




环境说明以及升级介绍
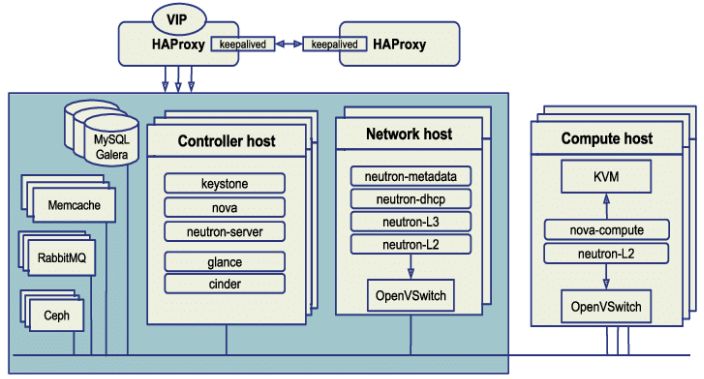
当前环境为Ocata 三控制HA环境,Neutron对接Huawei SDN,后端存储使用mimic版本的Ceph。Ceph不进行升级,仅升级OpenStack,同时SDN也会跟进升级。
本次预计从Ocata直接升级到Rocky版本。实现滚动升级。

环境计算资源使用较少,升级之前会将所有的虚拟机进行整合,热迁移到固定的计算节点上。预留2-3台空余计算节点进行优先升级。本次环境为三个控制节点,单个控制节点可以停止服务,只要确认虚拟机不中断,业务不中断即可。
这里有几个重要步骤,我们推荐在计划任何OpenStack升级时采取:
通篇详读OpenStack版本注释,以识别出潜在的版本间的不兼容性。尤其在对原生代码更改的情况下,比如对接商业SDN后,引起数据库升级失败问题。
选择合适的方法升级OpenStack以及确认升级的目的。OpenStack Ocata版本之后支持滚动升级,可以不停服务。
准备一个升级失败的回滚计划。随时准备回滚。得益于OpenStack服务都为无状态,回滚主要是还原包版本以及导回旧的数据。
准备一个数据备份计划,至少,带有配置文件和数据库的备份。以及提前准备好新版本配置文件。配置文件不会因为软件的升级而升级,需要手工更新。
依照特定服务的SLAs,定一个可接受的云停机时间,如果可能存在数据丢失,提醒你的用户,服务的中断时间。升级期间尽量不要操作云平台。
在有条件的情况下,提前使用与生产环境相同的测试环境,测试升级方法。升级过程中请在控制与网络服务正常后再升级计算节点。否则容易出现断网现象。
OpenStack升级方式有如下几种:
平行云:部署一个独立的OpenStack云并从升级前的云迁移所有资源到升级后的云上。这是最简单粗暴的方式。同时,它也有一个最简单的回滚程序。然而,它需要大量的硬件资源并导致很长的停机时间。
滚动升级:以下2种方法会依次升级每个服务器上的每个组件,最终获得一个已升级的OpenStack云。
就地升级:这个方法需要在升级时关闭相应服务,引起一定的停机时间,然而少于平行云的方法。
并列式升级:从OpenStack Icehouse起,控制器已从计算节点上分离,所以你可以独立升级它们。通过这个方法,你可以部署一个已升级的控制器,并从旧控制器上转移所有的数据到新控制器上,再用新控制器无缝替代旧控制器。旧控制器原封不动,所以回滚也很容易完成。为了实现零停机时间,在HA模式中,你需要超过一个控制器。
本次升级目标
平滑升级,业务无影响,升级后功能组件正常。
最短服务暂停时间。但云主机,云盘以及网络等云资源正常工作。
升级失败可立刻回退。回退后可继续提供云服务。
升级规划
云主机热迁移,腾出部份空余计算节点用于优先升级以及测试。
备份所有节点的配置文件以及所有的数据库,用于回滚(数据库在虚拟机迁移后进行备份)。
准备所有新版本的配置文件(版本升级后有些配置项不再使用,新的配置项需要添加)。
停止三台控制节点所有的OpenStack服务,如果控制网络安装在一起,请保留网络节点的服务,尤其是dhcp-agent,确保虚拟机可以获取IP地址。
按照keystone—glance—cinder—nova—neutron的升级顺序进行升级。升级包含软件包以及数据库。升级先升级一个控制节点。
当一个控制节点升级完毕,开始升级单个网络节点以及计算节点,确认服务正常,功能正常。最后进行全部升级(谨慎升级openvswitch,否则造成业务虚拟机断网)
升级过程中如出现无法继续下去的故障,请使用备份数据库进行回滚,使用另外的控制节点以及网络节点提供正常的服务。
升级过程中确认rabbitmq cluster,mariadb cluster,haproxy,memcached等服务正常。
先决条件
几乎所有的OpenStack服务都支持数据库迁移。这意味着每个服务将会在(升级)开始时尝试升级其数据库。通常,自动化升级会由OpenStack稳定版本完整测试过,并可以安全的使用(如果需要人工升级,可以禁用自动升级)。与此同时,从Kilo版本开始,数据库降级已经不被支持。也就是说,唯一可靠的数据库回滚的方法是从备份中恢复数据库。在开始升级过程之前执行一些环境清理以确保一致的状态。例如,删除后未从系统中完全清除的实例可能会导致不确定的行为。确认当前的版本信息无误。版本信息确认方式如下:
对于使用OpenStack Networking服务(neutron)的环境,请验证数据库的发行版本。例如:
# su -s bin/sh -c "neutron-db-manage --config-file etc/neutron/neutron.conf \
--config-file etc/neutron/plugins/ml2/ml2_conf.ini current" neutron复制
对于使用OpenStack Compute计算服务(nova)的环境,请验证数据库的发行版本。例如:
# su -s bin/sh -c "nova-manage db version" nova
复制对于使用OpenStack Identity认证服务(keystone)的环境,请验证数据库的发行版本。例如:
