




背景
近年,大数据领域涌现出了多种多样的数据存储、数据计算的框架或工具,但是却没有统一的标准,外加大数据技术之间的层层壁垒,导致了门槛高和不够稳定两个问题。
第一个问题实际上包括了学习曲线陡峭、可维护性低、部署不可控等。
各种数据源从存储格式到执行引擎,都有非常大的差别。由于SQL是目前被广泛接受的行业标准,且门槛很低,所以部分数据源或者计算引擎提供了对SQL的支持。尽管如此,各种数据源对SQL的支持度也很不统一,有些数据源还引入了SQL之外的语法,他们可以被归类为SQL-like;还有一些数据源没有提供SQL的支持,尤其是一些NoSQL数据库。用户如果想要使用多种数据源,就不得不学习每种数据源自身的API或者非标准SQL。
一些数据源(例如:Druid)所提供的API有很多的可读性问题,降低了系统的可维护性。
一些数据源或者计算引擎在部署的时候,需要安装各种环境、配置大量的配置。导致一些系统在部署之后,除了用户代码需要调整外,还很难升级或保持向前兼容。
这些现状,对于用户来说,无论从学习成本上,还是开发周期上,乃至于线上产品的升级、更新都带来了不小的挑战。
另一个问题实际指的是分布式任务执行的稳定性较差。大数据技术由于分布式、主备切换、负载均衡等设计导致的异构、异地、分布式、跨机房的部署方式,最终会引起内存资源限制、I/O限制、带宽打满、跨机房传输、CPU跑满、资源隔离等问题;分布式任务处理的数据来自各个不同的业务,每种业务所产生的数据在数据体量、数据产生速度、数据特征等方面都有巨大的差别,因此分布式任务往往会出现数据倾斜、内存溢出、Full GC、空值等一系列问题。
为了解决这些痛点,360统一计算团队开发了一个低门槛、易部署、更稳定的多数据源分布式查询引擎——XSQL。XSQL将致力于降低数据使用的门槛;另一方面, XSQL将致力于提供更加稳定的分布式查询服务。
XSQL介绍

XSQL是一款低门槛、更稳定、多数据源的分布式查询引擎。它允许你快速、近实时地查询大量数据。对于一些数据源(例如:Elasticsearch、Druid等),他可以大幅地降低学习曲线,并节省人力成本。除Hive外,每种数据源都支持下推到具体数据源的执行优化。
