




Linux内核存储通用框架
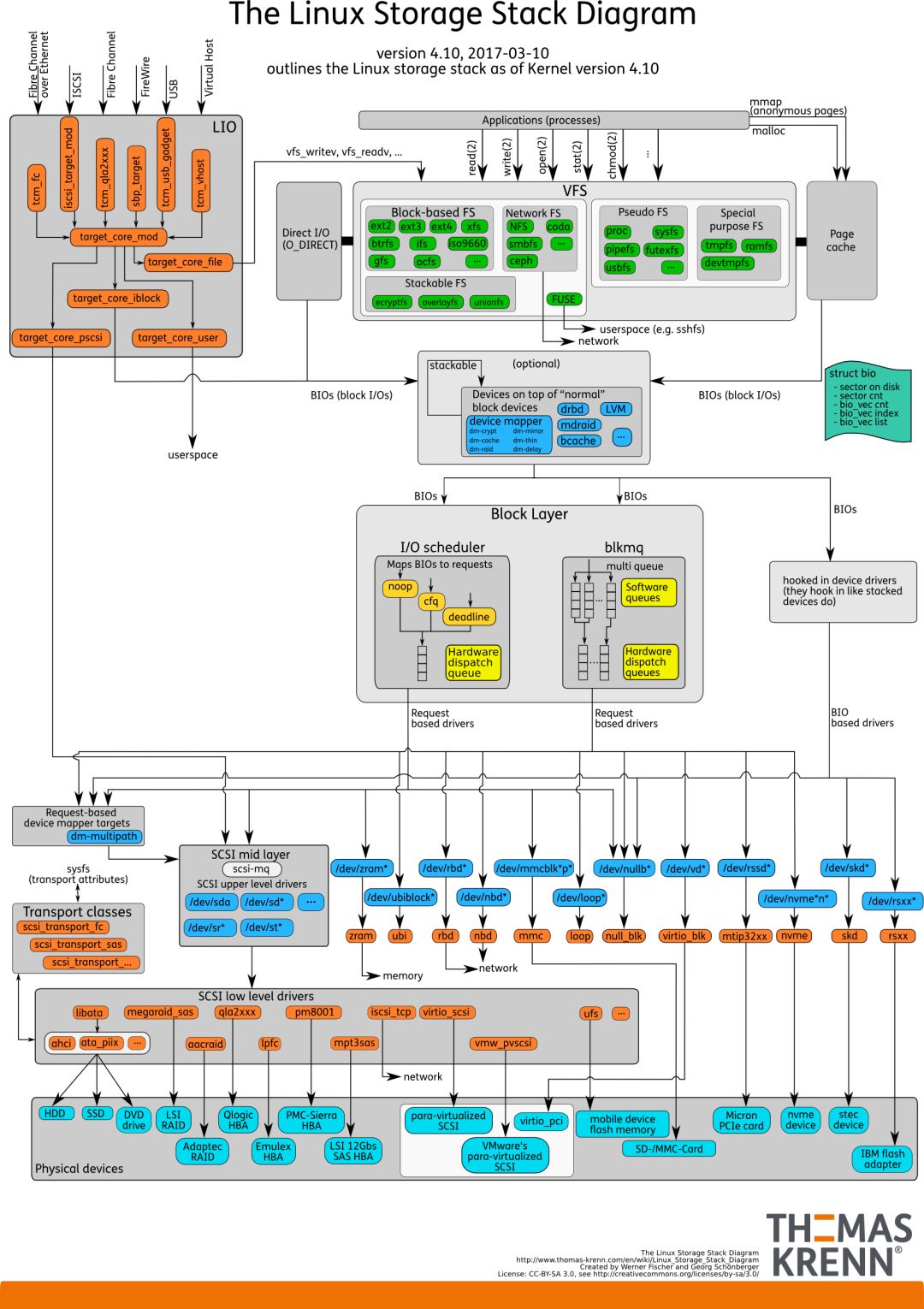
Linux系统下一个普通的读写请求的流程要经过syscall、文件系统(VFS以及具体的ext2、ext4等等)、Page Cache(optional)、Block I/O、设备驱动程序。
图1 经典的存储设备架构[1]
读操作实例
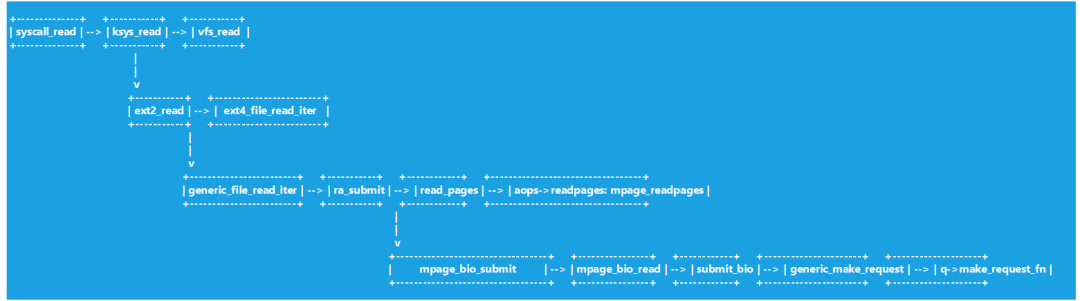
VFS(Virtual Filesystem Switch)提供了文件系统的抽象接口,文件系统通过VFS的slot注册了自己的file_operations和address_space_operations,file_operations负责对接VFS,addess_space_operations则是文件系统和Block I/O层的接口,Block I/O层又可以看做bio和request两部分,bio负责承接fs的请求,将fs的读写请求封装到bio的数据结构里,request层则将bio请求转换为设备驱动能接收的request,调用底层驱动的策略函数将request丢到每个驱动的请求队列(bio->gendisk->request_queue->make_request_fn)。
图2 read调用流程
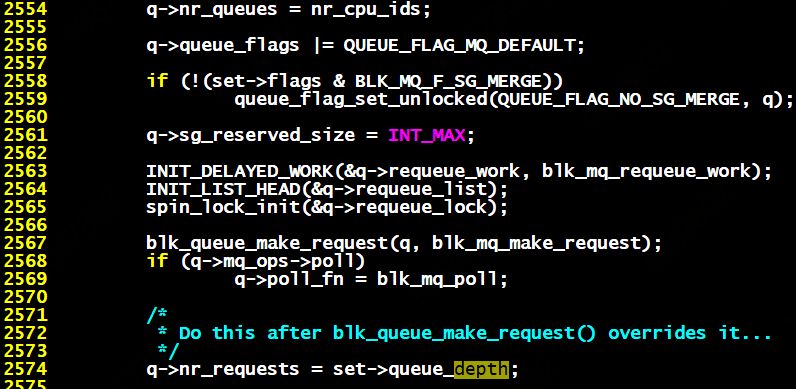
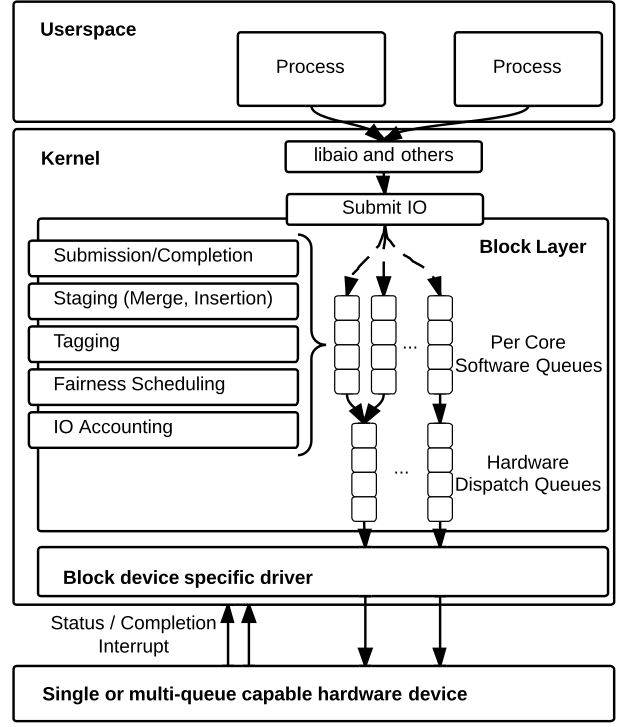