# su -s bin/sh -c "keystone-manage db_version" keystone
复制对于使用OpenStack Image镜像服务(glance)的环境,请验证数据库的发行版本。例如:
# su -s bin/sh -c "glance-manage db version"
复制对于使用OpenStack Volume快存储服务(cinder)的环境,请验证数据库的发行版本。例如:
# su -s bin/sh -c "nova-manage db version" nova
复制对于使用OpenStack Volume快存储服务(cinder)的环境,请验证数据库的发行版本。例如:
# su -s bin/sh -c "cinder-manage db version" cinder
复制
配置文件以及数据库备份
配置文件备份
# for i in keystone glance nova neutron openstack-dashboard cinder; \
do mkdir $i-RELEASE_NAME; \
done
# for i in keystone glance nova neutron openstack-dashboard cinder; \
do cp -r etc/$i/* $i-RELEASE_NAME/; \
done复制数据库备份
# mysqldump -u root -p --opt --add-drop-database --all-databases > RELEASE_NAME-db-backup.sql
# for db in keystone glance nova neutron cinder placement nova_api nova_cell0; \
do mysqldump -uroot -p $db >$db.sql
done复制
配置新版本Yum源服务
Rocky版本YUM源配置
#aliyun base
[alibase]
name=CentOS-$releasever - Base - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
gpgcheck=0
enabled=0
#released updates
[aliupdates]
name=CentOS-$releasever - Updates -mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
enabled=0
gpgcheck=0
[aliextras]
name=CentOS-$releasever - Extras - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
enabled=0
gpgcheck=0
[aliepel]
name=Extra Packages for Enterprise Linux $releasever - $basearch - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/epel/$releasever/$basearch
failovermethod=priority
gpgcheck=0
enabled=0
[ali-qemu-ev]
name=CentOS-$releasever - QEMU EV
baseurl=http://mirrors.aliyun.com/centos/$releasever/virt/$basearch/kvm-common/
gpgcheck=0
enabled=0
[ali-rocky]
name=CentOS-$releasever - Rocky
baseurl=http://mirrors.aliyun.com/centos/$releasever/cloud/$basearch/openstack-rocky
failovermethod=priority
gpgcheck=0
enabled=0
[ali-ceph]
name=CentOS-$releasever - Ceph
baseurl=http://mirrors.aliyun.com/centos/$releasever/storage/$basearch/ceph-luminous
failovermethod=priority
gpgcheck=0
enabled=0复制
服务升级
要更新每个节点上的服务,通常需要修改一个或多个配置文件,停止服务,同步数据库模式以及启动服务。某些服务需要不同的步骤。我们建议在继续下一个服务之前验证每个服务的操作。
升级服务的顺序以及常规升级过程中的任何更改如下所述:
控制节点
Identity service - 在同步数据库之前清除所有过期的令牌。
Image service - 编辑配置文件并重新启动服务。
Compute service, including networking components.