通过XSQL提供的多数据源联邦,你将可以避免数据迁移和时间浪费,更加专注于业务本身。XSQL可以通过下推、并行计算、迭代计算等底层支撑技术,对各种数据源的查询加速。
XSQL的特点与特性
XSQL的主要特点
XSQL的主要特点包括:低门槛、更稳定、增效节能及数据联邦。
低门槛
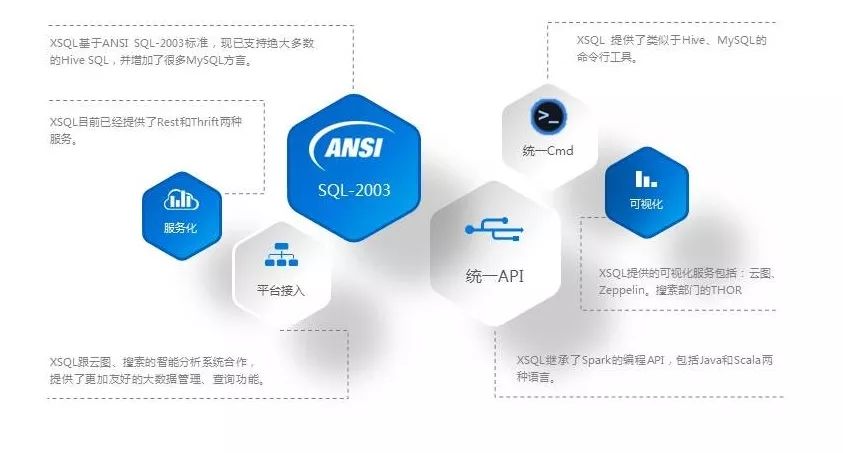
XSQL的低门槛围绕着SQL来进行,具体内容如下图所示:
更稳定
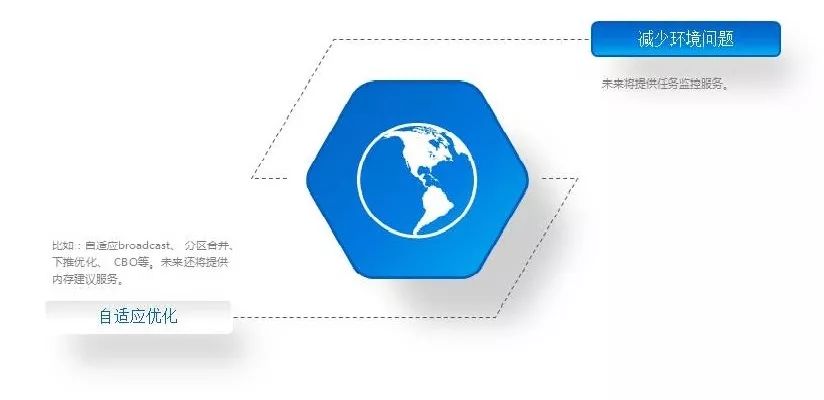
分布式任务的稳定性主要有两个原因:环境问题和数据问题。环境问题对于计算来说是不可控的,这很大程度上取决于你的集群配置、集群繁忙度、网络状况等因素。但是XSQL可以提供一系列插件来监控或者分析这些外界因素。当然,XSQL更大的优势在于解决数据问题。比如:自适应broadcast、 分区合并、下推优化、 CBO等。未来还将提供内存建议服务。
增效节能
任务的稳定性可以避免任务的重复计算,进而节省资源。

此外,XSQL将对一些功能持续进行优化,进而提升开发和数据处理效率。XSQL也会紧跟Spark社区,借鉴社区里的优秀设计和思想。随着执行效率的提升,大量的计算和存储资源将被释放出来,供给更多的任务使用。
XSQL还将在多计算引擎的方向进行探索,针对不同的场景,找出最优的引擎。
数据联邦
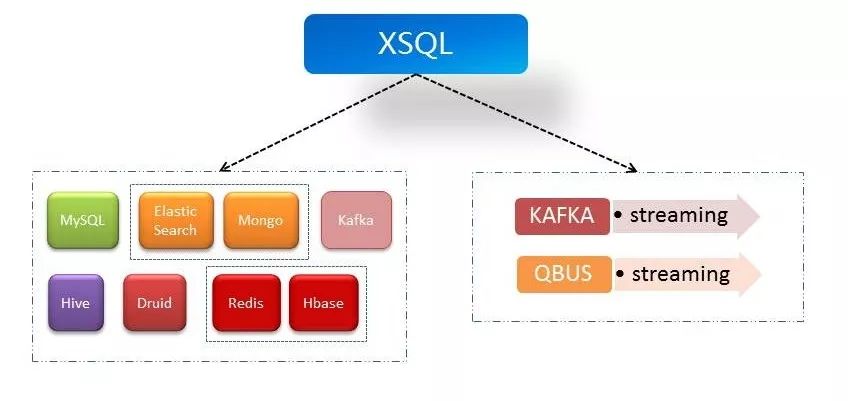
XSQL支持对多种异构数据源的关联查询。目前已经支持9种数据源,包括:Hive、Mysql、EleasticSearch、Mongo、Kafka、Hbase、Redis、Druid等。本文将在XSQL特性介绍——数据源联邦一节,给出一个简单的例子。
XSQL特性介绍
数据源联邦
XSQL对不同数据源之间的关联查询提供了支持。这里以EleasticSearch和MongoDB之间的关联来举个例子,如下图所示:

从上图可以看出,EleasticSearch和MongoDB都是三层的表示。初次了解XSQL的用户可能会产生困惑,这跟XSQL的三层元数据设计有关。其中:mymongo和myes是数据源别名,一般由用户指定;xsql_mongodb是mymongo中的一个数据库实例的名称,xsql_index是myes中的一个index的名称;student是xsql_mongodb中一个collection的名称,class_room是xsql_index中一个type的名称。
延迟Yarn交互
Spark目前的版本都存在一个问题,那就是无论执行DDL、DML还是Query,都需要立马向集群注册应用,并申请资源。对于DDL和DML,这是完全没有必要的。此外,由于XSQL提供了下推执行,所以当Query可以下推到数据源时,也是没有必要申请集群资源的。XSQL延迟向集群注册应用,延迟向集群申请资源的机制,在很多场景能够大大减少资源的浪费,并且提高任务执行效率几十倍以上。
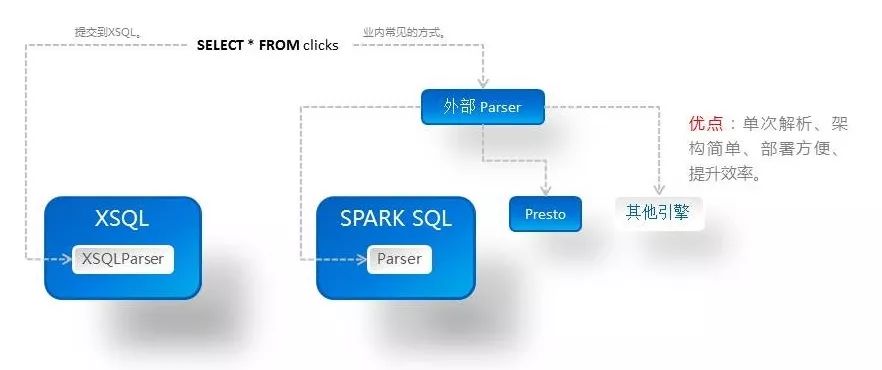
一次SQL解析
XSQL在开发之初,就参考了业内其他具有类似功能的框架或系统,发现大多数的实现都需要两次甚至多次的SQL解析。这是因为这些平台往往构建在具体引擎和数据源的上层,最初的SQL解析不能真正运用于计算,而是为了定位、路由。XSQL团队在深入理解了Spark SQL原理的基础上,开发了XSQL内核,能够做到对Spark SQL的完整替换、版本兼容,而且与Spark的其他模块之前没有任何依赖或者耦合,易于随着Spark版本的升级而升级。下图简要说明了XSQL一次SQL解析的原理。
Pushdown优化
一些计算引擎在执行Query时,往往考虑了更加通用的方式,但是没有针对具体的业务场景、数据源差异,这时的执行效率往往差强人意。一个很明显的例子就是,如果对MySQL一张行数在千万以内的表进行查询,特别是利用了其索引的情况下,执行效率比多数计算引擎都要快几百甚至上万倍。XSQL为了充分利用各种计算引擎以及数据源各自的优势,发明了下推执行。Pushdown的执行计划甚至可以参与到更加复杂的Spark执行计划中,如下图所示:
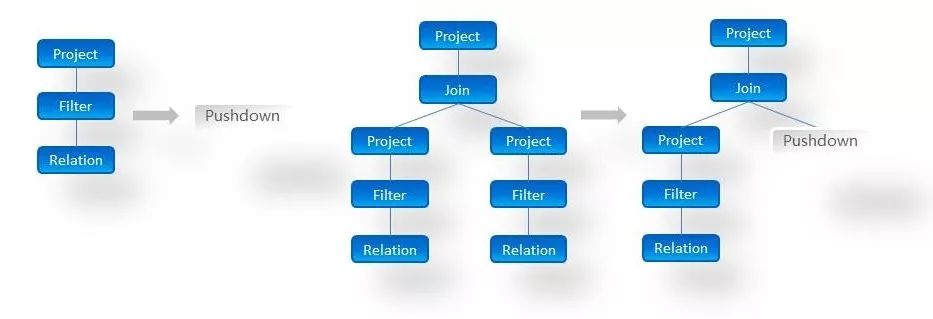
