




1. 虚拟机IO的QoS限速
在openstack+ceph的典型云平台架构下,目前有两种主要的方式可对虚拟机的IO进行QoS限速:
一种为通过librbd的镜像IO限速机制进行限速
一种为通过qemu的块设备IO限速机制进行限速
两种qos限速所处位置如下图所示:
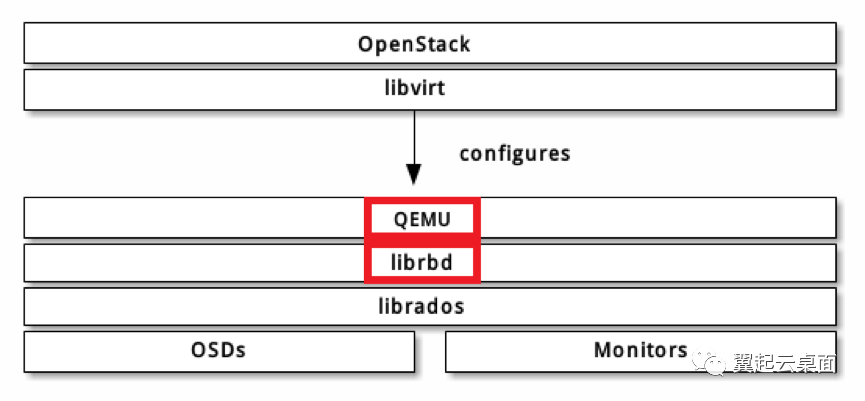
1.1 通过librbd的镜像IO限速机制进行限速
Ceph在13.2.0版本(m版)支持对RBD镜像的IO限速,此版本仅支持总iops场景的限速,且支持突发,支持配置突发速率,但不可控制突发时长(实际相当于突发时长设置为1秒且无法修改)。在14.2.0版本(n版)增加了对读iops、写iops、总bps、读bps、写bps这5种场景的限速支持,对突发的支持效果保持不变。
| 场景 | 基本速率上限配置 | 突发速率配置 |
| 总iops | rbd_qos_iops_limit | rbd_qos_iops_burst |
| 读iops | rbd_qos_iops_read_limit | rbd_qos_iops_read_burst |
| 写iops | rbd_qos_iops_write_limit | rbd_qos_iops_write_burst |
| 总bps | rbd_qos_bps_limit | rbd_qos_bps_burst |
| 读bps | rbd_qos_bps_read_limit | rbd_qos_bps_read_burst |
| 写bps | rbd_qos_bps_write_limit | rbd_qos_bps_write_burst |
1.2 通过qemu的块设备IO限速机制进行限速
Qemu早在1.1版本就已支持块设备IO限速,提供6个配置项,可对上述6种场景分别进行速率上限设置。在1.7版本对块设备IO限速增加了支持突发的功能,以总iops场景为例,支持设置可突发的总iops数量。在2.6版本对支持突发的功能进行了完善,可控制突发速率和时长。
| 场景 | 基本速率上限配置 | 突发速率配置 | 突发时长配置 |
| 总iops | iops-total | iops-total-max | iops-total-max-length |
| 读iops | iops-read | iops-read-max | iops-read-max-length |
| 写iops | iops-write | iops-write-max | iops-write-max-length |
| 总bps | bps-total | bps-total-max | bps-total-max-length |
| 读bps | bps-read | bps-read-max | bps-read-max-length |
| 写bps | bps-write | bps-write-max | bps-write-max-length |
Ceph librbd的镜像IO限速机制使用的是令牌桶算法,而Qemu的块设备IO限速机制主要是通过漏桶算法实现。令牌桶算法和漏桶算法也是最为常见的两种QoS限速算法,最初都是为解决网络层报文限流问题而设计,实际可应用到各种需要实现QoS控制的场景。
算法的实际实现跟算法本身的定义是可能存在一定出入的,第2节先来看看这两种算法的定义和特点,第3和第4节再来分别看看librbd和qemu对算法的实际实现与算法的定义有何不同。
2. QoS限速算法介绍
2.1 令牌桶算法
对于令牌桶算法,维基百科(https://en.wikipedia.org/wiki/Token_bucket)引用的一种定义描述如下:
The token bucket algorithm can be conceptually understood as follows:
A token is added to the bucket every 1/r seconds.
The bucket can hold at the most b tokens. If a token arrives when the bucket is full, it is discarded.
When a packet (network layer PDU) of n bytes arrives,
if at least n tokens are in the bucket, n tokens are removed from the bucket, and the packet is sent to the network.
if fewer than n tokens are available, no tokens are removed from the bucket, and the packet is considered to be non-conformant.
