




掌握一张HBase表中有哪些组成部分
HBase表各部分之间的关系是怎样的
了解HBase底层存储数据的物理结构
掌握几个有关于HBase表的重要概念
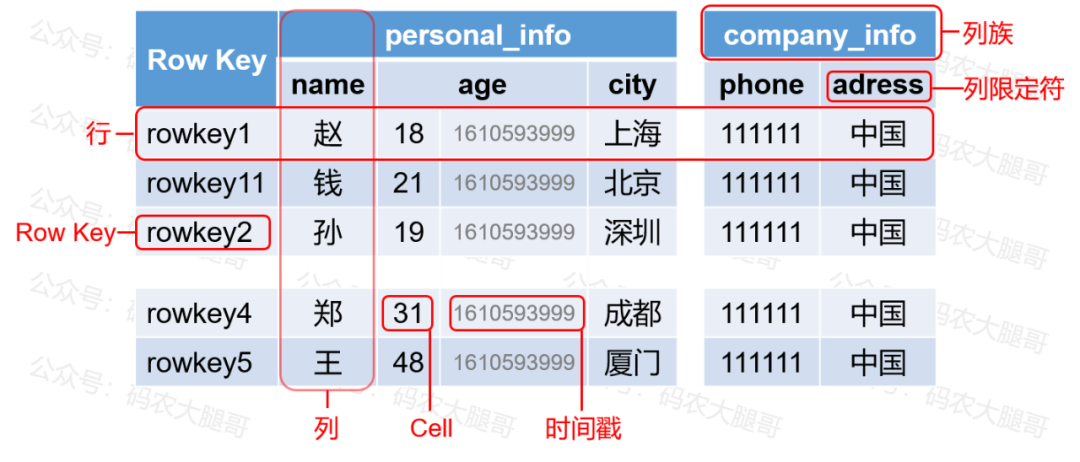
4. Cell-单元格
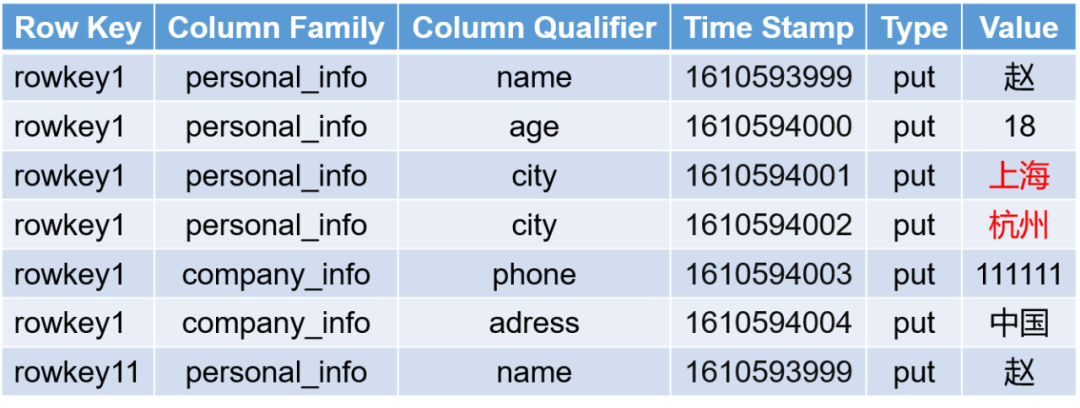
{ "rowkey1": {personal_info: {1610593998 - personal_info : name : "赵"1610593999 - personal_info : age : "18"1610594000 - personal_info : city : "上海" }company_info: {1610593999 - company_info : phone : "111111"1610594000 - company_info : adress : "中国" }}"rowkey11": {personal_info: {1610594001 - personal_info : name : "钱"1610594002 - personal_info : age : "21"1610594003 - personal_info : city : "北京" }company_info: {1610593999 - company_info : phone : "111111"1610594000 - company_info : adress : "中国" }}}复制
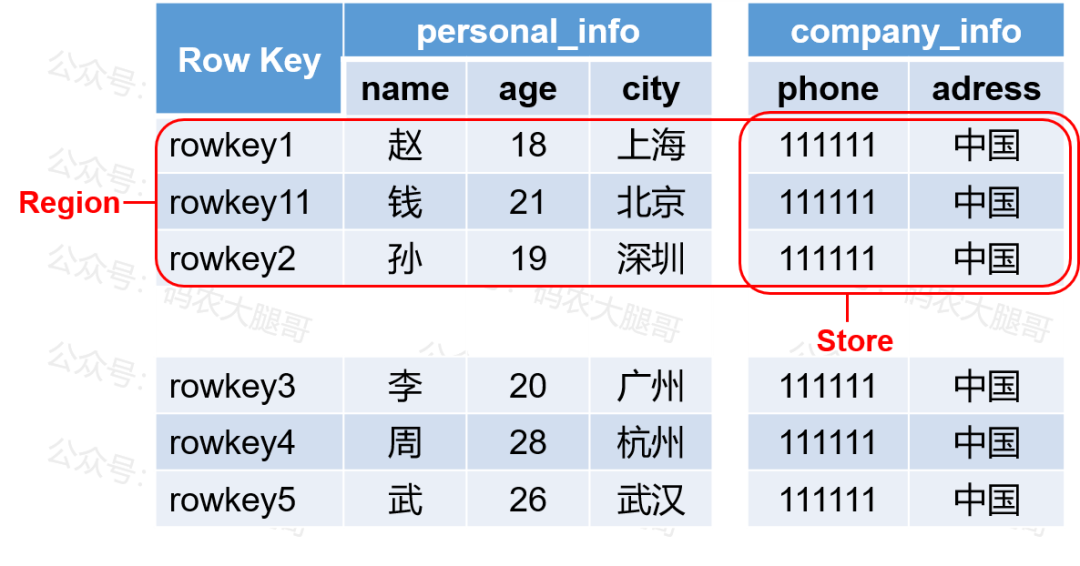
了解了HBase的逻辑结构,我们再来看一下,HBase数据的物理存储结构。
△物理结构图
通过物理结构,还要进一步理解几个知识点:
HBase存储数据的文件是HFile格式的,打开后可以看到数据实际是这样的:

HBase 有两个自带的命名空间,分别是 hbase 和 default。hbase 中存放的是 HBase 内置的表;default 是用户默认使用的命名空间。
文章转载自码农大腿哥,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
