




数据库日志中保存了上亿条SQL语句,如何统计出使用频率最高的前一百个字段?
加工脚本中有上万个Teradata数据库的SQL语句,如何把它们批量迁移到语法存在大量差异的Greenplum上?
对于SQL的分析与转换需求绝不止于此,解析出SQL中包含的信息是对其进行分析与转换的前提。构建解析器有很多种方法,可以用正则表达式来抽取SQL语句中的特定信息,但只能匹配相对简单的语句如TRUNCATE,面对写法相对自由的SELECT语句就力不从心;也可以写状态机来解析SQL,不过这是一个造轮子的过程;最快捷的方式莫过于采用词法&语法分析工具创建一个语言解析器。
ANTLR(ANother Tool for Language Recognition)是一款可以用来对文本或二进制数据进行处理的解析程序生成器,在业界被广泛地用来建立各种语言,工具和框架。NetBeans、Hibernate、Hive、Pig、推特搜索、Oracle的SQL developer ide及其迁移工具中都使用了ANTLR。
讲述编译原理的书中一般会介绍UNIX上经典的词法&语法分析器lex和yacc,时至今日,ANTLR在易用性、目标代码可读性和可扩展性上已远远优于这两个传统的工具,只要对正则表达式有所了解就能对其语法规则触类旁通,大幅降低了学习与使用难度。
ANTLR可以接受含有语法描述的语言描述符并且生成能够识别这些语言所产生的句子的程序。作为一个解析程序的一部分,可以给你的语法附上简单的操作符和行为并且告诉ANTLR如何构造抽象语法树(AST)并且如何输出它们。此外,ANTLR支持以Java,C++,C#以及Python生成解析器代码。
下载
ANTLR的最新版本已经发布到v4,与之前如v3版本的语法规则不尽相同,建议直接从官网下载最新版本的运行包(antlr-4.*-complete.jar):
http://www.antlr.org/download
配置
1、 安装J2SE,建议1.7及以上
2、 在.bash_profile中配置CLASSPATH与命令别名
export CLASSPATH=".:$HOME/antlr-4.6-complete.jar:$CLASSPATH"
alias antlr4='java -Xmx500M -cp "$HOME/antlr-4.6-complete.jar:$CLASSPATH" org.antlr.v4.Tool'
alias grun='java org.antlr.v4.gui.TestRig'
下面我们先用一个计算器的例子来学习如何使用ANTLR创建数学表达式解析器并对解析结果进行计算,之后再创建一个相对复杂的SQL解析器,能够将输入的SELECT语句按照嵌套关系解析为树状结构,藉此为后续的SQL分析、转换等操作提供基础。
解析四则运算表达式
想让ANTLR能够解析输入的数学表达式并按照运算符优先级构造出一棵抽象语法树,首先需要告诉ANTLR你要输入的表达式是以何种语法展现的,也就是需要一个语法文件来描述数学表达式的解析规则。在ANTLR v4版本中,一般以语法的名称为文件名,以.g4作为扩展名。我们将这个计算器可接受的语法命名为“Calc”,接下来我们开始创建名为“Calc.g4”的语法文件。
1
定义计算器的语法规则