q->make_request_fn()这个驱动提供的策略方法一般是在每个驱动初始化请求队列时注册,驱动负责生成一个队列以及策略接口,但是从3.13开始,为了提升SSD的性能,一个针对硬件特性的全新的Block I/O的实现诞生了,驱动注册的request_fn几乎在现在的内核版本中被废弃(仅存在与loop、bache等驱动中)。新的策略采用了硬件特性化的队列——将提交的request_queue的个数(nr_queues)和CPU核数绑定,每个request_queue对应的最大队列深度(queue_depth)和设备特性相关,驱动提供的request_fn则由block层提供:
图3 mfn在blk-mq.c下的实现
这样q->make_request_fn()最终会调用到(类似run_hw_queue)驱动测的blk_mq_ops->queue_rq():
图4 nvme设备的blk_mq_ops
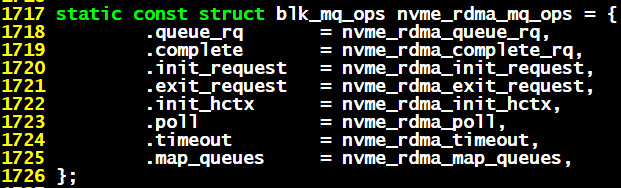
以NVME设备为例,我们可绑定的core一般是48~128,每个queue的深度是31个,重要的是每个queue之前的锁是互不影响的,这样将带来极大的并行性(有关相邻块的合并问题请参看参考文献[2])。
下边我们看下blk-mq的作者给我们的官方图解:
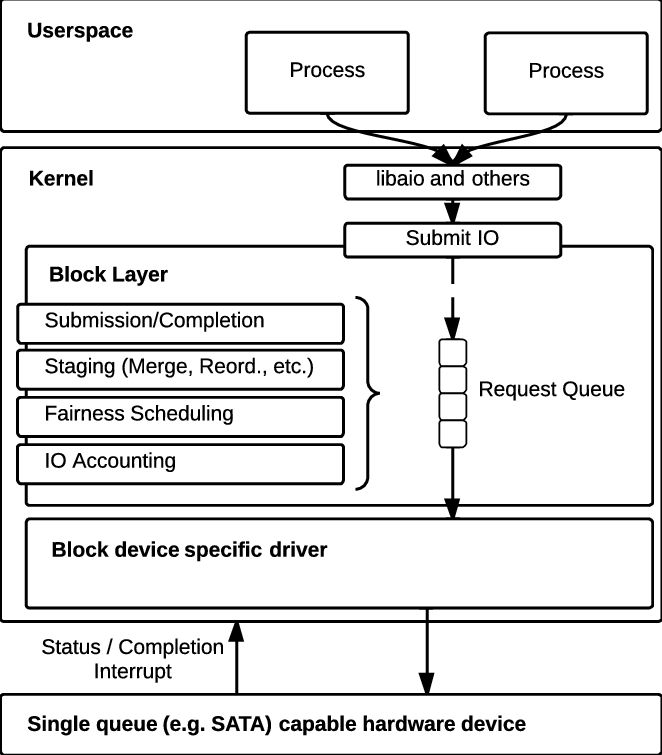
图5 3.13内核以前、后的IO存储栈对比
Block驱动请求层
现在我们再来看下图2中未被列出来的Block驱动层做的事情,第一列是block驱动层做的通用分发策略,其中“ops.mq.dispatch_request”是调用IO调度策略(CFQ,deadline或者noop,我将在后续章节中去分析调度算法、电梯算法以及plug机制),右侧则是nvme