上图左边是简单的Pushdown优化,右边是较为复杂的Pushdown优化。
元数据去中心
XSQL团队在设计阶段,对业内诸多类似平台进行了调研,发现凡是数据源自身进行元数据管理的,元数据管理也是最大的痛点。当一个平台站在上帝视角,管理众生时,他不得不为了满足众生的需求,东奔西跑。放弃元数据的中心化可以避免数据同步、数据不一致,数据延迟等不利因素。XSQL也因此在部署上更加轻量、简便。XSQL通过缓存与实时获取元数据相结合的方式,避免了元数据管理的臃肿。此外,这种设计也将在部署和运维中带来收益——部署变得更加简单,并且不需要强制依赖任何的外部存储。下图简要展示了XSQL的元数据去中心设计。
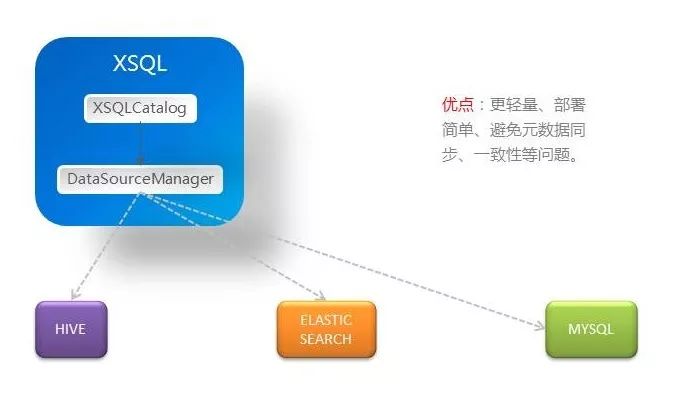
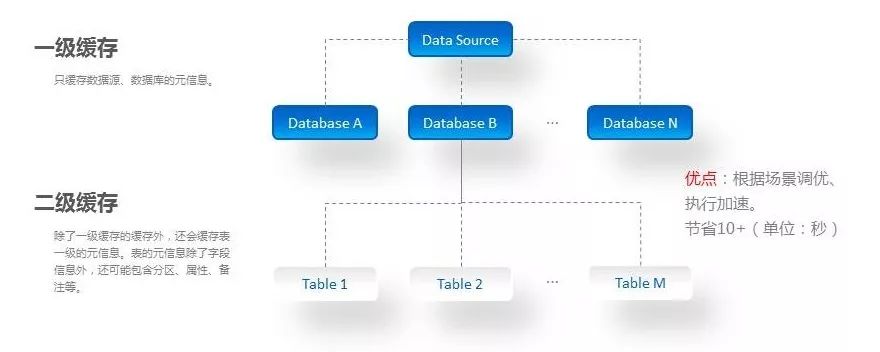
缓存级别控制
XSQL对元数据的缓存有两种级别,既能减少对底层数据源的压力,也提升了XSQL的执行效率。很多场景下(例如:对Hive的使用),元数据的更新变化很少。此时可以通过对元数据的缓存,减少对底层数据源的请求数,对底层数据源更加友好,也保证了XSQL在解析、执行时的效率提升。XSQL提供的两级缓存如下图所示。
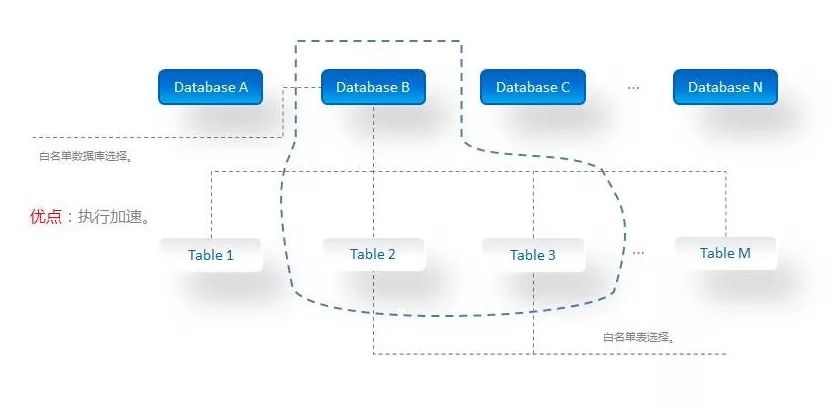
元数据白名单
XSQL可以按照用户需要,设置元数据白名单来避免缓存多余的元信息,进一步提升执行效率。针对很多业务场景,用户往往只需要少数几个数据库、几张表,因此没必要拉取太多的元信息,缓存到内存。对于长期运行的这类任务,将大大减少对底层数据源的压力,提升效率。元数据白名单如下图所示。
多引擎
XSQL团队目前正在多引擎方向进行探索。目前在试验版本中已经提供了针对Flink1.9.0版本和Prestosql 317的支持。但是由于Flink1.9.0在SQL覆盖度、稳定性等方面还有待提升,Prestosql在360内部还未真正大规模使用,因此开源版本暂时不包含此特性。
批流合一