这段描述算是通俗易懂,以限制IO请求iops为例,替换上述的网络层报文,我们可以理解如下:
一个固定容量的桶装着一定数量的令牌,桶的容量即令牌数量上限。桶里的令牌每隔固定间隔补充一个,直到桶被装满。一个IO请求将消耗一个令牌,如果桶里有令牌,则该IO请求消耗令牌后放行,反之则无法放行。
对于限制IO请求bps,只需让一个IO请求消耗n个令牌即可,n即为此IO请求的字节数。
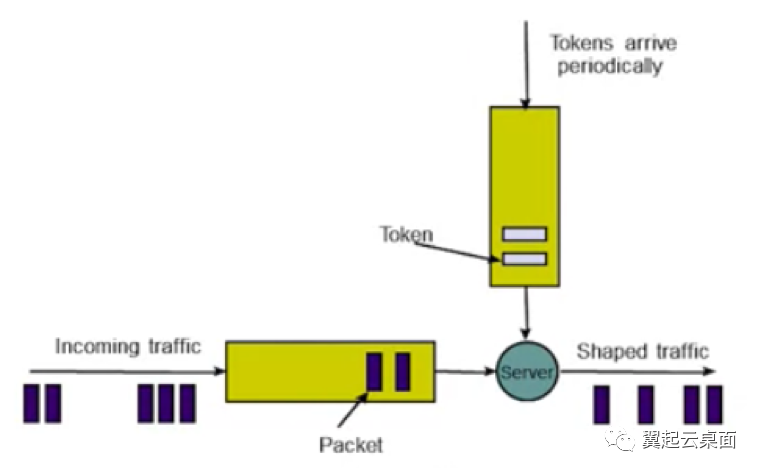
按照以上描述,我们可以知道,令牌桶算法可以达到以下效果:
令牌桶算法可以通过控制令牌补充速率来控制处理IO请求的速率;
令牌桶算法允许一定程度的突发,只要桶里的令牌没有耗尽,IO请求即可立即消耗令牌并放行,这段时间内IO请求处理速率将大于令牌补充速率,令牌补充速率实际为平均处理速率;
令牌桶算法无法控制突发速率上限和突发时长,突发时长由实际IO请求速率决定,若实际IO请求大于令牌补充速率且速率恒定,则:突发时长=令牌桶容量/(实际IO请求速率-令牌补充速率)
在令牌桶算法的描述中,有一个条件是无强制约束的,那就是在桶里的令牌耗尽时,无法放行的packet(或者是IO请求)该怎么处理。对于处理网络层报文,实际无外乎三种方式:
第一种是直接丢弃(traffic policing,流量监管)
第二种则是排队等待直到令牌桶完成所缺失数量令牌补充后再消耗令牌放行(traffic shaping,流量整形)
第三种为前两者的折中,设定有限长度队列,在队列已满时丢弃,否则遵循第二种处理方式。当然对于不可随意丢弃的IO请求,处理方式一般为第二种。
此外,一般在实际的实现中,难以做到严格按照固定时间间隔一次补充一个令牌。可考虑的替代方案一般为,加大补充令牌的时间间隔,减少补充次数,但一次补充多个令牌,单次补充令牌的个数与时间间隔成正比。
对于令牌桶算法,我们还可以考虑一种极端的情况。令牌桶算法支持突发的能力是由令牌桶的容量决定的,以限制IO请求iops为例,假设我们将令牌桶容量仅设为1,此时令牌桶算法支持突发的能力也就不复存在了,IO请求速率上限即被严格控制为令牌补充速率。
2.2 漏桶算法
对于漏桶算法,维基百科(https://en.wikipedia.org/wiki/Leaky_bucket)中有两种类型的定义,一种是leaky bucket as a meter,一种是leaky bucket as a queue。
对于leaky bucket as a meter,引用的一种定义描述如下:
A fixed capacity bucket, associated with each virtual connection or user, leaks at a fixed rate.
λ If the bucket is empty, it stops leaking.For a packet to conform, it has to be possible to add a specific amount of water to the bucket: The specific amount added by a conforming packet can be the same for all packets, or can be proportional to the length of the packet.
If this amount of water would cause the bucket to exceed its capacity then the packet does not conform and the water in the bucket is left unchanged.
而对于leaky bucket as a queue,引用的一种定义描述如下:
The leaky bucket consists of a finite queue.
When a packet arrives, if there is room on the queue it is appended to the queue; otherwise it is discarded.
At every clock tick one packet is transmitted (unless the queue is empty)
先来看leaky bucket as a meter的定义描述,同样以限制IO请求iops为例,替换上述的网络层报文,我们可以理解如下:
一个桶,容量固定。桶以固定的速率漏水,除非桶为空。一个IO请求将往桶里增加固定量的水,假如增加的水量将导致桶里的水溢出,则该IO请求无法放行,反之则放行。
再把令牌桶的理解放在这里对比下:一个固定容量的桶装着一定数量的令牌,桶的容量即令牌数量上限。桶里的令牌每隔固定间隔补充一个,直到桶被装满。一个IO请求将消耗一个令牌,如果桶里有令牌,则该IO请求消耗令牌后放行,反之则无法放行。
实际上,把漏水换成补充令牌,把加水换成消耗令牌,再细细品读,我们可以发现,这两段描述的含义就是一样的,仅仅是角度不一样而已。所以leaky bucket as a meter与token bucket可认为是等价的。
再来看leaky bucket as a queue,我们可以理解如下:
漏桶实际为一个有限长队列。当一个报文到达时,假如队列未满,则入队等待,反之则被丢弃。在队列不为空时,每个固定时间间隔处理一个报文。
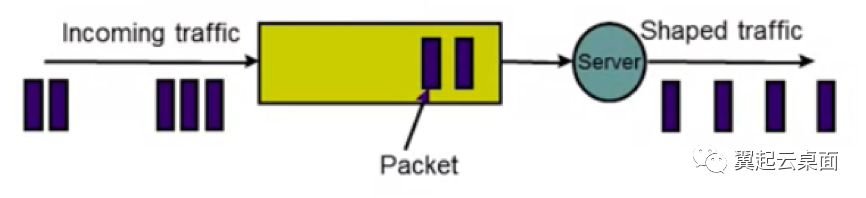
虽然描述更为简单,但我们可以看到,leaky bucket as a queue比leaky bucket as a meter的要求严格多了,leaky bucket as a queue可以达到以下效果:
leaky bucket as a queue可以通过控制处理时间间隔来严格控制速率上限;
leaky bucket as a queue不支持任何程度的突发;
leaky bucket as a queue对超出限定速率的报文可能做入队等待处理,也可能做直接丢弃处理,当队列长度设置为足够小,设置为0时,可认为等同于全部做直接丢弃处理(traffic policing),而队列长度设置为足够大时,可认为等同于全部做入队等待处理(traffic shaping)。
如此一来,我们可以看到,leaky bucket as a queue实际效果与令牌桶容量为1的令牌桶算法是一致的,也就是说leaky bucket as a queue其实可视为令牌桶算法的一种特例(不支持突发)。
以上我们是基于维基百科对漏桶算法的定义进行分析的。我们平时所提的漏桶算法,或者说对于漏桶算法较为狭义的定义,实际与维基百科leaky bucket as a queue的描述更为一致。而平时所提的令牌桶算法,则默认桶容量较大,能够支持突发。
3. Librbd限速机制
librbd的限速机制支持突发,支持配置突发速率,但不支持控制突发时长,这与2.1节令牌桶算法定义描述的效果近乎一致。而从实际的实现来看,librbd的令牌桶算法实现也的确与定义比较匹配。
3.1 Librbd的令牌桶算法实现
Librbd的限速机制支持突发,支持配置突发速率,但不支持控制突发时长,这与2.1节令牌桶算法定义描述的效果近乎一致。而从实际的实现来看,librbd的令牌桶算法实现也的确与定义比较匹配。
