





作者 | fixlei & jianhuichen
导读
缓存是开发中经常会用到的技术,但是怎么用好却不那么简单。本文简要介绍了缓存的使用场景以及分类,并给出了高并发、大数量场景的解决方案。最重要的是,这个解决方案的多级缓存组件已经内部开源,可以方便接入。
缓存技术存在于的应用场景非常多,从用户请求数据到数据返回,数据经过了浏览器,CDN,代理服务器,应用服务器,以及数据库各个环节,每个环节都可以运用缓存技术,今天我们揭开一下应用级缓存的神秘面纱。
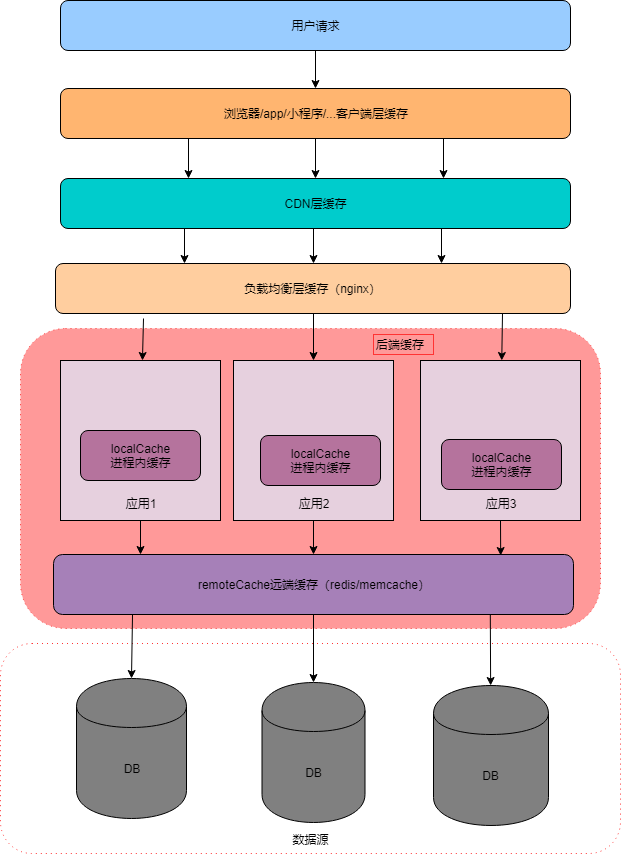
应用服务器可以通过进程内缓存,进程外缓存,远端缓存等递进的方式获取数据,如果以上所有缓存都没有命中数据,才会回源到数据源(库),这一段旅程我们可以称之为后端缓存,这里一般缓存的都是动态业务数据,这部分数据对系统应用是非常重要的,所以我们对后端缓存进行聚焦。
后端缓存可以很好的解决后端应用接口的性能问题,可以说是提升性能的利器,同时,对底层数据源DB有着很好的流量保护作用。但一直以来后端缓存的使用水准对程序员来说要求较高,因为,在分布式环境下使用后端缓存,必然带来应用数据一致性的问题,且使用稍有不慎很容易造成应用服务OOM宕机、缓存雪崩、缓存穿透、缓存击穿等一系列问题,极易引发一些线上的生产事故。如前几年某博一遇明星出轨就宕机。
缓存有各类特征,在目前的应用服务框架中,比较常见根据缓存与应用的耦合度,分为local cache(本地缓存)和remote cache(分布式缓存):
本地缓存
指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个应用内部(也有和应用程序不再一个进程内缓存实现,一般不常见),请求缓存非常快速,没有额外网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适。
同时,它的缺点也是因为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,应用一旦重启,整个缓存数据全部丢失,所有请求都会打到DB。
分布式缓存
指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。缺点,也是因为独立,与应用分离,存在第三方依赖风险。