无论是Spark还是Flink,批处理API和流的API有很多差异。XSQL致力于将批处理和流处理通过SQL统一起来,结合多数据源的管理,一条SQL就可以帮助你进行批处理或流处理。用户甚至感觉不到两者的差异。XSQL目前流式处理只支持Kafka一种数据源,未来可能会支持360内部的Qbus或者其他流框架。
除了这些特性外,XSQL还有其他一些特性,限于篇幅,本文不再赘述。
XSQL技术架构
本文从部署、实现以及未来三个角度来展示XSQL的技术架构。
XSQL部署架构
XSQL在部署上借鉴了Hadoop生态的标准方式,并且复用了Spark部署到Yarn的功能。XSQL由于支持多数据源的需要,借鉴了业内竞品的实现,采用了元数据去中心的设计。
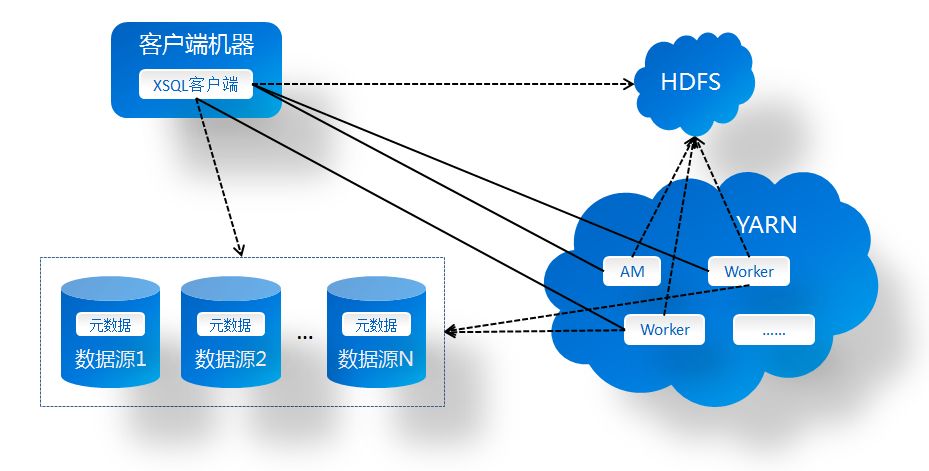
XSQL实现架构
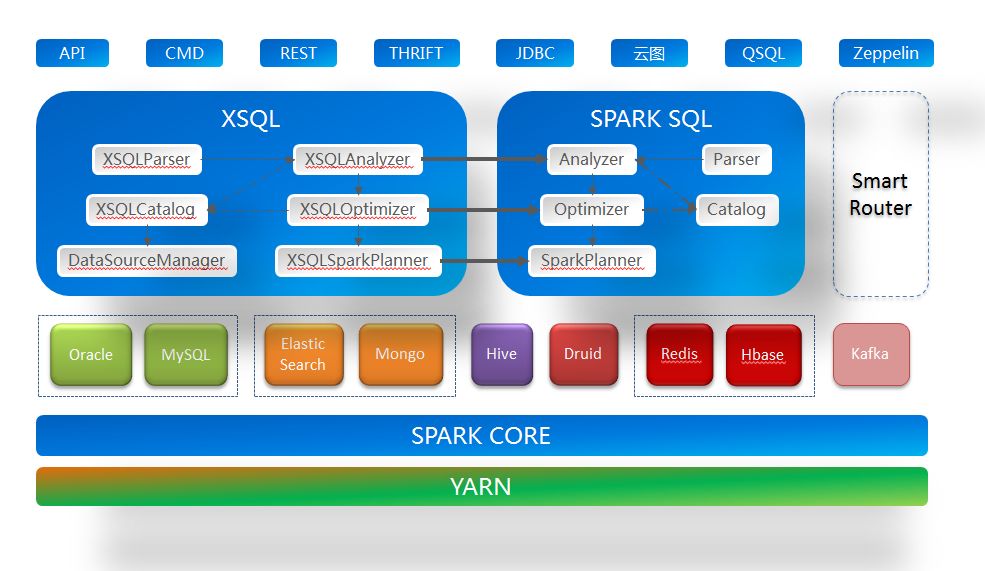
XSQL在实现上借鉴了Spark的SQL框架,对其进行扩展,并最终替换其SQL框架。XSQL提供了多种语言及协议的API。
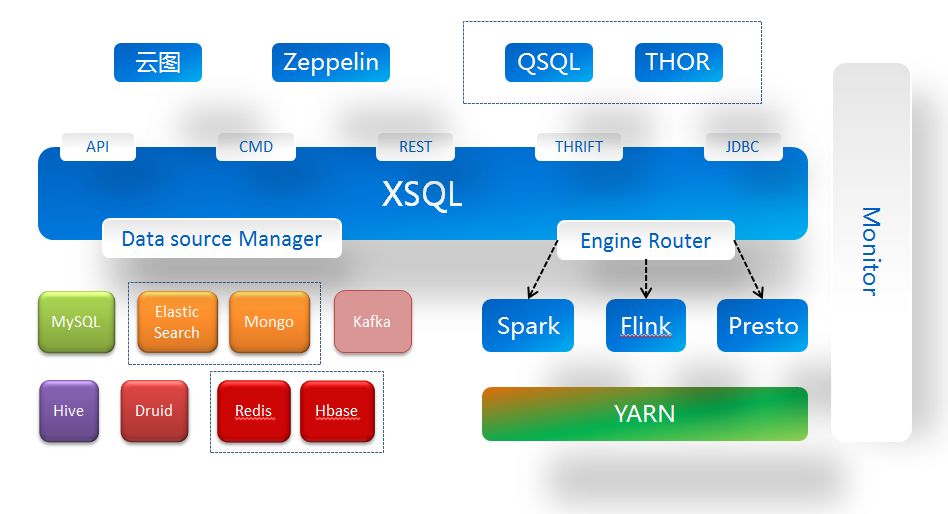
XSQL未来架构
XSQL未来将支持对接不同计算引擎,例如:Flink和Presto。
XSQL适用场景
以上对XSQL的架构、特性等进行了介绍,本节将介绍一些XSQL适用的场景:
小张是新来数据部门的社招生,有五年的数据开发经验。在之前的公司经常进行数据统计类的工作,通过SQL语句对Hive和MySQL中的数据进行检索和加工,使得本人对于SQL语法非常熟悉。由于当前产品有从海量数据中按照关键字进行搜索的需求,因此部门决定使用Elasticsearch。小张在Elasticsearch面前,完全是一个小白。小张在初步查阅了Elasticsearch的介绍后,感觉无所适从。
A部门的业务数据大多都维护在一些MySQL表中,其中有一张customer表用来记录用户的基本信息(例如:用户ID、昵称、年龄、性别、住址等)。同时,一些博客文档的数据却存储在MongoDB的blogs集合中blogs集合的_id字段采用了用户ID。部门产品新增的需求是,在用户的“个人中心”展示用户的博客列表,列表只显示博客标题、发布时间、博客摘要等信息。对于工程师来说,如果能直接将customer表和blogs集合进行关联查询就好了。事情看似非常ease,这也是XSQL的使用场景。
