




前言:
MapReduce作为一个计算引擎,最重要的就是掌握它的计算流程
不过,MR的计算流程很复杂,涉及的原理和细节很多。所以本篇只介绍主要流程以及一些重要概念
具体的细节会在后面的文章里陆续补充上来
本篇目标:
1.掌握MR程序运行主要流程
2.理解计算过程中的一些重要概念
以WordCount程序为例,一个MapReduce程序的执行流程如下:
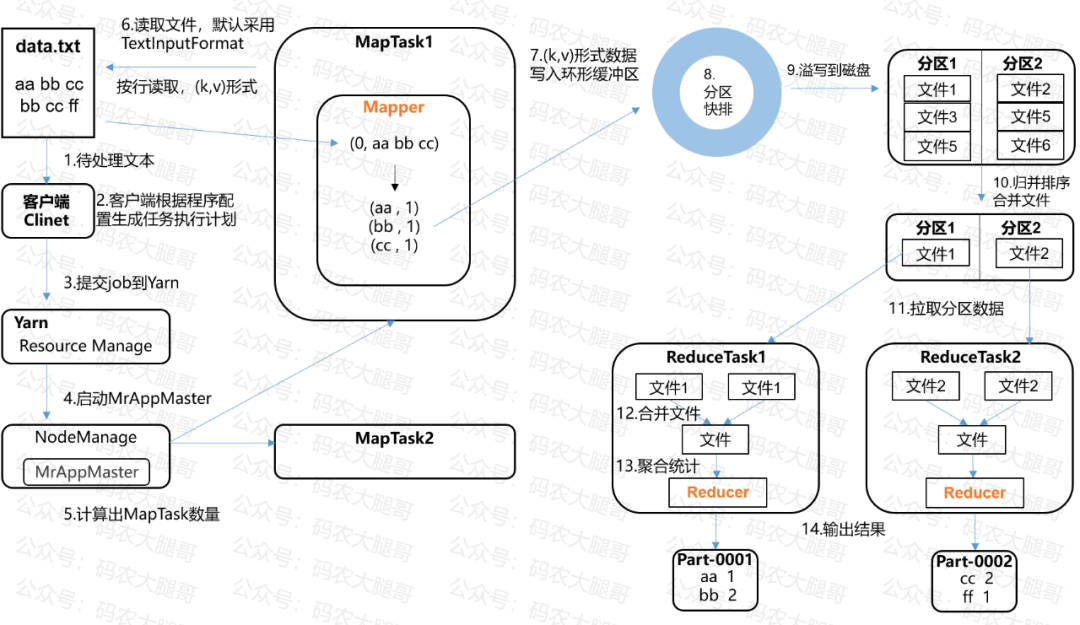
由于过程比较多,下面分成input、map、shuffle、reduce四大部分来说
01
input阶段
1.待处理文件
假设待处理的文本可能是一个200MB的文本文件,里面是一行行单词,存储在HDFS上。那么这个文件应该分成了两个Block存储在不同的DataNode上
2.客户端执行程序
1)WordCount程序要打成jar包,上传到服务器,然后用hadoop命令运行jar包
hadoop jar wc.jar com.bigleg.mr.WordcountDriver /bigleg/input /bigleg/output
2)运行后会根据Driver类里的配置信息生成一个job,也就是一个待执行的作业。job里会包含后面程序运行所需要的配置信息
3.提交job到Yarn集群
作业会发送到Yarn集群上。启动MrAppMaster后会计算程序运行需要多少个MapTask,然后启动MapTask
由于文件被切成了两片,所以这里会启动两个MapTask。两个MapTask读取的数据不一样,但执行过程都是一样的
4.MapTask读取文件内容
文件会一行一行的读取进来,格式为(key,value)形式,key是偏移量,value就是一行单词
读进来之后就进入map阶段,对一行单词进行数据的转换操作了
02
map阶段
map阶段就是执行我们在代码中定义的数据处理逻辑,在WordCount程序中,数据会发生如下变换

在map阶段会,多个MapTask里的执行逻辑是一样的,只是读取的数据不一样。前面说文件是200MB,所以一个读128MB,一个读72MB
由于图片画不了这么多内容,所以只画了一个MapTask的执行过程
03
shuffle阶段
shuffle被称为 "奇迹发生之地" ,也被形象的比喻成 "洗牌"。shuffle过程的作用主要是:将map阶段发过来的数据进行整理分类
shuffle整理数据主要是通过2次排序:
1.分区快排
1)环形缓冲区
图中的圆环叫做 "环形缓冲区",是一块内存。map阶段的数据出来后会先进入到环形缓冲区
2)分区
进入到环形缓冲区的数据会给一个分区的标记。比如a、b开头的单词进入分区1,c、f 开头的单词进入分区2
分区不一定只有两个,后面会对分区进行进一步介绍
3)快排
数据会在内存中进行排序,采用快速排序算法。然后数据会溢出到磁盘
2.归并排序
快速排序溢出到磁盘的文件有很多,比如分区1有好几个文件,分区2有好几个文件
对这几个文件要再进行一次归并排序,分区1合并成一个文件,分区2合并成一个文件
后面分区1的数据发往一个ReduceTask,分区2的数据发往另一个ReduceTask
04
reduce阶段
reduce阶段主要就是负责数据的统计输出,对应图中的11-13步
1)合并文件
本文中的案例启动了两个MapTask,每个MapTask都会产生分区1、分区2这两个文件。分区1会进入一个reduceTask,分区2进入另一个reduceTask
reduceTask对所有分区1的文件进行合并,再进行一次归并排序
2)聚合统计
归并后的数据会按key进行分类,形成如(cc , (1 , 1))格式的数据。然后执行reduce的统计逻辑,得到最后的结果:cc 2
3)结果导出
最后reduceTask将结果数据导出成文件
你学废了吗?
— END —