Networking service - 请注意更新网络服务注意点,确认neutron状态正常再更新计算节点网络服务组件
Block Storage service - 更新块存储服务只需要重新启动服务。
Dashboard - 在典型环境中,更新horizon只需要重新启动Apache HTTP服务。
Orchestration service
Telemetry service - 在典型环境中,更新计量服务只需要重新启动服务。
Compute service - 编辑配置文件并重新启动服务。
Networking service - 编辑配置文件并重新启动服务。
网络节点
升级网络节点之前请确认neutron-server服务正常。编辑配置文件并重新启动服务。
计算节点
Networking service - 编辑配置文件并重新启动服务,请注意更新openvswitch以及agent可能会造成网络中断。
Nova service - 编辑配置文件并重新启动服务。
配置文件更新注意
一个新OpenStack版本带来了新的系统依赖项,并要求升级当前系统依赖项的版本。如果一些系统依赖项没有被安装或是升级,已升级的OpenStack服务将因运行时间错误而不能开启或将被终止。
当升级OpenStack服务的时候,确保所有的依赖项已经被正确地升级了。通常这意味着所有的OpenStack组件是用正确定义和测试了依赖项的安装包(dep或rpm)所安装的。即使如此,由于特定的配置,升级安装包仍可能破坏部分服务。如果安装包管理器(yum或apt-get)要求你升级配置文件,推荐你选择拒绝。改为人工审查、更改配置文件和重启服务。
每个OpenStack版本都会引起配置文件的改变。一些选项可能会被移除,重命名或是被移动到其他地方。新的选项会被添加默认值,这都可能会破坏你的云。通篇详读版本注释,以识别这些变更,并合理应用到你的配置文件中。举例:
在所有的配置文件keystone_authtoken部分添加如下内容(否则启动失败):
user_domain_name=Default
project_domain_name=Default复制更新dashboard后,升级到Django 1.9或1.10后,使用django.utils.log.NullHandler的LOGGING配置会抛出一个异常,指出NullHandler不可解析:
Unable to configure handler 'null': Cannot resolve 'django.utils.log.NullHandler': No module named NullHandler
复制如果将通常建议的日志配置复制/粘贴到基于Django 1.9或1.10的新项目中,也会发生这种情况。因此需要修改配置文件/etc/openstack-dashboard/local_settings handlers部分如下:
'handlers': {
'null': {
'level': 'DEBUG',
#'class': 'django.utils.log.NullHandler',
'class': 'logging.NullHandler',
},复制
数据库升级
keystone
# su -s bin/sh -c "keystone-manage token_flush" keystone
# su -s bin/sh -c "keystone-manage db_sync" keystone复制glance
# su -s bin/sh -c "glance-manage db upgrade" glance
复制cinder
为了使数据库模式迁移不那么难以执行,自Liberty以来,所有数据迁移都被禁止使用模式迁移脚本。相反,迁移应该通过后台进程以不中断正在运行的服务的方式完成(如果您正在进行冷升级,也可以在关闭服务的情况下执行在线数据迁移)。在Ocata 中,为此目的添加了一个新的实用程序。在将Ocata升级到Pike之前,您需要在后台运行此工具,直到它告诉您不再需要迁移。请注意,在完成Ocata的在线数据迁移之前,您将无法应用Pike的架构迁移。
从Ocata开始,您还需要运行 命令以确保应用数据迁移。该工具允许您通过使用来限制数据迁移的影响
cinder-manage dbonline_data_migrations``--max_count
用于限制一次运行中执行的迁移次数的选项。如果使用此选项,则如果任何迁移成功,则退出状态将为1(即使其他迁移生成错误,这可能是由于迁移之间的依赖性)。退出状态为1时,应重新运行该命令。如果无法进一步迁移,如果某些迁移仍然生成错误,退出状态将为2,这需要干预才能解决。只有当退出状态为0时才应该认为该命令已成功完成。您需要在开始升级到下一个版本之前完成所有迁移(例如,在继续升级到Pike之前需要完成Ocata的数据迁移;您不会能够在完成Ocata的数据迁移之前执行Pike的数据库模式迁移。# su -s bin/sh -c "cinder-manage db sync" cinder
# su -s bin/sh -c "cinder-manage db online_data_migrations" cinder复制neutron
Neutron-server是第一个应该升级到新代码的组件。它也是唯一依赖新数据库模式的组件,其他组件通过AMQP与云进行通信,因此不依赖于特定的数据库状态。
