.6.68:6667', 'group01', 'largest', 'true', 100, 'test09', '1', '{\"diskNo\": \"912\", \"taxNo\": \"929\", \"category\": \"bw\", \"success\": true, \"version\": \"1.1.0.4\"}', 'bw_dashboard', 'mysql', '{\"conn\": {\"host\": \"192.168.7.9\", \"user\": \"root\", \"password\": \"2333332\", \"db\": \"bw_dashboard\", \"port\": 3310, \"charset\": \"utf8\"}, \"database\": \"bw_dashboard\", \"table\": \"kakfa_test\", \"fields\": [\"topic\", \"partition\", \"offset\", \"timestamp\", \"value\"]}', '程**', 13888888888, 0, '2019-11-02 21:32:32', '2019-11-02 21:32:32');
三.新增一个几个目录和文件 目录与mock平级
├── Dockerfile #创建镜像用
├── bin/
│ └── build_v0.0.1.sh #build镜像脚本
├── gen_docker_container.py #生成创建docker容器脚本
├── requirements.txt #镜像内python环境
└── templates/#模板目录
└── base_docker_container.tmpl
四.mock.py修改
上一篇我们是使用mock函数里的consumer函数 通过传id将config配置动态获取 返回Scheduler的实例起动消费的worker进程,如果用docker部署的话 我们上一节提到将数据库的数据dumps为配置文件最佳,所以我们将consumer函数修改为dumpsconfig函数,然后gendocker_container脚本里引用这个函数
mock.py
#gen_docker_container.py里引用 返回配置文件的列表
def dumps_configs(id):
meta_cls = KafkaProducerMeta(id)
meta = meta_cls.get_meta()
item = copy.deepcopy(meta)
partition_num = int(meta['partition_num'])
configs = []
for i in range(1,partition_num+1):
item['partition_num'] = str(i)
CONFIG['meta'] = item
source = {
'consumer': {
"bootstrap_servers": meta["bootstrap_servers"],
"group_id": meta["group_id"],
"enable_auto_commit": True if meta["enable_auto_commit"] == 'true' else False ,
"auto_offset_reset": meta["auto_offset_reset"]
},
"topic": meta["topic"],
"prefix_name": '-'.join([meta["group_id"],str(partition_num)])+'_'
}
CONFIG['source'] = source
CONFIG['sink'] = loads_data(meta['sink_params'])
CONFIG['Scheduler']['name'] = meta["topic"]+str(i)
config = copy.deepcopy(CONFIG)
configs.append(config)
return configs
五.下面是实现docker容器自动化的关键一步,首先梳理run一个容器的部署
1.打包为一个镜像 docker build ----参数 命名镜像名:版本号
2.ru容器:docker run -d 参数(-v/日志目录/启动脚本等) --name 容器名 镜像名称:版本号
3.第一步我们可以先不考虑,第二步的命令行参数除了(命名镜像名:版本号)依赖第一步,其他都可以从数据库的信息里去得到,因此我们gendockercontainer.py脚本考虑的流程就是将获取到config,首先生成配置文件然后再生成shell脚本即可
docker_containers 目录
.
└── 3_test09_group01 #子文件夹 也是容器名称
├── bin #shell脚本
│ └── 3_test09_group01_1.sh #run shell脚本
├── config #配置文件目录 根据分区不同 同一group_id会有多个配置文件
│ └── 3_test09_group01_1.json #生成的配置文件
├── log #docker run时候挂载出来的日志目录
│ └── 3_test09_group01_1.log
└── scripts #如果topic有多个分区时候 我们可以起多个worker 该目录下就会出现多个py脚本
└── 3_test09_group01_1.py # 映射到容器内
gen_docker_container.py 脚本命令行
_USAGE = """\
Usage:
python3 gen_docker_container.py --id 3
python3 gen_docker_container.py --id 3 --path 你的container目录
python3 gen_docker_container.py --id 3 --path 你的container目录 --system 部署服务器类型
python3 gen_docker_container.py --id 3 --path 你的container目录 --system 部署服务器类型 --version 镜像版本号
"""
六.效果如下:
run-docker
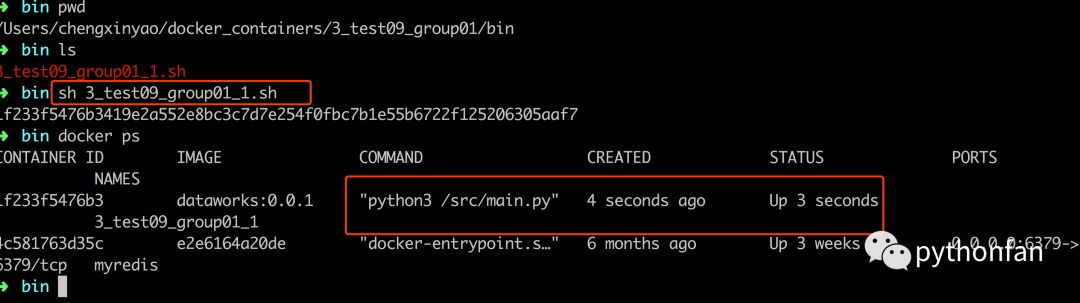
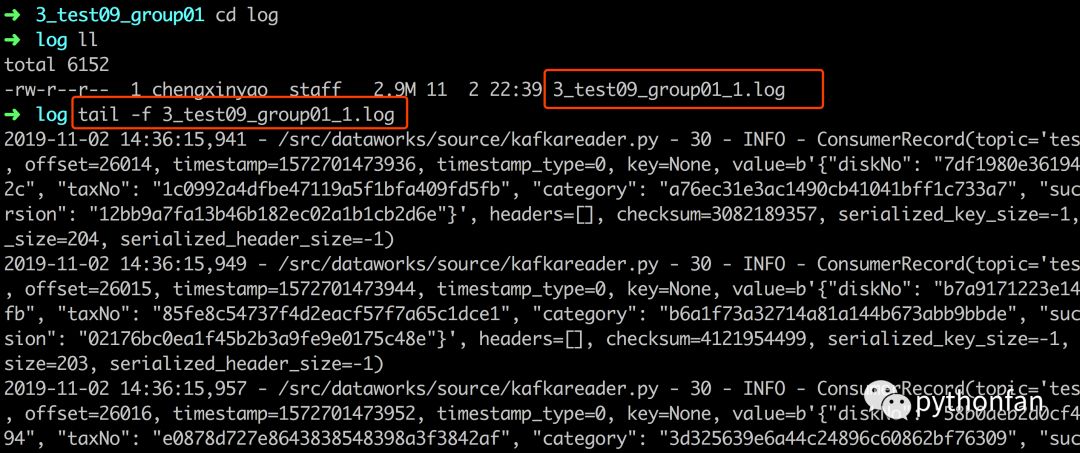
启动消费进程 挂载到宿主机log目录
学习付费-拓展开发思维,提高效率和工作绩效,争取每天0点28分都发点东西,记录学习一些东西