在ANTLR中,不同运算符的优先级需要通过语法规则的嵌套定义来体现,加减法运算符优先级低于乘除法,乘除法运算符优先级低于括号,因此在定义语法规则时,最低优先级的运算符需要最先定义,这样才能保证高优先级运算符在语法树上优先结合。
ANTLR的语法近似于正则表达式,常见符号与规则如下:
| 符号与规则 | 含义 |
|---|---|
| | | 表示或者的关系 |
| */+ | 出现0次/1次或更多 |
| ? | 出现0或1次 |
| ( ) | 子规则 |
| // * */ | 注释 |
| 小写字母开头 | 语法规则 |
| 大写字母开头 | 词法规则 |
文件首行需要定义语法名称:
接下来定义语法规则
首先定义加减法运算:
其次定义乘除法运算:
最后定义括号运算符与数值:
expr : '(' addExpr ')' # Bracket
| INT # Int
;
INT : '0'..'9' +
;
对于表达式中出现的空格、换行等无意义字符,需要定义一条规则以忽略:
至此,一个能够解析四则运算的语法文件已经定义好了,完整内容如下:
addExpr : multExpr (('+' | '-') multExpr)*
;
multExpr : expr (('*' | '/') expr)*
;
expr : '(' addExpr ')' # Bracket
| INT # Int
;
INT : '0'..'9' +
;
WS : (' ' | ' ' | ' ' | '' )+ {skip();}
;
2
编译与测试语法文件
编译语法文件:
$ javac Calc*.java
测试:
其中:
1、Calc即我们定义的语法名称
2、prog为Calc语法中定义的根表达式
3、-gui参数可以将语法树以图形化方式展现出来,若替换为-tree参数则可以在终端打印文本格式的解析树。
在输入数学表达式后,以Ctrl+D为输入结束符,测试程序即开始解析并展示解析结果。
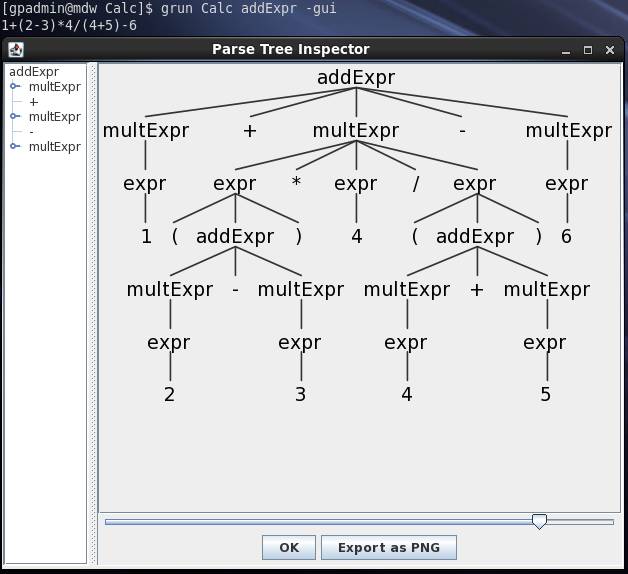
3
选择合适的语法风格
对于数学表达式的解析,还有另一种语法:
stat: expr;
expr:expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| '(' expr ')' # parens
;
INT : [0-9]+ ; match integers
WS : ('' | ' ' | ' ')+ -> skip ;
输入同样的四则运算表达式,可以解析出与之前不同风格的语法树:
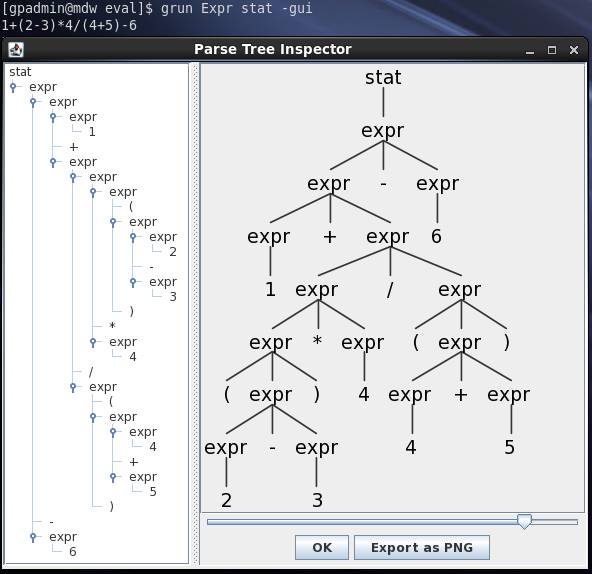
上述两种不同的语法将输入的式子解析成两种风格迥异的抽象语法树,第一种将同级别的运算符放在同一层次,每个节点的子节点数目不定;第二种则严格地将表达式解析成一棵三叉树。
在后续的SQL解析中,第一种类型的抽象语法树的风格便于处理SQL语句的嵌套等内容。后续我们用第一种解析方式来实现对表达式的求解。
访问抽象语法树
1
根据抽象语法树计算表达式值
假定我们输入一个表达式:1+(2+1)*(3+4+5),解析后的树如下:
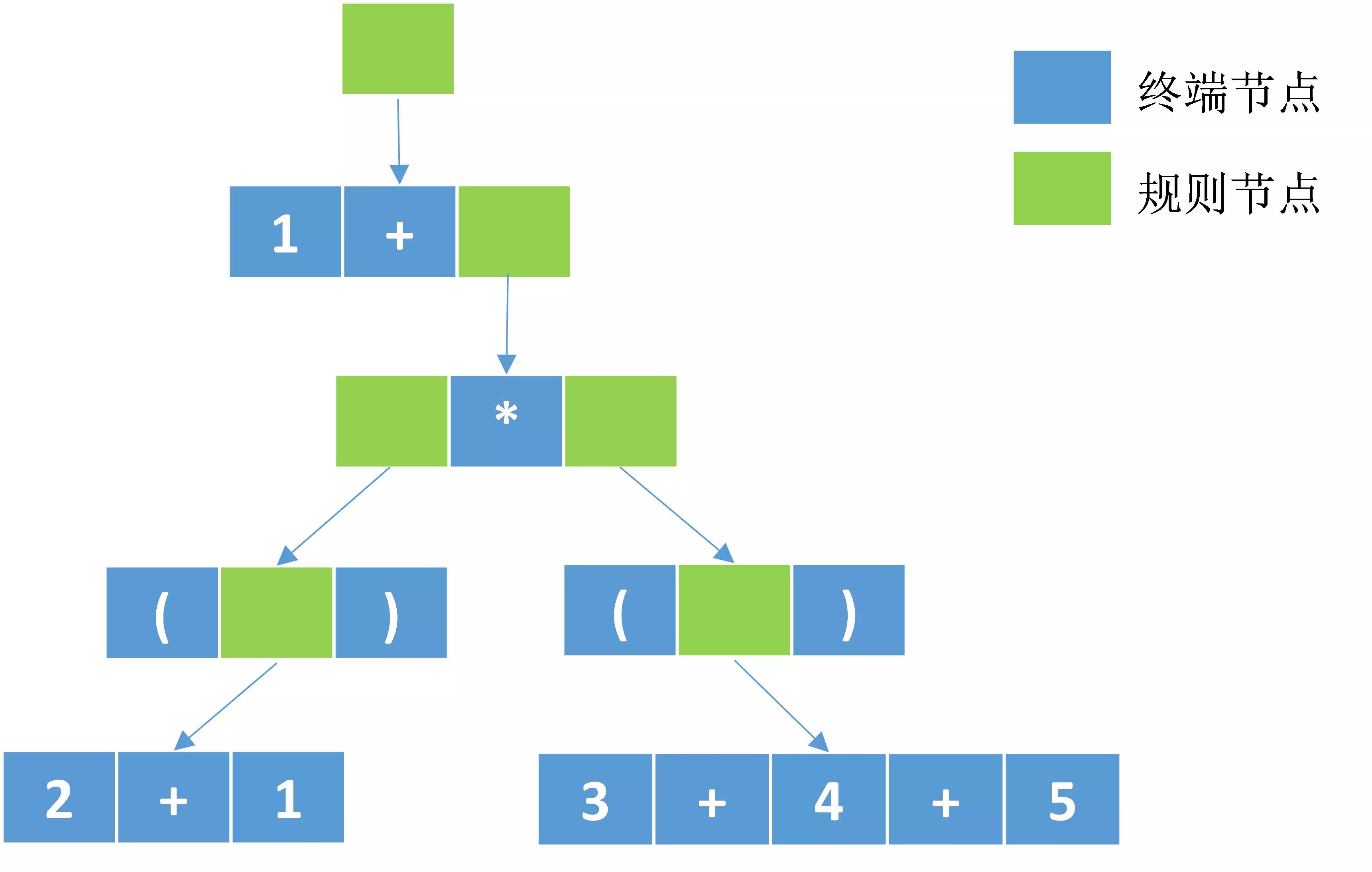