rdma的驱动,中间省略了一些驱动细节处理:dma map satter/gather/sync,dma描述符填充host controller,中断以及poll策略等等,而是直接跳到block层注册给驱动层的bio_end_xxx处,当block层检测到本次请求完成后,还会触发一次软中断去发起下一次请求(记忆中 )。
)。
图6 Block驱动层和设备间的交互

正如我前面所介绍的blk-mq的引入将request_queue实现成了per-CPU,这样做的目的是避免了cache miss的问题,之前的实现(图5)用一个queue去管理所有请求,链表要不断的进行插入、删除等操作,在驱动层面还有重构这些queue的请求,这就会导致CPU缓存不命中造成的性能问题。
总结
本文从模块角度对内核存储流程做了分析,因为有回写设备等内容,为了避免对blk-mq分析时带入的不必要的复杂性,作者刻意只分析了read操作,同时也没有分析lock、block归并、关联等细节,希望给读者一个清晰的、能尽快找到调试入口点的普及型文章。对其中的细节将在后续系列中不断完善。
最后,推荐大家一款命令行下text画图工具——graph-easy,还在学习中。
[1] https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
[2] https://lwn.net/Articles/552904/
[3] https://www.thomas-krenn.com/en/wiki/Linux_Multi-Queue_Block_IO_Queueing_Mechanism_(blk-mq)