class TokenBucketThrottle {
struct Bucket {
CephContext *cct;
const std::string name;
uint64_t remain;
uint64_t max;
Bucket(CephContext *cct, const std::string &name, uint64_t m)
: cct(cct), name(name), remain(m), max(m) {}
uint64_t get(uint64_t c);
uint64_t put(uint64_t c);
void set_max(uint64_t m);
};
struct Blocker {
uint64_t tokens_requested;
Context *ctx;
Blocker(uint64_t _tokens_requested, Context* _ctx)
: tokens_requested(_tokens_requested), ctx(_ctx) {}
};
CephContext *m_cct;
const std::string m_name;
Bucket m_throttle;
uint64_t m_avg = 0;
uint64_t m_burst = 0;
SafeTimer *m_timer;
Mutex *m_timer_lock;
FunctionContext *m_token_ctx = nullptr;
list<Blocker> m_blockers;
Mutex m_lock;
minimum of the filling period.
uint64_t m_tick_min = 50;
tokens filling period, its unit is millisecond.
uint64_t m_tick = 0;
uint64_t m_ticks_per_second = 0;
uint64_t m_current_tick = 0;
period for the bucket filling tokens, its unit is seconds.
double m_schedule_tick = 1.0;
public:
TokenBucketThrottle(CephContext *cct, const std::string &name,
uint64_t capacity, uint64_t avg,
SafeTimer *timer, Mutex *timer_lock);
~TokenBucketThrottle();
const std::string &get_name() {
return m_name;
}
template <typename T, typename I, void(T::*MF)(int, I*, uint64_t)>
void add_blocker(uint64_t c, T *handler, I *item, uint64_t flag);
template <typename T, typename I, void(T::*MF)(int, I*, uint64_t)>
bool get(uint64_t c, T *handler, I *item, uint64_t flag);
int set_limit(uint64_t average, uint64_t burst);
void set_schedule_tick_min(uint64_t tick);
private:
uint64_t tokens_filled(double tick);
uint64_t tokens_this_tick();
void add_tokens();
void schedule_timer();
void cancel_timer();
};
Bucket结构体定义了作为核心概念的桶。结构体成员变量max和remain分别代表令牌桶的容量和桶内令牌的数量,结构体成员函数get()即消耗令牌,put()即补充令牌,这也是算法的核心,此外set_max()可设置令牌桶容量。TokenBucketThrottle的成员变量m_throttle即为Bucket结构体类型。
uint64_t TokenBucketThrottle::Bucket::get(uint64_t c) {
if (0 == max) {
return 0;
}
uint64_t got = 0;
if (remain >= c) {
There is enough token in bucket, take c.
got = c;
remain -= c;
} else {
There is not enough, take all remain.
got = remain;
remain = 0;
}
return got;
}
uint64_t TokenBucketThrottle::Bucket::put(uint64_t c) {
if (0 == max) {
return 0;
}
if (c) {
put c tokens into bucket
uint64_t current = remain;
if ((current + c) <= max) {
remain += c;
} else {
remain = max;
}
}
return remain;
}
Blocker结构体定义了一个被阻塞的请求。结构体成员变量tokens_requested代表该请求仍需消耗令牌的数量。TokenBucketThrottle的成员变量m_blockers是一个列表,列表成员为Blocker结构体,代表被阻塞请求的队列。在2.1节提到令牌桶里的令牌耗尽时,无法放行的IO请求的一般做入队处理,此处的m_blockers正是起到该作用。
TokenBucketThrottle的成员变量m_avg和m_burst分别代表基本速率上限和突发速率,由用户配置决定,以限制IO请求iops为例,即分别对应第1节所提的配置项rbd_qos_iops_limit和rbd_qos_iops_burst。m_avg和m_burst在成员函数set_limit()中设置,特别需要注意的是,在set_limit()中,还对令牌桶的容量进行了设置,在设置了突发的情况下,令牌桶容量大小设置为突发速率值,反之则设置为基本速率值。此外,令牌补充速率也与基本速率上限m_avg相等:
int TokenBucketThrottle::set_limit(uint64_t average, uint64_t burst) {
{
std::lock_guard<Mutex> lock(m_lock);
if (0 < burst && burst < average) {
the burst should never less than the average.
return -EINVAL;
}
m_avg = average;
m_burst = burst;
if (0 == average) {
The limit is not set, and no tokens will be put into the bucket.