老王是数据部门的老员工,各种大数据工具都使用的游刃有余。老王经常使用Spark的API来编写从各种异构数据源读写数据的作业,由于这种工作重复度很高,老王感觉对这门技术的反复使用非常枯燥,而且时间成本也较高,因此他希望能有一种方式可以改善现在的工作。
B部门是一个对数据库技术非常发烧的部门,目前的各个机器上都安装了Hive、MySQL、Redis、MongoDB等一系列客户端。大家日常开发的任务也都部署在这些机器上,导致这些机器的CPU、内存、磁盘等资源常常出现报警。使用XSQL可以避免Hive之外的各种数据库客户端的安装。
C部门对Druid有广泛使用,通过预计算加快了查询效率。Web端需要展示Druid结果及其配置信息,但是配置信息存储在MySQL中。Web端对查询展示有极高的响应需求,因此C部门利用XSQL将Druid查询结果导入到MySQL中,并通过MySQL表之间的关系进行展示。
编译&部署&运行指南
编译环境依赖
jdk 1.8+
编译步骤
1、源码下载
git clone https://github.com/Qihoo360/XSQL
2、执行编译命令
如果你已经有现成的Spark,可以将XSQL编译为Spark插件:
XSQL/build-plugin.sh
编译成功后源码根目录将出现xsql-0.6.0-plugin-spark-2.4.3.tgz
如果你没有现成的Spark,那么你可以编译完整版的XSQL(内置Spark):
XSQL/build.sh
编译成功后源码根目录将出现xsql-0.6.0-bin-spark-2.4.3.tgz
运行环境依赖
jdk 1.8+
hadoop 2.7.2+
spark 2.4.x
部署步骤
1、解压到客户端
完整版解压:
tar xvf xsql-0.6.0-bin-spark-2.4.3.tgz -C "软件目录"
插件版解压:
