前言
最近在学习基于spark环境的开发,看到小伙伴们安装虚拟机,搭建spark集群,然后再配置开发环境,虽然可以学习到很多知识,但是准备时间太长。所以在网上搜集了些资料,整理了一份基于windows系统的spark开发环境的搭建,便于快速的进入开发的学习中。
一、安装前准备
1.jdk
版本号:1.8.0_191
下载地址:http://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-windows-x64.exe
2.scala
版本号:2.11.8
下载地址:https://www.scala-lang.org/download/2.11.8.html
3.spark
版本号:2.3.0
下载地址:http://spark.apache.org/downloads.html
4.hadoop
版本号:2.8.3
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1-src.tar.gz
5.winutils
版本号:基于hadoop-2.8.3
下载地址:https://github.com/steveloughran/winutils/tree/master/hadoop-2.8.3/bin
6.IntelliJ
版本号:
下载地址:https://www.jetbrains.com/idea/download/#section=windows
二、安装与配置
1.安装与配置jdk
在win10环境下安装jdk只要点击下一步即可,安装完成后,系统会自动配置好jdk的环境变量。
在cmd命令行中输入java -version即可查看jdk是否安装成功

如果没有显示出jdk的版本号,说明需要在win10的系统环境变量中配置jdk
1)右击我的电脑>属性>高级系统设置>高级>环境变量>系统变量,新增JAVA_HOME,并输入jdk的安装目录

2)在path环境变量中增加%JAVA_HOME%\bin
2.安装与配置scala
点击安装,常规选择后一直下一步直到完成。
右击我的电脑>属性>高级系统设置>高级>环境变量>系统变量的path里面,配置scala环境变量
在path中追加C:\Program Files (x86)\scala。(默认win10会自动配置好)
在cmd命令行中输入scala -version即可查看scala是否安装成功
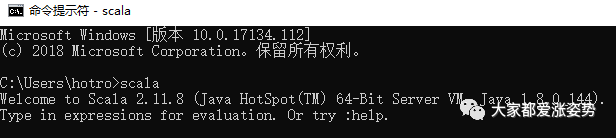
3.安装与配置spark
将spark压缩包解压到划分的目录下。
右击我的电脑>属性>高级系统设置>高级>环境变量>系统变量的path里面,配置spark环境变量
在path中追加C:\spark\spark-2.3.0-bin-hadoop2.7\bin
4.安装与配置hadoop
将hadoop压缩包解压到划分的目录下。
右击我的电脑>属性>高级系统设置>高级>环境变量>系统变量里配置hadoop的环境变量
1)新增HADOOP_HOME,值是解压的目录C:\spark\hadoop-3.1.1
2)在path中追加C:\spark\hadoop-3.1.1\bin
将下载的winutils.exe放在hadoop的bin文件夹下面。
5.验证安装结果
在cmd命令行中输入spark-shell命令
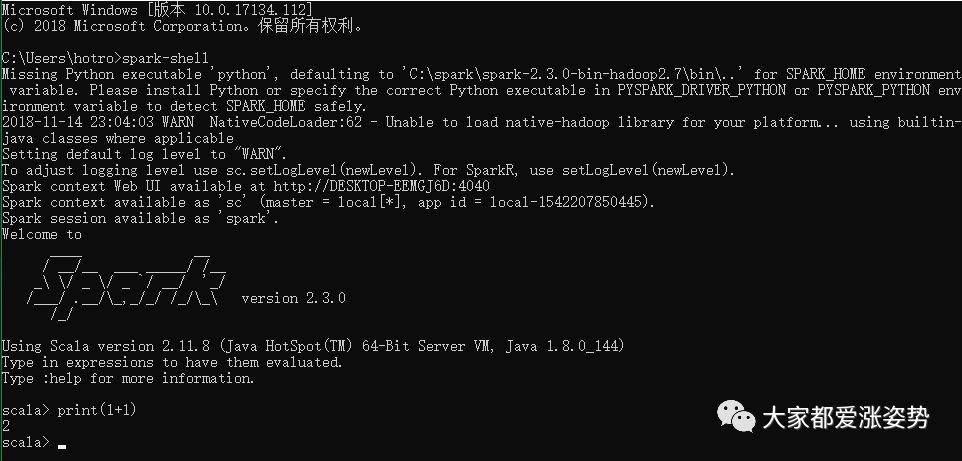
我这里是因为没有安装python,所以一开始提示错误,但是不影响使用。
三、安装IDE
建议使用IntelliJ
一直点击下一步安装成功。
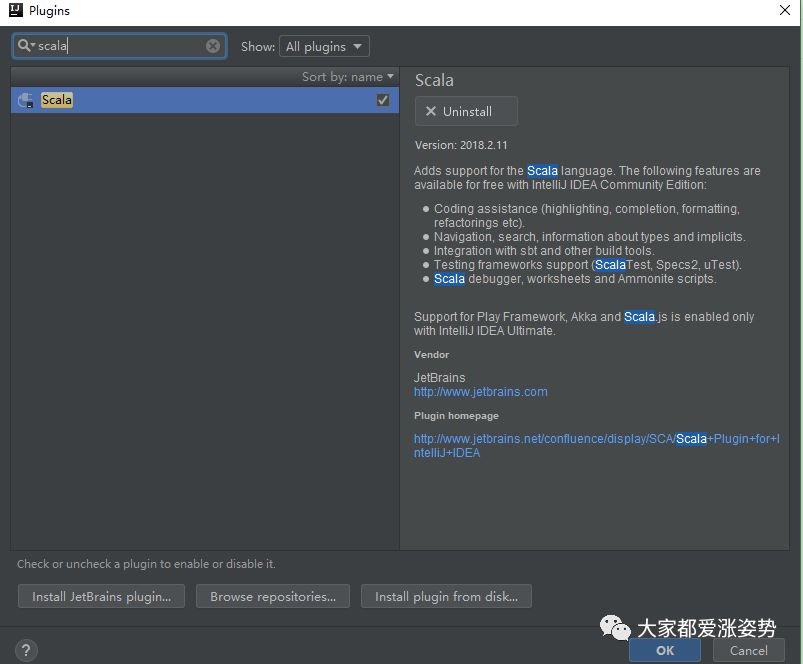
打开IntelliJ,安装scala插件

或者在Configure的Plugins中安装scala

搜索scala,并下载安装
新建项目
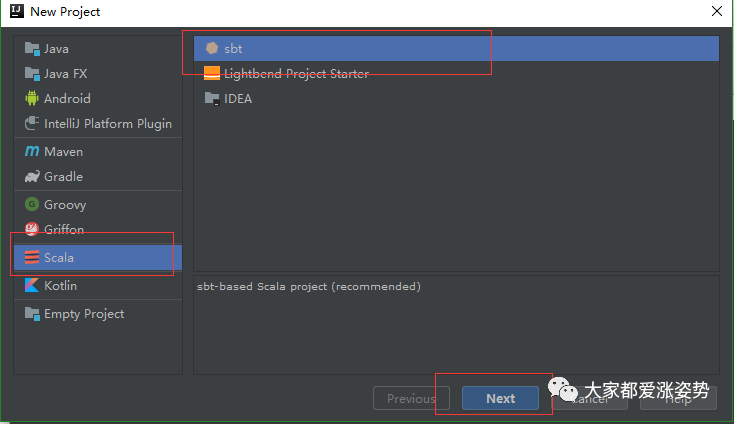
常规设置后再下一步,进入项目,项目的初始化会慢,需要等会儿就好