So, we can schedule the timer slowly, or even cancel it.
m_tick = 1000;
} else {
calculate the tick(ms), don't less than the minimum.
m_tick = 1000 average;
if (m_tick < m_tick_min) {
m_tick = m_tick_min;
}
this is for the number(avg) can not be divisible.
m_ticks_per_second = 1000 m_tick;
m_current_tick = 0;
for the default configuration of burst.
m_throttle.set_max(0 == burst ? average : burst);
}
turn millisecond to second
m_schedule_tick = m_tick 1000.0;
}
The schedule period will be changed when the average rate is set.
{
std::lock_guard<Mutex> timer_locker(*m_timer_lock);
cancel_timer();
schedule_timer();
}
return 0;
}
在2.1节中还提到,在令牌桶算法实际的实现中,难以做到严格按照固定时间间隔一次补充一个令牌,一般考虑加大补充令牌的时间间隔,减少补充次数,但一次补充多个令牌。成员变量m_tick_min即为补充令牌的最小时间间隔(单位为毫秒),且该值可由用户配置,配置项为rbd_qos_schedule_tick_min。成员变量m_ticks_per_second即每秒补充令牌的次数,每次补充令牌的数量在成员函数tokens_this_tick()中计算所得。m_tick_min在成员函数set_schedule_tick_min()中设置:
void TokenBucketThrottle::set_schedule_tick_min(uint64_t tick) {
std::lock_guard lock(m_lock);
if (tick != 0) {
m_tick_min = tick;
}
}
补充令牌的动作和时间间隔控制由成员变量m_timer(SafeTimer结构体类型,在common/timer.cc及.h文件中定义)完成。m_timer通过创建一个新的线程,周期性执行任务,实现按照设定的时间间隔补充令牌。
3.2 Librbd对算法的调用
Librbd在ImageRequestWQ类(在librbd/io/ImageRequestWQ.cc及.h文件中定义)中实现了对令牌桶算法的全部调用,所调用的接口为4个。
首先是初始化。对TokenBucketThrottle的对象初始化实际在本身的对象初始化时完成,由下面所展示代码可看出,TokenBucketThrottle对象的数量为6,实际分别用于对总iops、读iops、写iops、总bps、读bps、写bps共6种场景的QoS控制。
static std::map<uint64_t, std::string> throttle_flags = {
{ RBD_QOS_IOPS_THROTTLE, "rbd_qos_iops_throttle" },
{ RBD_QOS_BPS_THROTTLE, "rbd_qos_bps_throttle" },
{ RBD_QOS_READ_IOPS_THROTTLE, "rbd_qos_read_iops_throttle" },
{ RBD_QOS_WRITE_IOPS_THROTTLE, "rbd_qos_write_iops_throttle" },
{ RBD_QOS_READ_BPS_THROTTLE, "rbd_qos_read_bps_throttle" },
{ RBD_QOS_WRITE_BPS_THROTTLE, "rbd_qos_write_bps_throttle" }
};
template <typename I>
ImageRequestWQ<I>::ImageRequestWQ(I *image_ctx, const string &name,
time_t ti, ThreadPool *tp)
: ThreadPool::PointerWQ<ImageDispatchSpec<I> >(name, ti, 0, tp),
m_image_ctx(*image_ctx),
m_lock(util::unique_lock_name("ImageRequestWQ<I>::m_lock", this)) {
CephContext *cct = m_image_ctx.cct;
ldout(cct, 5) << "ictx=" << image_ctx << dendl;
SafeTimer *timer;
Mutex *timer_lock;
ImageCtx::get_timer_instance(cct, &timer, &timer_lock);
for (auto flag : throttle_flags) {
m_throttles.push_back(make_pair(
flag.first,
new TokenBucketThrottle(cct, flag.second, 0, 0, timer, timer_lock)));
}
this->register_work_queue();
}
其次是配置,包含2个接口,set_limit(uint64_t average, uint64_t burst)以及set_schedule_tick_min(uint64_t tick),前者设置基本速率上限和突发速率,后者设置补充令牌的最小时间间隔。
template <typename I>
void ImageRequestWQ<I>::apply_qos_schedule_tick_min(uint64_t tick){
for (auto pair : m_throttles) {
pair.second->set_schedule_tick_min(tick);
}
}
template <typename I>
void ImageRequestWQ<I>::apply_qos_limit(const uint64_t flag,
uint64_t limit,
uint64_t burst) {
CephContext *cct = m_image_ctx.cct;
TokenBucketThrottle *throttle = nullptr;
for (auto pair : m_throttles) {
if (flag == pair.first) {
throttle = pair.second;
break;
}
}
ceph_assert(throttle != nullptr);
int r = throttle->set_limit(limit, burst);
if (r < 0) {
lderr(cct) << throttle->get_name() << ": invalid qos parameter: "
<< "burst(" << burst << ") is less than "
<< "limit(" << limit << ")" << dendl;
if apply failed, we should at least make sure the limit works.
throttle->set_limit(limit, 0);
}
if (limit)
m_qos_enabled_flag |= flag;
else
m_qos_enabled_flag &= ~flag;
}
最后是令牌的消耗,调用get接口实现。
bool ImageRequestWQ<I>::needs_throttle(ImageDispatchSpec<I> *item) {
uint64_t tokens = 0;
uint64_t flag = 0;
bool blocked = false;
TokenBucketThrottle* throttle = nullptr;
for (auto t : m_throttles) {
flag = t.first;
if (item->was_throttled(flag))
continue;
if (!(m_qos_enabled_flag & flag)) {
item->set_throttled(flag);
continue;
}
throttle = t.second;
tokens = item->tokens_requested(flag);
if (throttle->get<ImageRequestWQ<I>, ImageDispatchSpec<I>,
&ImageRequestWQ<I>::handle_throttle_ready>(
tokens, this, item, flag)) {
blocked = true;
} else {
item->set_throttled(flag);
}
}
return blocked;
}
在TokenBucketThrottle类中,成员函数get()的实现如下,此处对请求是否放行进行了判断(令牌桶数量不足时请求放入m_blockers队列),并通过调用m_throttle令牌桶的get()函数完成令牌的实际消耗。
bool get(uint64_t c, T *handler, I *item, uint64_t flag) {
if (0 == c)
return false;
bool wait = false;
uint64_t got = 0;
std::lock_guard lock(m_lock);
if (!m_blockers.empty()) {
Keep the order of requests, add item after previous blocked requests.