目前主流的分布式缓存组件就是Redis,使用的分布式缓存,所以数据更新快。缺点也比较明显,依赖 Redis 的稳定性,一旦 Redis 挂了,整个缓存系统不可用,造成缓存雪崩,所有请求打到 DB
多级缓存
第一级缓存使用内存(Caffeine),第二级缓存使用 Redis 。由于大量的缓存读取会导致 L2 的网络成为整个系统的瓶颈,因此 L1 的目标是降低对 L2 的读取次数。该缓存框架主要用于集群环境中。单机也可使用,用于避免应用重启导致的缓存冷启动后对后端业务的冲击。
目前多级缓存主要解决以下问题:
使用内存缓存时,一旦应用重启后,由于缓存数据丢失,缓存雪崩,给数据库造成巨大压力,导致应用堵塞
使用内存缓存时,多个应用节点无法共享缓存数据
使用集中式缓存,由于大量的数据通过缓存获取,导致缓存服务的数据吞吐量太大,带宽跑满。现象就是 Redis 服务负载不高,但是由于机器网卡带宽跑满,导致数据读取非常慢
目前公司内部已经电商,乐卡等多个部门的线上用户端应用接入缓存中间件。对系统整体的性能起到很大的提升。已知其中一个应用整体的QPS上升一倍,接口平均耗时下降一倍。
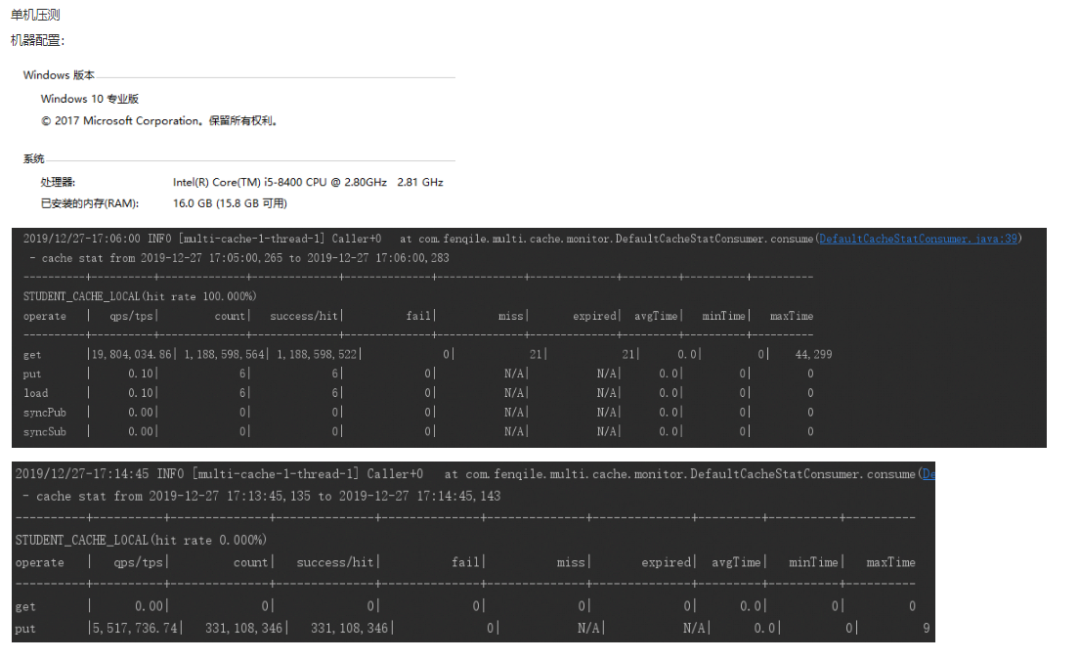
由于项目应用接口收到网络耗时,等其他业务耗时和缓存获取耗时不在一个数量级上,无效完全反应缓存的性能,我们也在开发工作机器上对本地缓存的读取和写入性能做了本地压测。
本地缓存读取QPS:19804034.86
本地缓存写入TPS: 5571736.34
那设计这样一个后端缓存中间件它要解决的需求痛点有哪些呢?经过缓存中间件项目组的一线调研和小组成员的几次深度激烈讨论,我们得出如下关键4点:
1、数据一致性:前置在应用层的本地缓存,如何保障与分布式远端缓存及数据源db的数据一致性?
2、热点探测:如何快速且准确的发现热点访问 key?
3、效果验证:如何让应用层查看本地缓存命中率、热点 key 等数据,验证多级缓存效果?
4、透明接入:中间件如何减少对应用系统的入侵,做到应用快速平滑接入?
可以说多级缓存中间件的设计方案就是为了解决以上4个核心关键问题,用一句话概括:多级缓存中间件是一个用来缓存和管理分布式微服务应用动态数据的中间件,具备多节点之间缓存数据自动同步功能,实现应用缓存数据的最终一致性,应用可通过API式和注解式两种方式引入多级缓存中间件,并秉承约定大于配置的思想做到开箱即用。

end

