
数据仓库Hive支持那么多数据格式,我可怎么选啊?
hive存储支持的数据文件格式有三种:
TextFile
SquenceFile
OrcFile
你们怎么选我不知道,我选ORC!!!
列式存储格式
行式存储格式
由于使用场景的原因,我们传统的数据库采用的是行式存储的方式,如图所示,所有的数据列依次排成一行。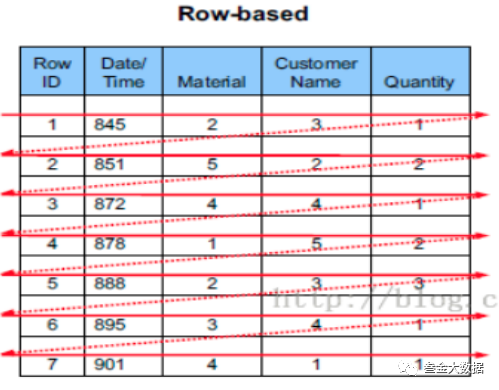

配合B+Tree索引,通过主键可以快速的查询,获取对应的数据。比如我们想查询id=3的数据, 我们可以通过索引与存储空间的映射快速的查询到id=3的数据。因为常用关系数据库的操作都是以实体为单位,所以每次取一行的数据是完全契合我们的使用场景的。
列式存储格式
对于大数据分析的场景来看,一般一个典型的查询是需要遍历完整的表 或者多个partition,并且需要对数据进行分组排序聚合等一系列操作,在这样的场景下 按行存储的优势就不存在了。而且需要注意的是我们对数据进行分析时可能不会用到所有的列,只需要必要的几列就可以了。如果存储格式为行式存储的话无关的数据列也要参与扫描和读取。所以,在大数据场景下我们常用的数据存储格式为列式存储。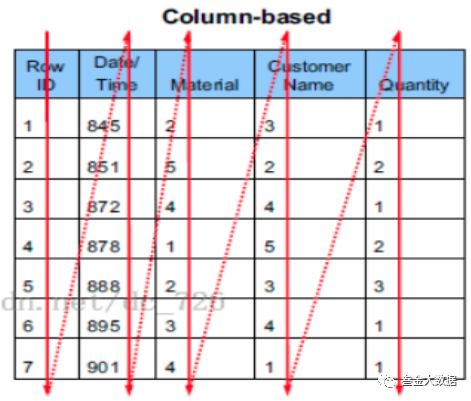

这样有什么好处呢?假如我们要查询id这一列,那我们只需要查询该数据文件的前一部分就可以了。列式存储的好处是当我们的查询语句只涉及到部分列的时候,我们只需要扫描对应的部分文件就可以了。同时每列的数据数据格式相同,彼此间的相关性更大,压缩的效率更高。我们在存储的时候也可以对不同的数据格式进行不同的压缩方式来最大化的节约存储空间。但是列式存储也有缺点,比如我们对某一条数据要插入或者更新时,需要对多个列同时进行操作,代价比行式存储要高的多,但是我们数据仓库的主要需求是查询和分析,所以使用列式存储格式是没有问题的。 列式文件代表:ORC
ORC就是我们常用的列式存储格式文件,了解ORC的内部设计,可以帮助我们理解列式存储格式的实现方案,同时对于大数据使用列式格式存储为什么可以提高查询效率进行更深入的理解。
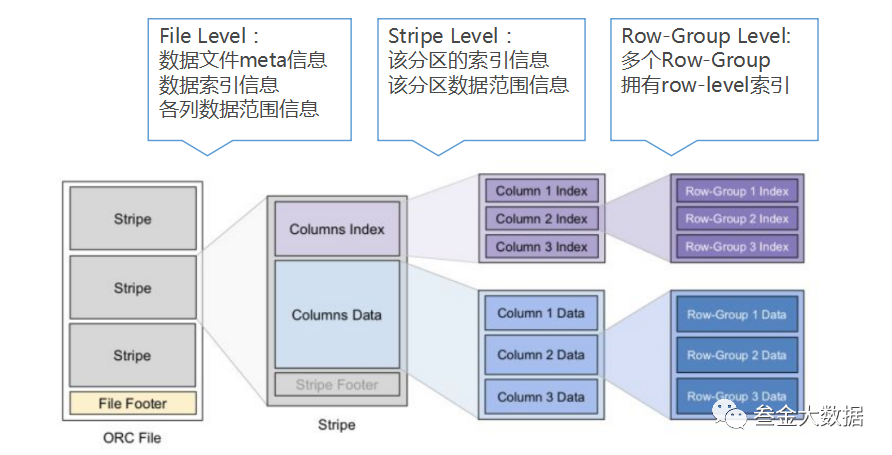