wait = true;
} else {
if (0 == m_throttle.max || 0 == m_avg)
return false;
got = m_throttle.get(c);
if (got < c) {
Not enough tokens, add a blocker for it.
wait = true;
}
}
if (wait)
add_blocker<T, I, MF>(c - got, handler, item, flag);
return wait;
}
Librbd对令牌桶算法的使用可总结为下图:
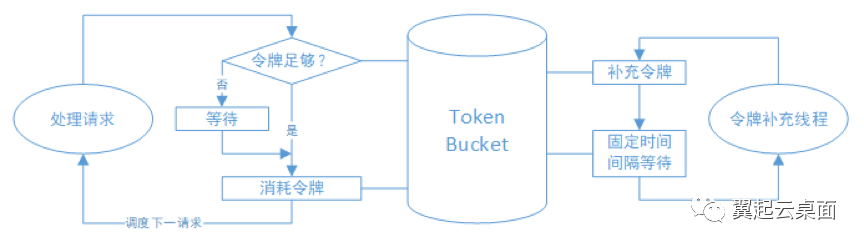
3.3 Librbd限速机制特点
Librbd使用了6个令牌桶,所以可对6种场景独立进行QoS限速,若这些场景的QoS限速全部配置启用,那么一个I/O请求需在每一个令牌桶消耗相应数目的令牌后才可被放行(当然,写请求在限制读速率的桶无需消耗令牌,反之亦然)。
令牌桶的容量由基本速率上限值或突发速率值决定,而且突发速率值的唯一作用就是用于配置令牌桶容量。
从2.1节令牌桶算法的效果分析来看,只要令牌桶容量不是足够小,该令牌桶算法即支持突发。所以即使未设置突发速率,令牌桶容量由于为基本速率值,实际也是支持突发的,套用2.1节的计算公式,突发时长=基本速率值/(实际IO请求速率-基本速率)。
此外,令牌桶算法本身无法控制突发速率上限,所以设置所谓的突发速率其实并没有对真正对速率上限进行限制,只是通过增大令牌桶容量而客观地增大了突发时长,突发时长=突发速率值/(实际IO请求速率-基本速率)。
此处以限制iops来举个实际例子,基本速率设置为1000iops,突发速率设置为2000iops,假如实际IO请求速率恰好为2000iops,那么突发时长实际就支持2秒。而且实际IO请求速率并没有得到限制,假如达到了5000iops,那么实际突发时长仅为0.5秒,即0.5秒后,速率就被稳定限制在1000iops。可见Librbd的突发速率概念还是很容易给人带来误解的,实际应理解为可突发的I/O请求量。
Librbd的令牌桶算法实现中,加大了补充令牌的时间间隔,一次补充多个令牌,此方式有助于减小算法的运行开销。在令牌补充的一瞬间到令牌消耗完这段时间内,IO请求由于获得了足够的令牌数量,可被快速放行,而一旦令牌耗尽,超过QoS限速的请求则陷入排队等待的状态,等待时间即为令牌补充的时间间隔,甚至更多。IO请求延迟的分布也将呈现出一个明显的特点,后续第5节将有所呈现。
4. Qemu限速机制
在第1节中提到,qemu在2.6版本中不仅支持突发,可支持控制突发速率和时长。qemu的块设备IO限速机制使用的算法是漏桶算法,而在2.2节的漏桶算法定义描述中,不管是leaky bucket as a meter,还是leaky bucket as a queue,都未提及支持控制突发速率和时长,可见qemu的漏桶算法是经过了优化改良的。
4.1 Qemu的漏桶算法实现
Qemu的漏桶算法在util/throttle.c及.h文件中实现。
typedef struct LeakyBucket {
uint64_t avg; * average goal in units per second */
uint64_t max; * leaky bucket max burst in units */
double level; * bucket level in units */
double burst_level; * bucket level in units (for computing bursts) */
uint64_t burst_length; * max length of the burst period, in seconds */
} LeakyBucket;
LeakyBucket结构体定义了作为核心概念的桶。成员变量avg、max和burst_length分别代表基本速率上限、突发速率和突发时长,由用户配置决定,以限制IO请求iops为例,即分别对应第1节所提的配置项iops-total、iops-total-max和iops-total-max-length。LeakyBucket结构体实际可以认为定义两个桶,成员变量level可代表大桶的水量,而burst_level可代表突发小桶的水量。
桶容量并未在结构体中直接定义,而是在函数throttle_compute_wait()中根据结构体成员变量avg、max、burst_length的值计算所得。若未设置突发,则大桶容量为基本速率值的1/10,小桶容量为0;若设置突发,则大桶容量为突发速率与突发时长的乘积,小桶容量为突发速率值的1/10。
函数throttle_compute_wait()最重要的功能就在于判断请求是否可以被放行,即桶的空余容量是否满足该请求所需的增加量。该函数的返回值为该请求需等待放行的时间,若等待时间为0,则说明请求无需等待即可被放行。可以看到,在大桶已满的情况下,请求将以基本速率上限处理放行,对于大桶未满的情况,若未设置突发,请求可直接放行,而若设置突发,则需判断小桶是否已满,小桶已满则将以突发速率处理放行,否则可直接放行。
int64_t throttle_compute_wait(LeakyBucket *bkt)
{
double extra; * the number of extra units blocking the io */
double bucket_size; * I/O before throttling to bkt->avg */
