




一、前言
HDFS是hadoop分布式文件系统的缩写和简称,被设计为可在通用廉价的硬件设备上运行的分布式文件系统,HDFS提供了高吞吐量的数据操作,因而被广泛使用在大数据集的存储与处理上。python通过hdfs库即可实现对hdfs文件系统的简单操作,减少大数据开发或者分析者对hadoop开发环境的过多依赖,可快速的推动业务分析的工作。
二、环境准备
·操作系统
操作系统采用的是centOS7,安装方法不再赘述
[root@master code]# cat etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
·python
python版本选择3.6.5,安装方法不再赘述
[root@master code]# python
Python 2.7.5 (default, Aug 4 2017, 00:39:18)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-16)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
·hadoop
hadoop版本号是2.8.4,hive版本号是2.3.4,安装方法不再这里赘述
三、整体思路
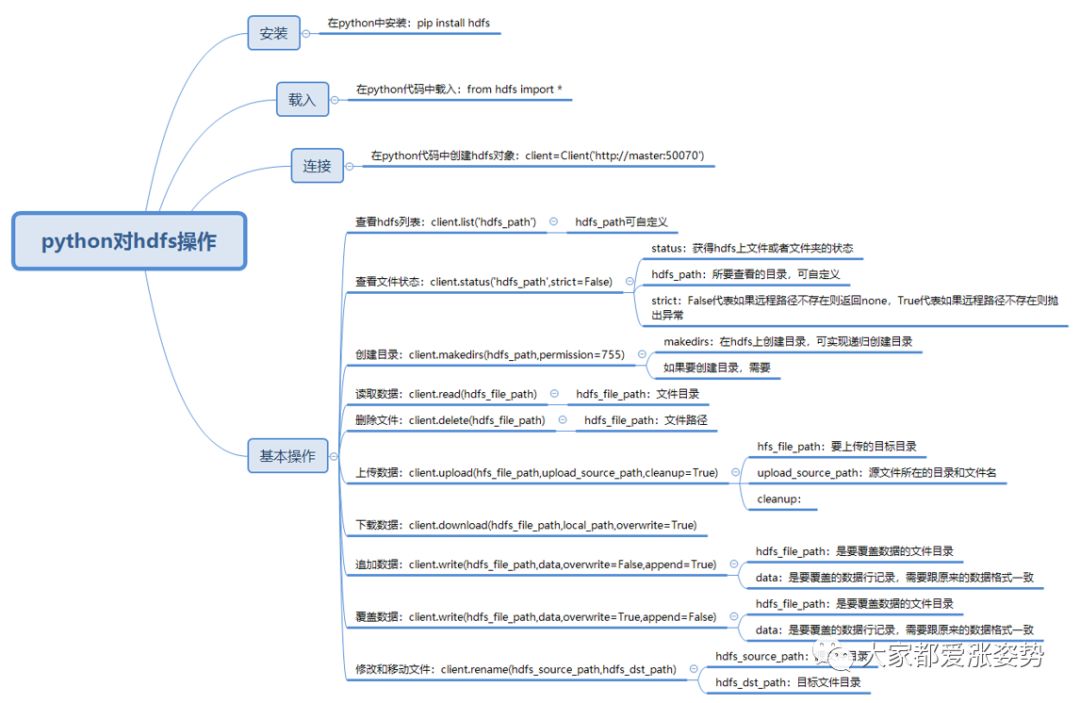
四、具体操作
·安装hdfs库
在命令行,使用pip命令安装,我这里pip名称设置为了pip3,输入命令即可:pip3 install hdfs
·在python代码中载入hdfs库
只要在代码行增加from hdfs import *,即可载入hdfs下的所有库类
[root@master local]# python3
Python 3.6.5 (default, Jul 25 2019, 11:31:27)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from hdfs import *
>>>
·连接hdfs
所谓的连接,其本质是基于hdfs的库类,创建一个名为client的hdfs对象,该对象在初始化的时候,给定了要连接的hdfs路径;
[root@master local]# python3
Python 3.6.5 (default, Jul 25 2019, 11:31:27)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from hdfs import *
>>> client=Client('http://master:50070')
>>>
代码说明:
-client:定义的hdfs对象
-Client:是hdfs库类中创建对象的方法名,方法是Client(hdfspath)
-http://master:50070是所要连接的hdfs的路径
·基本操作
在代码中创建了对象,并连接了hdfs文件系统,则可进行正常操作。
1、查看文件状态
通过client.status(hdfs_path,strict=False)函数获得文件路径的详细信息。
>>> print(client.status('/usr/local/hive/warehouse/'))
{'accessTime': 0, 'blockSize': 0, 'childrenNum': 1, 'fileId': 16395, 'group': 'supergroup', 'length': 0, 'modificationTime': 1564293626279, 'owner': 'root', 'pathSuffix': '', 'permission': '777', 'replication': 0, 'storagePolicy': 0, 'type': 'DIRECTORY'}
2、创建目录
通过client.makedirs(hdfs_path,permission=755)来创建目录,这里我们在hdfs目录下创建一个zzs目录
>>> client.makedirs('/usr/local/hive/warehouse/zzs/',permission=755)
再用hadoop命令查zzs目录是否已经存在了
[root@master ~]# hadoop fs -ls usr/local/hive/warehouse/
Found 2 items
drwxrwxrwx - root supergroup 0 2019-07-28 05:57 usr/local/hive/warehouse/test
drwxr-xr-x - dr.who supergroup 0 2019-07-28 11:05 usr/local/hive/warehouse/zzs
需要注意的是,创建目录需要权限,首先要保证hdfs目录有创建目录的权限,如果提示权限不足,则用hadoop命令先给hdfs目录赋权
hadoop fs -chmod -R 755 /user/local/hive/warehouse/
3、上传数据
通过client.upload(hdfs_file_path,upload_source_path,cleanup=True)函数上传文件到hdfs
首先在本地新建一个文件new_file.txt,内容为"1,apple",然后使用命令将其上传
>>>client.upload('/usr/local/hive/warehouse/zzs/','/root/code/new_file.txt',cleanup=True)
