




在Linux文件系统中一切皆文件,同样目录也是文件的一种类型。熟悉Linux服务器的同学经常会看到如下内容,这个是某个目录的列表内容。每一行的前面形如drwxr-xr-x的内容为文件的属性,而第一个字符d则表示这个文件是一个特殊的文件,也就是目录(directory)。第一个字符是用于标示文件类型的,对于块设备则是b,字符设备是c等等,每种特殊的文件这个字符都是不同的。
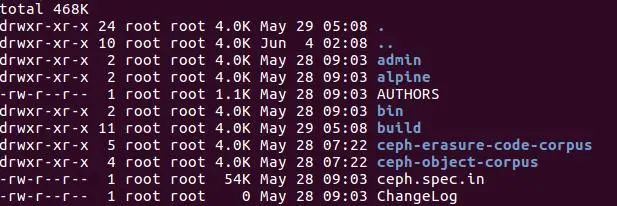 图1 Linux中目录列表
图1 Linux中目录列表
对于有图像界面(GUI)的情况下,目录的呈现形式更加丰富,如图2所示,目录中有子目录和文件。同时有些文件(例如图片和PDF等)还可以呈现其概览。这样在浏览文件的时候很有帮助,可以很方便的找到想要的文件。
 图2 目录呈现形式
图2 目录呈现形式
1什么是目录
废话说了一大箩,下面我们进入正题。到底什么是目录?目录的本质是什么?我们知道在Ext2中文件是被组织成树形结构的,而目录就是其中的中间节点。如图是一个目录结构的基本示意图。
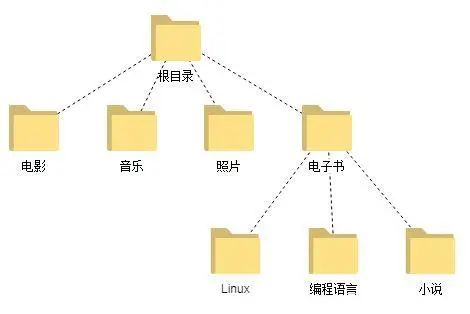
图3 目录结构
直观上感觉目录就是一个容器,其中子目录、文件及文件数据都存储在目录当中。实际上,在目录中并没有存储文件的数据信息,而只是存储了一个类似C语言指针的东东,这个东东就是文件的inode id。而目录中的子目录数据和文件数据仍然是平铺在磁盘上的。这样,在目录中通过这个指针就可以轻易的找到文件的数据,而且目录的数据和文件的数据组织也变得非常简单。
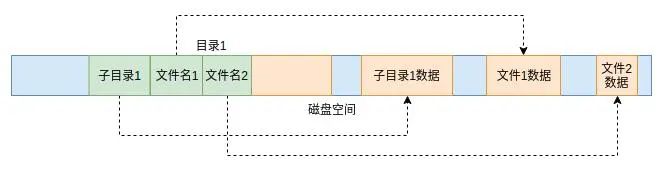 图4 目录数据存储形式
图4 目录数据存储形式
简而言之,目录也是文件,是一种特殊的文件,其中存储的数据是子目录名称和文件名称等一些元数据信息,并不存储具体的数据信息。
2目录的组织形式与数据结构
前文说了目录中存储的子目录名称和文件名称等元数据信息。那么具体包括哪些呢?其实很简单,如下所示,在目录中存储着子项目名称和inode ID的对应关系对,这样根据名称就能找到inode,进而找到具体的内容。
这里插播一个广告,为了方便大家交流学习Linux相关知识,我们创建了一个知识星球社区。为了照顾广大粉丝,大家可以通过下面优惠券加入。

接下来我们转入正题。
以“文件名1”为例,其对应的inode ID是16,那么我们可以根据该ID找到inode,进而找到该文件的数据。
在具体实现层面是如何实现的呢?接下来我们结合Ext2文件系统中关键的数据结构和磁盘实际数据理解一下目录数据到底是怎么存储的。首先我们需要意识到的是目录本质上也是一个文件,只不过其中存储的数据是关于子目录和文件的名称信息。理解到这一层面对理解后续内容来说很重要。在逻辑层面上,文件就是一个线性空间,可以理解为一个大的数组(物理层面可能是分散的,暂时不考虑)。
那么这个大数组中的元素是什么呢?就是图6所示的这个结构体。从该结构体可以看出,每一项内容包括inode的id、该结构体的大小、文件(子目录)名大小和文件名等信息。在检索目录内容的时候,其实就是根据文件名获得inode的id,然后在根据该id从inode表中获得inode(文件)的详细信息。
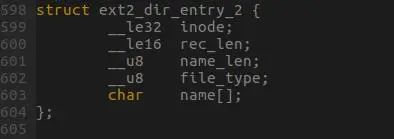
图6 目录子项内容
为了便于理解上述数据结构,我们看一个具体的例子。我们在一个目录中创建文件名为test1到test6等6个文件,然后把目录中一部分数据导出到某个文件中,图7是这个文件的局部数据。可以对照这图7的数据和图6的数据结构理解一下,图中test4文件的inode是0XB005(45061),文件名长度为0X5,结构体长度为0X10(16)。
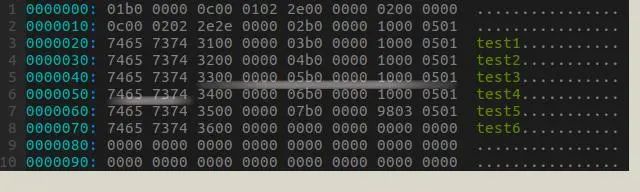 图7 目录数据
图7 目录数据
可以通过debugfs工具获取目录对应inode的信息,包括i_blocks的信息。然后根据磁盘物理地址,可以通过dd命令获取其中的数据。
我们再通过stat命令看一下test4文件的详细信息。可以看到inode信息与上面存储的信息是一致的。

经过上述分析,大家对Ext2文件系统的目录应该有了更加深层次的理解。今天内容先到这里,更多内容敬请关注本号。