double burst_bucket_size; * Before throttling to bkt->max */
if (!bkt->avg) {
return 0;
}
if (!bkt->max) {
* If bkt->max is 0 we still want to allow short bursts of I/O
* from the guest, otherwise every other request will be throttled
* and performance will suffer considerably. */
bucket_size = (double) bkt->avg 10;
burst_bucket_size = 0;
} else {
* If we have a burst limit then we have to wait until all I/O
* at burst rate has finished before throttling to bkt->avg */
bucket_size = bkt->max * bkt->burst_length;
burst_bucket_size = (double) bkt->max 10;
}
* If the main bucket is full then we have to wait */
extra = bkt->level - bucket_size;
if (extra > 0) {
return throttle_do_compute_wait(bkt->avg, extra);
}
* If the main bucket is not full yet we still have to check the
* burst bucket in order to enforce the burst limit */
if (bkt->burst_length > 1) {
assert(bkt->max > 0); * see throttle_is_valid() */
extra = bkt->burst_level - burst_bucket_size;
if (extra > 0) {
return throttle_do_compute_wait(bkt->max, extra);
}
}
return 0;
}
实际的加水和漏水操作分别由函数throttle_account和throttle_do_leak实现,可以看到小桶以突发速率漏水,大桶以基本速率漏水。
void throttle_account(ThrottleState *ts, bool is_write, uint64_t size)
{
const BucketType bucket_types_size[2][2] = {
{ THROTTLE_BPS_TOTAL, THROTTLE_BPS_READ },
{ THROTTLE_BPS_TOTAL, THROTTLE_BPS_WRITE }
};
const BucketType bucket_types_units[2][2] = {
{ THROTTLE_OPS_TOTAL, THROTTLE_OPS_READ },
{ THROTTLE_OPS_TOTAL, THROTTLE_OPS_WRITE }
};
double units = 1.0;
unsigned i;
* if cfg.op_size is defined and smaller than size we compute unit count */
if (ts->cfg.op_size && size > ts->cfg.op_size) {
units = (double) size ts->cfg.op_size;
}
for (i = 0; i < 2; i++) {
LeakyBucket *bkt;
bkt = &ts->cfg.buckets[bucket_types_size[is_write][i]];
bkt->level += size;
if (bkt->burst_length > 1) {
bkt->burst_level += size;
}
bkt = &ts->cfg.buckets[bucket_types_units[is_write][i]];
bkt->level += units;
if (bkt->burst_length > 1) {
bkt->burst_level += units;
}
}
}
void throttle_leak_bucket(LeakyBucket *bkt, int64_t delta_ns)
{
double leak;
/* compute how much to leak */
leak = (bkt->avg * (double) delta_ns) / NANOSECONDS_PER_SECOND;
/* make the bucket leak */
bkt->level = MAX(bkt->level - leak, 0);
/* if we allow bursts for more than one second we also need to
* keep track of bkt->burst_level so the bkt->max goal per second
* is attained */
if (bkt->burst_length > 1) {