'/usr/local/hive/warehouse/zzs/new_file.txt'
>>>
再用hadoop命令检查是否上传成功
[root@master code]# hadoop fs -ls usr/local/hive/warehouse/zzs
Found 1 items
-rwxr-xr-x 3 dr.who supergroup 8 2019-07-28 11:28 usr/local/hive/warehouse/zzs/new_file.txt
[root@master code]#
再查看下文件里面的内容
[root@master code]# hadoop fs -cat usr/local/hive/warehouse/zzs/new_file.txt
1,apple
4、删除文件
通过client.delete(hdfs_file_path)函数删除hdfs上的文件
>>>client.delete('/usr/local/hive/warehouse/zzs/new_file.txt')
True
>>>
删除成功后返回True
5、下载数据
通过client.download(hdfs_file_path,dst_path,overwrite=True)函数下载hdfs文件
>>>client.download('/usr/local/hive/warehouse/zzs/new_file.txt','/root',overwrite=True)
'/root/new_file.txt'
查看'root'目录下是否已经下载成功
[root@master ~]# pwd
/root
[root@master ~]# ll
total 12
-rw-r--r-- 1 root root 8 Jul 28 11:39 new_file.txt
6、读取文件
通过client.read(hdfs_file_path,encoding='utf8')来获得文件内容
>>> with client.read('/usr/local/hive/warehouse/zzs/new_file.txt',encoding='utf8') as reader:
... for rd in reader:
... print(rd)
...
1,apple
>>>
7、追加数据
通过client.write(hdfs_file_path,data,overwrite=False,append=True)函数来追加数据>>>client.write('/usr/local/hive/warehouse/zzs/new_file.txt','2,orange\n',overwrite=False,append=True)
再通过hadoop命令查看文件内容
[root@master code]# hadoop fs -cat usr/local/hive-2.3.4/warehouse/zzs/new_file.txt
1,apple
2,orange
8、覆盖数据
通过client.write(hdfs_file_path,data,overwrite=True,append=False)函数来覆盖数据
>>>client.write('/usr/local/hiv2.3.4/warehouse/zzs/new_file.txt','3,banana\n',overwrite=True,append=False)
再通过hadoop命令查看文件内容
[root@master code]# hadoop fs -cat usr/local/hive-2.3.4/warehouse/zzs/new_file.txt
3,banana
原先的内容已经被覆盖,只剩下最后一次提交的新数据
9、修改和移动文件
通过client.rename(hdfs_source_path,hdfs_dst_path)函数修改和移动文件
>>>client.rename('/usr/local/hive/warehouse/zzs/new_file.txt','/usr/local/hive/warehouse/zzs/new_file1.txt')
再通过hadoop命令查看文件名称是否改变
[root@master code]# hadoop fs -ls /usr/local/hive-2.3.4/warehouse/zzs/
Found 1 items
-rwxr-xr-x 3 dr.who supergroup 9 2019-07-28 11:57 /usr/local/hive/warehouse/zzs/new_file1.txt
在hdfs上,文件名已经变成了new_file1.txt
10、查看hdfs的所有目录
通过client.list('hdfs_path')函数查看hdfs上制定路径下的所有文件目录
>>> client.list('/usr/local/hive/warehouse/zzs/')
['new_file1.txt']
结果为new_file1.txt,是否我们新建且更换过名称的文件
五、其它
在python对hdfs的操作中,常见的就是hdfs的权限问题,解决hdfs的权限问题通常有两种:
·利用hadoop的授权命令:hadoop fs -chmod -R 755(以及以上权限) hdfs路径
·在hadoop的hdfs-site.xml文件中增加如下配置
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