使用alembic迁移链实现数据库升级。
数据库升级分为两部分:
# su -s bin/sh -c "neutron-db-manage upgrade --expand" neutron
# su -s bin/sh -c "neutron-db-manage upgrade --contract" neutron
# su -s bin/sh -c "neutron-db-manage --config-file etc/neutron/neutron.conf \
--config-file etc/neutron/plugins/ml2/ml2_conf.ini upgrade heads" neutron复制注意:
neutron-server实例的完全关闭可跳过,此依赖于是否存在挂起的未应用到数据库的contract脚本:
# su -s bin/sh -c "neutron-db-manage has_offline_migrations" neutron
复制此命令将返回是否存在挂起的contract脚本信息。
nova
请注意,您可以使用该参数来减少此操作将对数据库施加的负载,从而允许您运行一小部分迁移,直到完成所有工作。您应该使用的块大小取决于您的基础结构以及您可以对数据库施加的额外负载。要减少负载,请执行较小的批处理,并在块之间进行延迟。要缩短完成时间,请运行更大的批次。每次运行时,该命令都会显示已完成和剩余记录的摘要。
如果使用
nova-manage dbonline_data_migrations --max-count <number>``--max-count``--max-count
选项,该命令应该在返回退出状态1时重新运行(这表示某些迁移生效,并且可能还有更多工作要做),即使某些迁移产生错误也是如此。如果所有可能的迁移都已完成且某些迁移仍然产生错误,则将返回退出状态2。在这种情况下,应调查和解决错误的原因。仅当命令返回退出状态0时,才应认为迁移已成功完成。# su -s bin/sh -c "nova-manage api_db sync" nova
# su -s bin/sh -c "nova-manage db sync" nova
# su -s bin/sh -c "nova-manage db online_data_migrations" nova复制
数据库升级注意
OpenStack本身可以实现滚动不停机升级,升级之前请确认后当前数据库的版本以及数据量。做好充分的备份,随时做好回滚。
当使用滚动更新的时候,数据迁移请使用以下命令:
# su -s bin/sh -c "nova-manage db online_data_migrations" nova
# su -s bin/sh -c "neutron-db-manage has_offline_migrations" neutron
# su -s bin/sh -c "cinder-manage db online_data_migrations" cinder复制
online_data_migrations需要对应服务的RPC响应。如果因任何原因等待该响应超时,则迁移失败。
数据库升级完成后需要再次检测当前数据库版本,确认版本无误。
功能检测
通过监控或者api 命令行的方式确认OpenStack处于正常的工作状态。
keystone 检测
# openstack user list
# openstack endpoint list
# openstack project list
# openstack service list复制glance 检测
# openstack image list
# openstack image save --file cirros.img cirros复制neutron 检测
# openstack network list
# openstack network create parent-net
# openstack subnet create parent-subnet --network parent-net --subnet-range 20.0.0.0/24复制cinder 检测
# openstack volume list
# openstack volume create vo1 --size 1
# openstack server add volume 84c6e57d-a6b1-44b6-81eb-fcb36afd31b5 \
573e024d-5235-49ce-8332-be1576d323f8 --device /dev/vdb复制nova检测
# openstack server list
# openstack server create --flavor 1 --image 397e713c-b95b-4186-ad46-6126863ea0a9 \
--security-group default --key-name KeyPair01 --user-data cloudinit.file \