leak = (bkt->max * (double) delta_ns) / NANOSECONDS_PER_SECOND;
bkt->burst_level = MAX(bkt->burst_level - leak, 0);
}
}
4.2 Qemu对算法的调用
Qemu在函数throttle_group_co_io_limits_intercept(在block/throttle-groups.c文件中实现)和fsdev_co_throttle_request(在fsdev/qemu-fsdev-throttle.c文件中实现)中实现了对算法的调用。而对块设备IO的限速显然为前者,后者不再赘述。
函数throttle_group_co_io_limits_intercept实现如下,与算法相关的调用主要为函数throttle_group_schedule_timer()和throttle_account()。
void coroutine_fn throttle_group_co_io_limits_intercept(ThrottleGroupMember *tgm, unsigned int bytes, bool is_write)
{
bool must_wait;
ThrottleGroupMember *token;
ThrottleGroup *tg = container_of(tgm->throttle_state, ThrottleGroup, ts);
qemu_mutex_lock(&tg->lock);
/* First we check if this I/O has to be throttled. */
token = next_throttle_token(tgm, is_write);
must_wait = throttle_group_schedule_timer(token, is_write);
/* Wait if there's a timer set or queued requests of this type */
if (must_wait || tgm->pending_reqs[is_write]) {
tgm->pending_reqs[is_write]++;
qemu_mutex_unlock(&tg->lock);
qemu_co_mutex_lock(&tgm->throttled_reqs_lock);
qemu_co_queue_wait(&tgm->throttled_reqs[is_write],
&tgm->throttled_reqs_lock);
qemu_co_mutex_unlock(&tgm->throttled_reqs_lock);
qemu_mutex_lock(&tg->lock);
tgm->pending_reqs[is_write]--;
}
/* The I/O will be executed, so do the accounting */
throttle_account(tgm->throttle_state, is_write, bytes);
/* Schedule the next request */
schedule_next_request(tgm, is_write);
qemu_mutex_unlock(&tg->lock);
}
函数throttle_group_schedule_timer()内部的详细调用流程为下图所示:
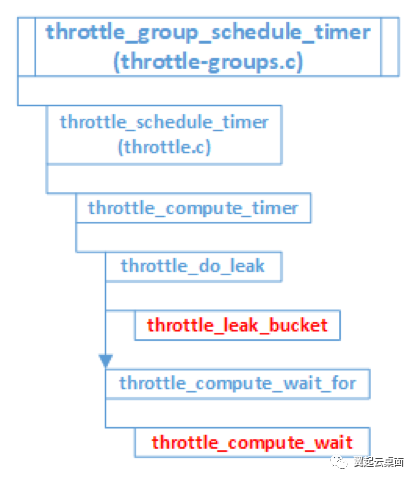
函数throttle_group_co_io_limits_intercept在处理一个请求时即同步完成了4.1节中所提及的throttle_compute_wait()、throttle_leak_bucket()、throttle_account()三个核心函数的调用。
Qemu对漏桶算法的使用可总结为下图:
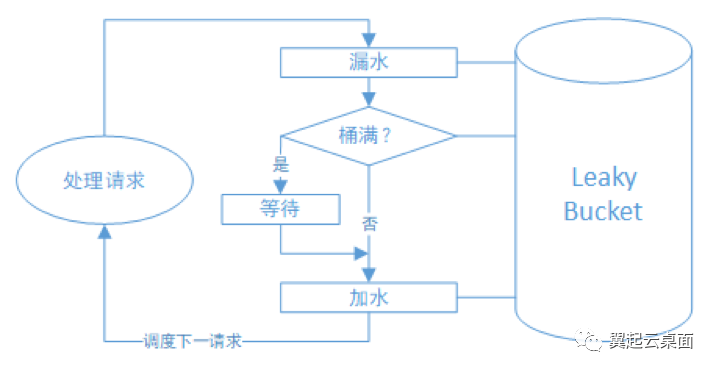
4.3 Qemu限速机制特点
Qemu同样使用了多个桶,以对6种场景独立进行QoS限速。
Qemu通过大桶和突发小桶的设计,支持了对突发速率和突发时长的控制。有突发流量到来时,限速分为3个阶段:首先是突发小桶未满时,未做速率限制,但此突发小桶的容量仅设置为突发速率值的1/10,所以此阶段所经历的时间特别短,效果可忽略不计;其次是突发小桶已满而大桶未满的阶段,速率即被限制为突发速率,由于大桶在不断地以基本速率漏水,所以实际的突发时长要大于设置的突发时长,此阶段的实际突发时长为:实际突发时长=大桶容量/(突发速率-基本速率上限),而大桶容量=突发速率*设置突发时长。最后是大桶已满的阶段,此时速率就被限制为基本速率上限了。
在不考虑突发的情况下,从算法效果来看,qemu实现的漏桶算法实际为桶容量很小的令牌桶算法,当然也因为桶容量足够小,所以基本可视为我们狭义理解上的漏桶算法。
与librbd固定时间间隔补充令牌不同,qemu在处理每个请求时同步执行漏水操作,每秒执行漏水操作的次数实际与每秒IO请求数量相等,漏水频率一般远大于librbd补充令牌的频率。这也形成了一个特点,在QoS限速情况下,qemu处理IO请求的时间点分布比较均匀,而librbd则相对集中在补充令牌的时间点上。同时IO请求延迟的分布特点也与librbd有明显的不同。
5. QoS限速测试
5.1 测试场景与条件
本次测试旨在对比使用librbd限速机制和qemu限速机制情况下,虚拟机IO操作体验的异同。