我们结合OrcFile的结构图来认识一下OrcFileOrcFile支持int、string等简单类型,也支持array、map等复杂类型。 OrcFile是自描述的,它的meta信息放到了文件的尾部,也就是我们最左侧下面的File Footer。一个OrcFile包含多个Stripe,Stripe就是一个分片。OrcFile支持分区读的,那么为每个分区构建索引是有必要的。 第一个层级是File Level的索引,即File Footer。在File Footer中保存了数据的meta信息、数据的索引信息等。比如有哪些数据列,各个列的最大值最小值,是否有null值, 以及布隆过滤器等。这些数据可以用来快速的确定该文件是否包含我们要查询的数据,以及该Orc文件包含哪些Stripe。如果我们通过这些信息确定我们要查询的数据在某一个Stripe中,那么接下来就会从该Stripe进行查询了。从图中我们也可以看到在Stripe里面有一个Stripe Footer。在Stripe Footer中就保存了第二级索引 Stripe Level。Stripe对应着原始数据文件的一个分区,里面包含该分区内各列的值, 在Stripe Footer存储的数据和File Footer存储的数据类似,包含该Stripe数据的索引信息,数据范围信息等等。第三级索引就是Row Group Level ,Row Group Level索引是最小的索引单位了,默认的RowGroup由1w条数据组成。当我们由这些索引信息确认到某一个RowGroup后,我们只需要扫描这1w条数据就可以了。我们对数据进行查询时,根据我们的数据条件首先从File Footer获取该文件要查询的列的最大值最小值等信息,根据谓词下推,判断该文件是否包含我们要查找的数据。如果不包含则pass,如果包含 则获取数据在哪些Stripe中,获取Stripe的位置和长度,进而读取每个Stripe的数据,进而根据Stripe索引获取到对应的RowGroup,然后过滤最终的数据。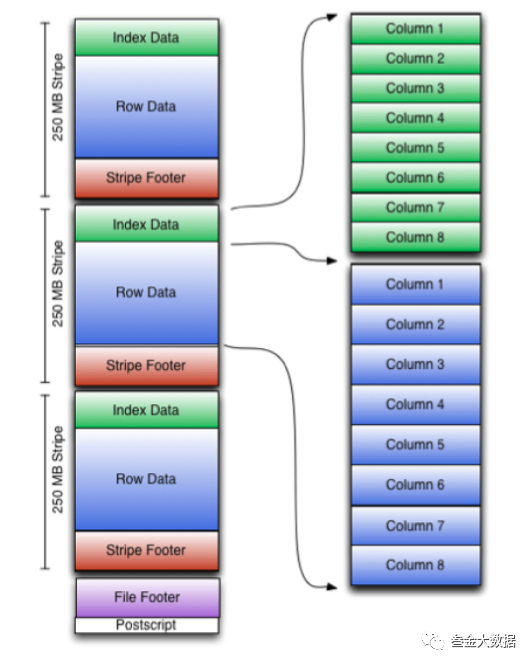
总结:列式存储的优点
- 查询时只需要读取查询所涉及的列,降低IO消耗
- 保存每一列统计信息,实现部分谓词下推
- 每列数据类型一致,可针对不同的数据类型采用其高效的压缩算法
- 列式存储格式假设数据不会发生改变,支持分片、流式读取,更好的适应分布式文件存储的特性
除了OrcFile以外,Parquet也是常用的列式存储格式。他们都是Apache的顶级项目,都是我们常用的列式存储格式,两者各有优劣,我们也可以了解一下Parquet的实现,与上面提到的Orc进行对比。
我选C~