tar xvf xsql-0.6.0-plugin-spark-2.4.3.tgz -C "已存在的SPARK_HOME"
2、配置数据源
这里给出一个简单的例子:
spark.xsql.datasources default
spark.xsql.default.database real_database
spark.xsql.datasource.default.type mysql
spark.xsql.datasource.default.url jdbc:mysql://127.0.0.1:2336
spark.xsql.datasource.default.user real_username
spark.xsql.datasource.default.password real_password
spark.xsql.datasource.default.version 5.6.19
运行示例
1、从命令行工具开始
$SPARK_HOME/bin/spark-xsql
spark-xsql> show datasources;
2、从Scala API开始
var spark = SparkSession
.builder()
.enableXSQLSupport()
.getOrCreate()
spark.sql("show datasources")
具体使用操作请参考XSQL帮助文档:https://qihoo360.github.io/XSQL/
结语
XSQL将致力于为整个开源社区提供更好的中间件服务,欢迎广大用户和开发者加入我们。
XSQL开原地址
https://github.com/Qihoo360/XSQL
可点击阅读原文查看,欢迎加star~~
XSQL开发者组(xsql_dev@groups.163.com)
XSQL用户组(xsql_user@groups.163.com)
QQ群
XSQL用户群:838910008

更多开源资讯,请关注“360技术”~
界世的你当不
只做你的肩膀
无


360官方技术公众号
技术干货|一手资讯|精彩活动
空·
XSQL开源地址请点击“阅读原文”
喜欢请加star~~
