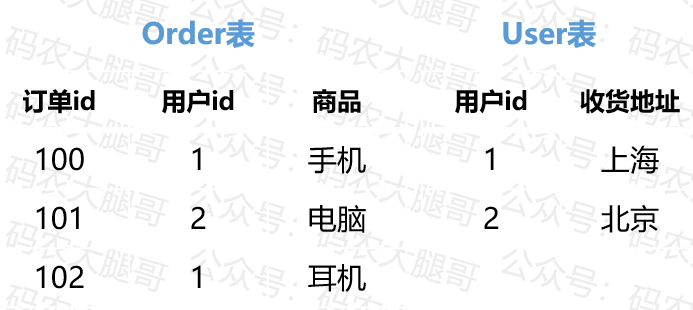
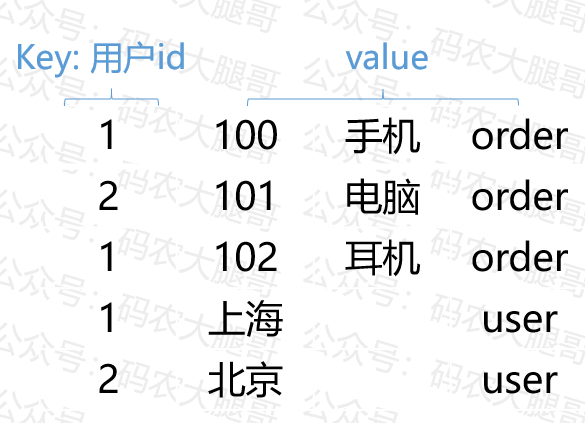


在reduce join的情况下,数据要汇总到reduceTask进行join。这种方式很容易产生数据倾斜,比如有些用户购买力强,一个人下很多订单
所以我们考虑,是不是能让数据在map端就进行join,减轻reduce端的压力
1.map Join原理
文章转载自码农大腿哥,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





在reduce join的情况下,数据要汇总到reduceTask进行join。这种方式很容易产生数据倾斜,比如有些用户购买力强,一个人下很多订单
所以我们考虑,是不是能让数据在map端就进行join,减轻reduce端的压力
1.map Join原理
