




ORC的文件结构
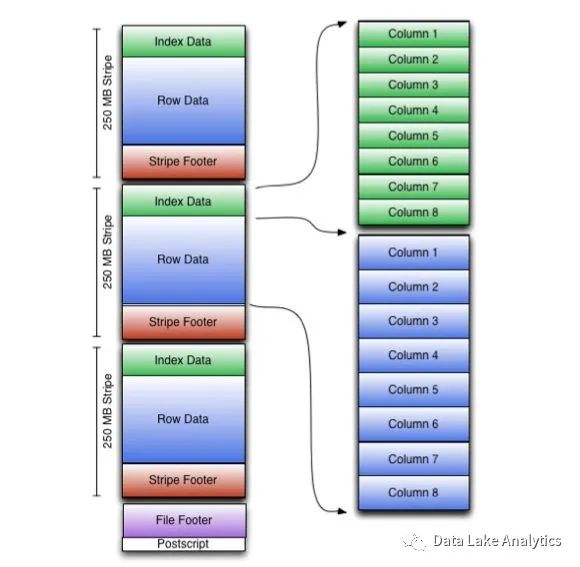
一个ORC的文件包含三大部分: Header, Body以及Footer。
Header部分包含 ORC
这三个字母,这样周边的工具可以通过这个特性来判断文件的类型。
Body部分包含实际的数据,而整个Body又包含一个个的Stripe,每个 Stripe 包含三部分: Index Data
, Row Data
, Stripe Footer
。Index Data部分包含当前这个Stripe里面数据的索引信息,说是索引其实有点不是很合适,它包含的只是每一列的统计信息: 最小值、最大值、是否有NULL, 我么来看一个实际数据的“索引”信息:
Stripe Statistics:
Stripe 1:
Column 0: count: 629760 hasNull: false
Column 1: count: 629760 hasNull: false bytesOnDisk: 81 min: 0 max: 10 sum: 630466
Column 2: count: 629760 hasNull: false bytesOnDisk: 85280 min: hello max: world sum: 19563609
...
从统计信息里面我们可以看到每一列的最小值、最大值,那么对于一些带条件的查询,我们可以通过列的最小值、最大值的范围判断,来看看当前Stripe有没有必要进行扫描,如果要获取的记录不在这个范围内,这个Stripe可以整体跳过,从而提高整体的查询效率。
Footer部分主要包含文件级别的统计信息:有哪些stripe,每个stripe有多少条数据,每个Stripe的位置,同时还有文件级别的统计信息最小值、最大值等等。我们来看一个真实文件的信息:
Stripe[1]: offset: 21978717 data: 4425574 rows: 624640 tail: 476 index: 21987
Stream: column 0 section ROW_INDEX start: 21978717 length 26
Stream: column 1 section ROW_INDEX start: 21978743 length 411
...
Stream: column 1 section DATA start: 22000704 length 67
Stream: column 1 section LENGTH start: 22000771 length 5
...
Stripe[2]: offset: 26426754 data: 2840466 rows: 415069 tail: 464 index: 15684
Stream: column 0 section ROW_INDEX start: 26426754 length 24
Stream: column 1 section ROW_INDEX start: 26426778 length 323
...
从中我们可以看到如下的信息
Stripe[1] 的位置: 21978717
Stripe[1] 的大小: (26426754 - 21978717)
Stripe[1] 实际数据的大小(4425574)
Stripe[1] 数据的行数(624640)
Orc in Presto
我们都知道列存的一个特性是对于分析型的查询效率要比行存要好,原因在于分析型的查询往往只会获取一个表里面的少数几列的数据,这样执行引擎比如 Presto 在实际扫描底层数据的时候只需要扫描需要的列的数据就好了,不需要扫描所有数据。而这种效果只有当你底层的数据是以列存的形式存储才能达到。比如:
SELECT col1
FROM tbl1
WHERE col2 = 'hello'
在这个 SQL 里面我们只需要扫描 col1
和 col2
两列就好了,如果这个表的数据是以ORC的格式进行保存的话,我们只需要扫描 col1
和 col2
的数据就好了, 整体的扫描量会比较低,引擎的执行时间会短。
但是在实际使用过程中我们会发现,如果文件不是很大的话,或者文件不小,但是表的列很多的话,上面说的“节省扫描量”的效果会不起作用,这是因为 Presto 对于是否只扫描单个列,还是获取整个文件是有一个参数调控:
dataSizeSessionProperty(
ORC_TINY_STRIPE_THRESHOLD,
"ORC: Threshold below which an ORC stripe or file will read in its entirety",
hiveClientConfig.getOrcTinyStripeThreshold(),
false)
这个参数的默认值是 8MB
, 所以如果你的 Stripe 太小,Presto 会读取整个文件,而不是读取一个个 Stripe,道理也很简单,如果每个Stripe太小,一次次地读取 Stripe 花在网络上的开销可能比直接读取整个文件的开销还要大,因为读取小文件,特别是云时代的这种对象存储的小文件代价是很大的。
欢迎加入数据湖社区
数据湖开发者社区由 阿里云开发者社区 与 阿里云Data Lake Analytics团队 共同发起,致力于推广数据湖相关技术,包括hudi、delta、spark、presto、oss、元数据、存储加速、格式发现等,学习如何构建数据湖分析系统,打造适合业务的数据架构。扫描下方钉钉群二维码,加入社区一起学习讨论。

阿里云Data Lake Analytics是Serverless化的交互式联邦查询服务。使用标准SQL即可轻松分析与集成对象存储(OSS)、数据库(PostgreSQL/MySQL等)、NoSQL(TableStore等)数据源的数据。
Data Lake Analytics产品详情页:https://www.aliyun.com/product/datalakeanalytics
Data Lake Analytics 1元购入口:https://common-buy.aliyun.com/?commodityCode=openanalytics_post#/buy