在这棵树中,越需要优先计算的节点越靠近叶子节点,因此我们需要从根节点开始以深度优先遍历的方式访问各个节点以实现对语法树的求值。我们之前在语法文件中定义了四条语法规则,因此ANTLR也为这个语法生成了四种类型的规则节点,需要遍历这四种节点,就必须实现这四种节点各自的访问方法。
创建工程
1、将编译生成的Java文件添加到eclipse的Java工程中
依赖库中添加antlr-4.*-complete.jar
重载访问树节点方法
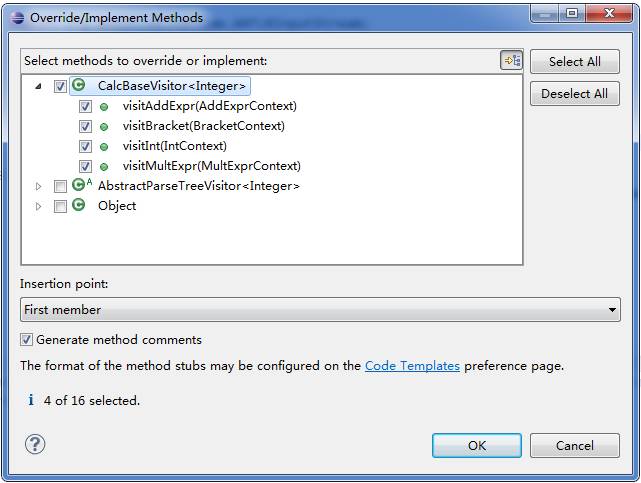
在重载CalcBaseVisitor中各种节点的visit方法时可以看到,ANTRL为我们在语法文件中定义的各种表达式类型均创建了一个继承自ParserRuleContext的类。
如为加法表达式addExpr创建了CalcParser.AddExprContext类,同时创建了相应的节点访问方法visitAddExpr。
@Override
public Integer visitAddExpr(CalcParser.AddExprContext ctx) {
super.visit(ctx);
}
对于表达式expr中带有“#”标记的表达式,为每个标记也创建了相应的节点与访问方法,以更方便地区分匹配到的内容:
语法表达式:
expr : '(' addExpr ')' # Bracket
| INT # Int
;
生成的方法如下:
public Integer visitBracket(CalcParser.BracketContext ctx)
public Integer visitInt(CalcParser.IntContext ctx)
抽象语法树节点的数据结构
一棵解析完成的抽象语法树中,存在两种类型的节点:类型为TerminalNode的叶子节点(终端节点)与CalcParser.AddExprContext等继承自ParserRuleContext的各种规则节点。
ParserRuleContext常用属性与方法:
子节点存储相关
ParserRuleContext中采用名为children的List<ParseTree>类型列表存储子树节点,同时提供了部分常用的子节点列表操作函数,如果后续需要修改语法树的结构,即可直接对该列表进行操作。
深度拷贝
ParserRuleContext提供copyFrom函数用于执行子树的深拷贝。
遍历抽象语法树
对于每个规则节点的visit方法,均需要计算其所在子树的值并返回该值。
/*
* 计算加减法表达式
*/
@Override
public Integer visitAddExpr(CalcParser.AddExprContext ctx) {
Integer leftInteger = visit(ctx.children.get(0));
for (int idx = 2; idx < ctx.children.size();) {
if (ctx.children.get(idx - 1).getText().equals("+")) {
leftInteger = leftInteger + visit(ctx.children.get(idx));
}
elseif (ctx.children.get(idx - 1).getText().equals("-")){
leftInteger = leftInteger - visit(ctx.children.get(idx));
}
