




点击「京东金融技术说」可快速关注

「摘要」从2014年消费者金融上线白条以来,经过近4年的发展,业务系统成倍的增加,系统架构为了满足业务需要也快速发展。白条核心业务数据库使用mysql做为核心业务库,通过分库分表形式由初期的6主6从变化为N主N从,存储的数据早已超过100亿+,跨机房进行部署。如此大的数据量,白条数据架构经过了三次大的变化,将在接下来内容中一一讲述...
第一次演变
时间:2014.1~2015.5
目的:解决核心和非核心业务系统对关键数据库的访问;提供一个分库分表后白条数据汇总平台;满足财务结算、运营系统、客服系统对白条的数据查询(非核心业务不对主业务库做相关的数据处理)。
白条业务系统(贷、分期、还、逾、退)所生产的数据信息通过MQ异步将数据信息更新到solr集群中,solr集群将数据表信息和collection进行一一对应,collection里做shard(针对不同表的数据shard的个数也不一样) 来分散数据的存储。使用solr+hbase 做为介质,solr做表里需要查询字段的索引,hbase做全量数据存储。

优点
数据写入solr中,少量数据(>30亿)性能非常好,通过solr进行shard部署。
对实时性不是非常高的业务,直接可以查询solr,减少到核心业务库的压力。
缺点
大数据量的写入及查询慢。
当有节点挂了,经常需要重启整体集群来保证集群稳定性。
solr扩展性复杂,业务侵入性大。
第二次演变
时间:2015.6~2016.5
目的:随着业务增加,数据量不断的呈几何倍的增涨,对数据质量及完整性的要求越来越高;结算人员需导入及导出大量线上数据作为结算处理,solr+hbase已满足不了,由此产生了白条mongodb的数据架构。
白条mongodb数据架构是引进nosql 将业务产生的数据信息存入mongodb,使用mongodb 集群来按月来分表,mongodb 集群分为3个mongos 、3个config、3个replica set,replica set里也采用分片来分散数据的存储,通过mongos 和应用系统进行数据交互。
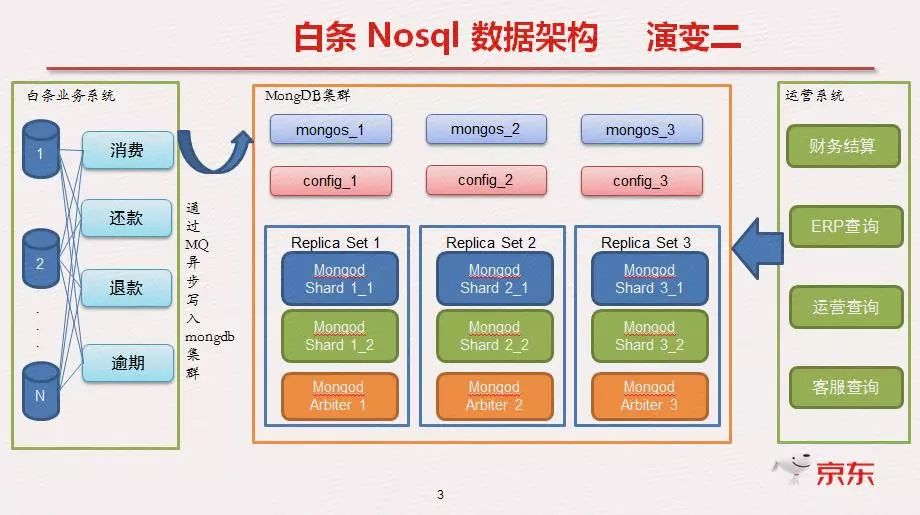
优点:
通过按月来进行分表存储,只查询近一个月的热点数据,速度非常快,性能高。
非结构化数据存储,没有固定的表结构,不用为了修改表结构而进行数据迁移。
缺点:
业务侵入性大,只要有数据更新,就需要在业务里做代码逻辑处理,耦合度太高,复杂。
数据量在>60亿,mongodb架构非常适合。
mongdb比较耗内存,热点数据都放在内存里,以内存换取时间性能。
mongodb容量问题,单台服务器的硬盘容量是固定的,业务成倍扩增长,数据量也增长非常迅速,当超过整个集群的容量时,扩容非常麻烦。因此在做mongodb架构时需要考虑数据量问题,复制集扩展难度大。
第三次演变
时间:2016.10~2017.6
目的:还是业务迅速发展,数据量暴涨(60亿+),对数据的质量及完整性的要求越来越高,业务查询量大, mongodb经常被容量问题所困惑,有性能问题影响。并为财务、运营、客服、对账内部提供高安全、高可靠、高性能的服务
白条大数据平台,通过使用dbrep组件,模拟mysql的slave的方式,实时获取增量binlog,通过解析binglog,采集数据库变动内容,并将变动内容以json格式存储到(kafka)消息系统,消费端通过分布式来消费kafka中的消息数据信息,将消息数据按指定的ES索引列往ES里写入,并写入到Hbase大数据平台,大数据平台内部提供高安全、高可靠、高性能的服务。

Dbrep是基于kafka、zookeeper、flume搭建的准实时数据同步系统,其主要涉及以下几大模块。
Dbrep-node:是dbrep的运行容器,根据配置,其上可以运行dbrep提供的各种agent组件,如数据采集、数据落库等常用数据同步组件。
Dbrep-consumer:以嵌入的方式运行在用户应用程序上,根据配置从消息中间件订阅消息,并交给用户相应的处理器进行处理。
Dbrep-console:dbrep配置管理控制台,负责node和consumer具体配置信息的配置,及状态监控,异常告警等基础功能。
ZK集群:存储dbrep基本配置,以及dbrep各节点间状态协调。
KAFKA集群:存储数据变动记录。
数据实时性强,通过binlog 做mysql 的slave 基本是秒级数据同步。
数据完整性高,准确性高,mysql的binlog 一般不存在丢数据的问题。
易扩展性,不针对业务(无业务侵入),只针对数据库。
支持无限扩容,海量数据。
总 结
白条大数据平台诞生之初正是互联网行业的高速发展期,经历这些年的发展,取得了很大的进步,从草根走向专业,从弱小走向规模,从分散走向统一,从杂乱走向规范。 本文主要讲述了几年来白条大数据平台架构演进的过程,技术架构单独拿出来看我认为没有绝对的好与不好,需要要放在彼时的背景下来看,要考虑业务的时效价值、团队的规模和能力、环境基础设施等等方面。 架构演进的生命周期适时匹配好业务的生命周期,才能发挥最好的效果。

10月京东A座12层,个人业务综合研发部第一届“金专奖”技术大赛终评现场,10位技术高手齐聚一堂,一场巅峰对决精彩上演。台上选手高谈雄辩,台下专家评委妙语连珠,现场精彩纷呈,展示了技术人深厚的专业能力,碰撞出许多思维的火花。
此次大赛,旨在挖掘出更多【T序列】骨干精英,营造技术专业度文化,发现在自己专业领域有突出创造、贡献的专业大咖,增强专业人才的荣誉感和凝聚力,激励团队成员不断提升专业知识,以此引领技术、跟随团队一起为公司做出更大贡献。



京东金融技术说
▼▼▼
原创·实用·技术·专业
不只一技之长
我有N技在手
你看,我写,共成长!