测试环境为openstack+ceph,使用openstack创建后端为ceph块存储的CentOS7虚拟机,测试场景为限制总iops为5000(因librbd未有效支持突发,故不考虑设置突发速率),测试方法为使用fio工具进行4k随机写,测试命令如下:
# fio -direct=1 -iodepth=128 -rw=randwrite -ioengine=libaio -bs=4k -size=10G -numjobs=1 -runtime=600 -group_reporting -filename=/opt/fiotest/fiotest.txt -name=Rand_Write_IOPS_Test
备注:
我们将iodepth设置为128,保证足够的写并发。
此外,为了突出对比效果,我们将librbd的rbd_qos_schedule_tick_min配置项从默认值50改为1000,即补充令牌的时间间隔为1000毫秒。
5.2 测试结果与分析
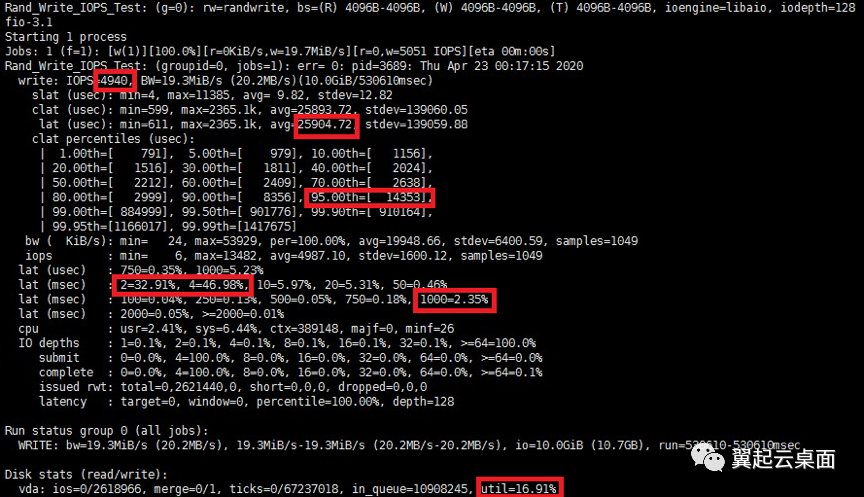
Librbd的限速测试结果如下:
Qemu限速的测试结果如下:
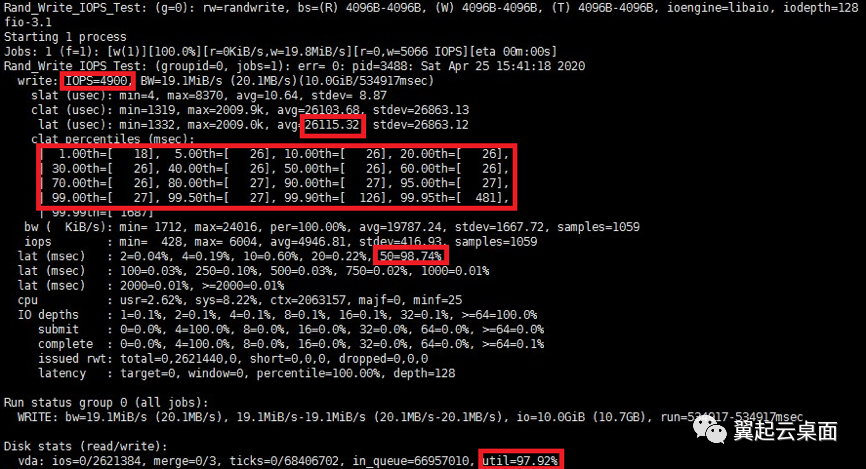
首先,在这两项测试中,iops的限制均达到预期,为4900左右。其次IO请求平均时延均为26毫秒左右,效果相等。测试中IO并发设置为128,而iops限制为5000,理论上来说,平均时延(秒)=IO并发数/iops,即128/5000=0.0256秒=25.6毫秒。可以看出测试结果和理论值也是比较接近的。
测试结果中有两项明显的不同。
一是IO请求的时延分布。Librbd限速下的测试结果显示,IO请求的延迟集中在4毫秒以下,95%的请求延迟在15毫秒内,但是有超过2%的请求有接近1000ms的时延。而对于qemu限速,IO请求的延迟绝大部分集中在25-26毫秒之间,但没有出现像librbd一样有一定比例请求出现超高延迟。此结果是librbd令牌桶算法补充令牌方式和qemu漏桶算法漏水方式不同的典型体现。
对于librbd,由于设置为1000毫秒补充1次令牌,所以部分请求需要等待接近1000毫秒才被处理,而这部分请求的数量与iodepth并发数是相等的。在上述的测试条件下,在1次补充令牌的周期内(即1000毫秒),有128个请求出现长时间的等待,而其余的5000-128个请求可被快速处理,所以接近1000毫秒时延的请求比例的理论值应为128/5000=2.56%,测试结果的2.3%与理论值比较接近。
而对于qemu,由于IO请求一个一个被处理,被处理一个后,新的一个又加入等待,所以每个IO请求的等待时延都差不多,漏桶漏速为5000每秒,即平均0.2ms处理一个请求,并发数为128,所以等待队列长度同为128,也可以算出每个IO请求等待时延的理论值,即平均时延理论值,为0.2*128=25.6毫秒。
二是虚拟磁盘的util值。Librbd限速下的测试结果显示磁盘的util值为16%左右,而qemu限速下的util值接近于100%。
磁盘util值定义为磁盘处理IO时间占总时间的比例。Qemu的限速方式导致处理IO的时间点分布均匀,虽实际总处理量并不多,但IO请求一个一个断断续续地被处理,磁盘难以被判定为空闲,util值自然较高。而librbd的限速方式,由于处理IO的时间点集中在补充令牌时刻,而且此次测试中设置的补充令牌时间间隔高达1000ms,所以IO请求大部分时间处于排队等待令牌的状态。此外,并发数也是有限的,IO请求长时间则阻塞也不会造成新的IO请求产生,所以磁盘大部分时间被判定为空闲,util值就较低。
当然,假如将librbd补充令牌的时间间隔设小,譬如保持在默认值50毫秒不变,可以预见util值也会升高,而IO请求延迟的分布也会产生相应的变化。
6. 总结
虚拟机IO的QoS限速一般可通过librbd或qemu实现,其中qemu对突发的支持更加完善。
Librbd使用令牌桶算法,而qemu使用漏桶算法,两者对算法的实际实现与算法本身的定义描述不完全相同。
维基百科对漏桶算法的定义分两类,其中一类leaky bucket as a meter等价于令牌桶算法,另一类leaky bucket as a queue可视为令牌桶算法的一种特例(不支持突发),平时所提的漏桶算法一般为狭义理解,即后者。
Librbd的令牌桶算法实现基本与定义描述基本一致,仅加大了补充令牌的时间间隔(可设置),一次补充多个令牌,以减小算法的运行开销。
Librbd的突发速率概念容易给人带来误解,实际无法控制突发速率上限,且以此概念进行突发速率设置,突发时长仅可维持特别短的时间,达不到应有效果。
Qemu的漏桶算法,在不考虑突发速率和时间控制的情况下,实际为桶容量为基本速率值1/10的令牌桶算法,由于桶容量足够小,已近乎等同于狭义理解上的漏桶算法(leaky bucket as a queue)。
Qemu通过大小桶的方式支持控制突发速率上限和突发时长,由于桶一直在漏水,所以实际突发时长一般大于设置的突发时长。
Librbd的限速算法与qemu相比有两大不同,一是librbd无法像qemu一样控制突发速率上限和突发时长,二是librbd补充令牌的方式和qemu漏水的方式不同,前者导致请求被处理的时间点较为集中,类似于一批一批地处理,后者则使请求被处理的时间点分布均匀,类似于一个一个地处理。
从测试结果上可以看到,同等条件下,IO请求平均时延接近于相等,而qemu的限速机制让每个IO请求的延迟都接近于平均时延,librbd的限速机制则使大部分IO请求有较低的延迟,但有一定比例的IO请求延迟很高,接近于补充令牌的时间间隔。