else {
System.exit(-1);
}
idx += 2;
}
return leftInteger;
}
/*
* 计算乘除法表达式
*/
@Override
public Integer visitMultExpr(CalcParser.MultExprContext ctx) {
Integer leftInteger = visit(ctx.children.get(0));
for (int idx = 2; idx < ctx.children.size(); ) {
if (ctx.children.get(idx - 1).getText().equals("*")) {
leftInteger = leftInteger * visit(ctx.children.get(idx));
}
elseif(ctx.children.get(idx - 1).getText().equals("/")){
leftInteger = leftInteger visit(ctx.children.get(idx));
}
else {
System.exit(-1);
}
idx += 2;
}
return leftInteger;
}
/*
* 处理括号
*/
@Override
public Integer visitBracket(CalcParser.BracketContext ctx) {
return visit(ctx.addExpr());
}
/*
* 读取整形数值
*/
@Override
public Integer visitInt(CalcParser.IntContext ctx) {
return Integer.parseInt(ctx.getText());
}
public static void main(String[] args) {
// 从标准输入中读取一行,并传入ANTLR输入流
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
ANTLRInputStream input = null;
try {
input = new ANTLRInputStream(reader.readLine());
} catch (IOException e) {
e.printStackTrace();
}
// 进行词法、语法分析
CalcLexer lexer = newCalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
// 根据用户输入的式子生成抽象语法树(AST)
ParseTree tree = parser.addExpr();
// 使用我们定义的Visitor对象遍历抽象语法树,并输出结果
CalcASTVisitor eval = new CalcASTVisitor();
Integer ret = eval.visit(tree);
System.out.println("=" + ret + "\n");
}
运行程序,输入待计算的四则运算式后即可输出结果:
1+(2-4)*4/(6-4)-6
=-9
创建SQL语法规则
在这里我们创建一个能够解析带有子查询的SELECT语句语法:
parse
: select_stmt ';'?