myCirrosServer复制生成功能检测表
以下为云平台监控检测表,如果监控完善,可以根据监控信息进行检测。
节点名称 控制一controller1 控制二controller2 控制三controller3 整体 可用性 可用性 可用性 可用性 可用性 keystone.api.status 100% 100% 100% 100% keystone.service.api.status 100% 100% 100% 100% glance.api.status 100% 100% 100% 100% cinder.api.status 100% 100% 100% 100% neutron.api.status 100% 100% 100% 100% nova.api.status 100% 100% 100% 100%
日志查看
日志能够帮助我们深入学习 OpenStack 和排查问题。但要想高效的使用日志还得有个前提:必须先掌握 OpenStack 的运行机制,然后针对性的查看日志。就拿 Instance Launch 操作来说,如果之前不了解 nova-* 各子服务在操作中的协作关系,如果没有理解流程图,面对如此多和分散的日志文件,我们也很难下手。对于 OpenStack 的运维和管理员来说,在大部分情况下,我们都不需要看源代码。因为 OpenStack 的日志记录得很详细了,足以帮助我们分析和定位问题。但还是有一些细节日志没有记录,必要时可以通过查看源代码理解得更清楚。即便如此,日志也会为我们提供源代码查看的线索,不需要我们大海捞针。这一点我们会在后面的操作分析中看到。
因此,最后我们需要确认所有服务的日志无报错。如果需要,可以临时打开Debug。服务正常后请关闭Debug,否则影响性能。
Nova日志OpenStack计算服务日志位于/var/log/nova,默认权限拥有者是nova用户。需要注意的是,并不是每台服务器上都包含所有的日志文件,例如nova-compute.log仅在计算节点生成。nova-compute.log:虚拟机实例在启动和运行中产生的日志
nova-manage.log:运行nova-manage命令时产生的日志
nova-scheduler.log:有关调度的,分配任务给节点以及消息队列的相关日志
nova-api.log:用户与OpenStack交互以及OpenStack组件间交互的消息相关日志
nova-console.log:关于nova-console的VNC服务的详细信息
nova-consoleauth.log:关于nova-console服务的验证细节
nova-placement-api.log:关于nova-placement-api交互的日志
Neutron日志网络服务Neutron的日志默认存放在/var/log/neutron目录中
dhcp-agent.log:关于dhcp-agent的日志
l3-agent.log:与l3代理及其功能相关的日志
metadata-agent.log:通过neutron代理给Nova元数据服务的相关日志
openvswitch-agent.log:与openvswitch相关操作的日志项,在具体实现OpenStack网络时,如果使用了不同的插件,就会有相应的日志文件名
server.log:与Neutron API服务相关的日志
Keystone 日志
身份认证Keystone服务的日志记录在/var/log/keystone/keystone.log中。
Cinder日志
块存储Cinder产生的日志默认存放在/var/log/cinder目录中
cinder-api.log:关于cinder-api服务的细节
cinder-scheduler.log:关于cinder调度服务的操作的细节
cinder-volume.log:与cinder卷服务相关的日志项
Glance日志
镜像服务Glance的日志默认存放在/var/log/glance目录中
api.log:Glance API相关的日志
registry.log:Glance registry服务相关的日志 根据日志配置的不同,会保存诸如元信息更新和访问记录这些信息。
写在最后
OpenStack发展到如今的Stein版本,升级已经不再像以前那么困难,只要合理规划,完全可以实现安全,无缝不停机快速升级。有些操作还需亲自测试后才有发言权,不要人云亦云。
在生产环境进行升级之前一定要提前进行测试,尤其是在跨比较多的版本的情况下。因为配置项的缺失或者错误导致服务不正常。升级后一定要进行充分的测试,以及日志错误的排除。
如果需要进行操作系统的升级,控制节点可以一台台升级,计算节点可以先迁移虚拟机,然后再进行升级重启。
本次升级的环境跨度比较大,同时neutron集成了Huawei的SDN方案,后端存储使用Ceph。所以最大的故障点在于SDN,所以本次优先升级SDN,当确认网络没有问题后再进行OpenStack 滚动升级。


了解新钛云服
新钛云服正式获批工信部ISP/IDC(含互联网资源协作)牌照
新钛云服,打造最专业的Cloud MSP+,做企业业务和云之间的桥梁
新钛云服出品的部分精品技术干货
刚刚,OpenStack 第 19 个版本来了,附28项特性详细解读!