;
// 定义简单的查询语句语法
select_stmt
: K_SELECT result_column ( ',' result_column )*
( K_FROM ( table_or_subquery ( ',' table_or_subquery )* ) )?
;
// 匹配表或子查询,可以将子查询在抽象语法树中作为子树出现
table_or_subquery
: ( database_name '.' )? table_name
| '(' select_stmt ')'
;
database_name
: IDENTIFIER
;
table_name
: IDENTIFIER
;
result_column
: IDENTIFIER
;
// 定义SQL关键字
K_SELECT : S E L E C T;
K_FROM : F R O M;
// 定义匹配任意大小写字母的规则
fragment C : [cC];
fragment E : [eE];
fragment F : [fF];
fragment L : [lL];
fragment M : [mM];
fragment O : [oO];
fragment R : [rR];
fragment S : [sS];
fragment T : [tT];
SPACES
: [ \u000B ] {skip();}
;
IDENTIFIER
: [a-zA-Z_] [a-zA-Z_0-9]*
;
其中“fragment”标记声明该标识不能直接在匹配时使用,必须作为其它语法规则的内容,避免匹配时产生歧义,如匹配“SELECT”时,“K_SELECT”规则与“S”规则都是匹配字母“s”,只有将规则“S”声明为fragment时,才能让输入“SELECT”只能被“K_SELECT”规则所匹配。
测试
$ antlr4 Select.g4
$ javac Select*.g4
$ grun Select parse -gui
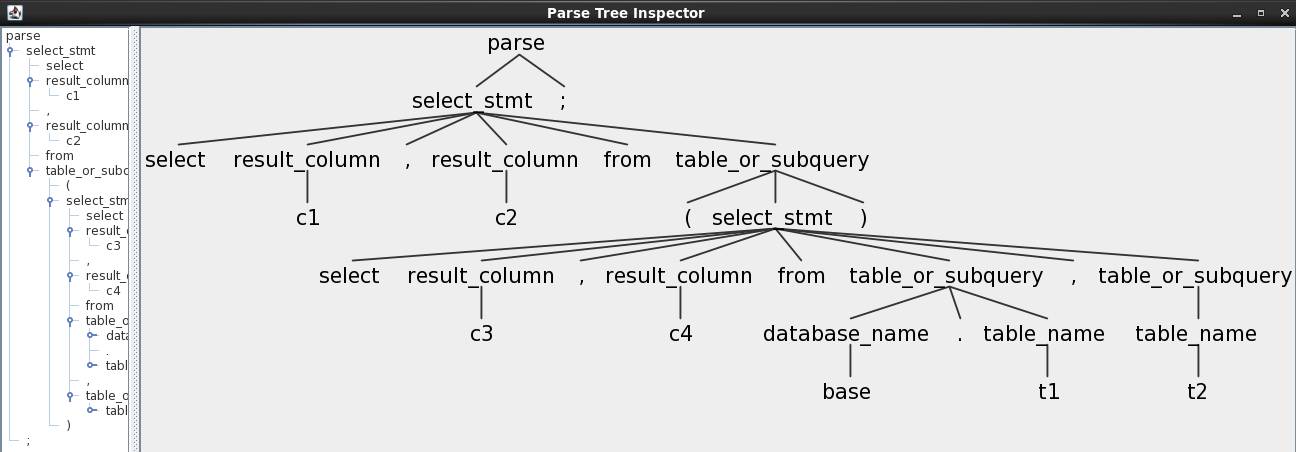
select c1, c2
from (
select c3, c4
from base.t1, t2
)
;
对SQL语句的解析结果如下:
后记
SQL语句的语法规则一般较多且复杂,不同类型数据库的语法也不尽相同,若需要构建一个完整的SQL解析器,其语法规则较为庞大,建议先在https://github.com/antlr/grammars-v4中查找是否已有合适或者相近的SQL语法用以参考,再根据需要解析的SQL类型进行相应的修改。
