





Dragonfly的核心痛点还是节点数太多时文件分发效率问题,我们也正是因为这个需求非使用Dragonfly不可,其很好的支撑了阿里PB级数据的分发,无论从功能性能还是稳定性方面都能很好的满足我们需求,且可以支持普通的文件分发与docker镜像分发,镜像分发时还能兼容Docker pull接口,所以各位集群节点多时非常值得考虑。
并发在仓库拉去时非常有可能造成网络壅塞,甚至可能直接压垮镜像仓库。
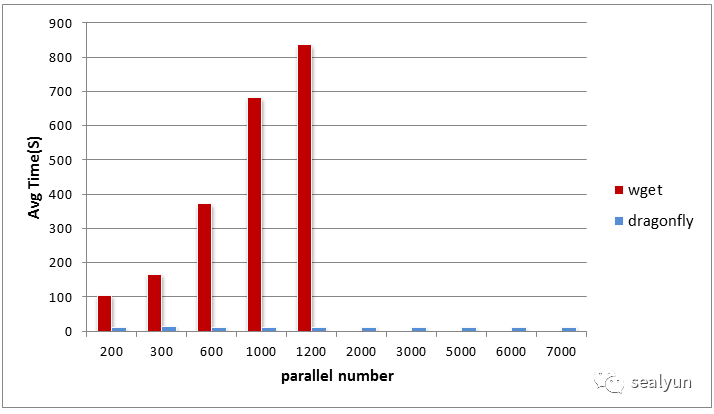
可以看一下实测试性能,横坐标是并发数,纵坐标是时间,当并发1200时wget已经超过八百秒而p2p时不会随并发数量上升导致分发性能下降。
| 核心组件
SuperNode
SuperNode是一个常驻进程,有两个主要职责:
它是P2P网络中的跟踪器和调度器,为每个p2p节点选择适当的下载网络路径。
它也是一个CDN服务器,它从源缓存下载的数据,以避免重复下载相同的文件。
dfget
Dfget是用于下载文件的Dragonfly的客户端。它与wget类似,使用非常简单。
同时,它还扮演着peer的角色,可以在P2P网络中相互传递数据。
dfdaemon
Dfdaemon仅用于拉动图像。它在dockerd pouchd和registry之间建立代理,这样只需要给docker engine配置一个mirror仓库,指定成dfdaemon即可
Dfdaemon在提取图像时过滤掉dockerd pouchd发送的所有请求中的图层提取请求,然后使用dfget下载这些图层。
| 快速使用
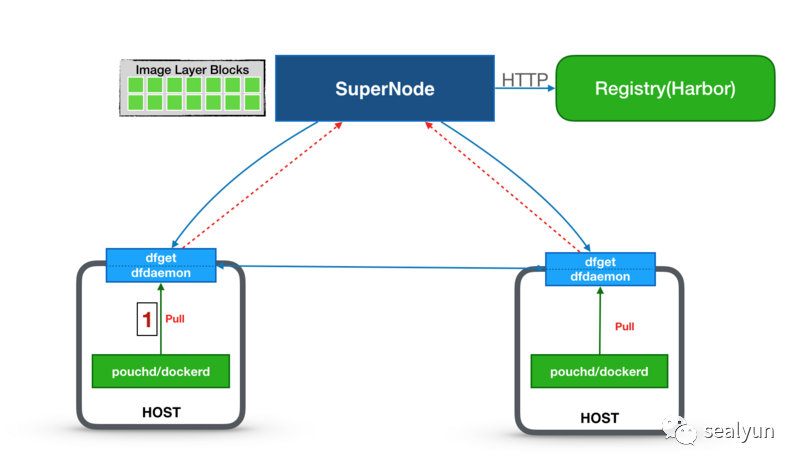
上面是实验环境,我们起一个supernode,再配置一个docker镜像仓库,可以是自己的harbor也可以是dockerhub,起两个节点,节点上会安装dfget与dfdaemon。
启动supernode:
docker run -d -p 8001:8001 -p 8002:8002 \dragonflyoss/supernode:0.3.1 \-Dsupernode.advertiseIp=127.0.0.1 # client可访问的地址复制
启动dfclient 两个node同理,不再赘述
docker run -d --name dfclient01 -p 65001:65001 \dragonflyoss/dfclient:0.3.1 \--registry https://index.docker.io复制
配置docker engine:
vi etc/docker/daemon.json"registry-mirrors": ["http://127.0.0.1:65001"]systemctl restart docker复制
测试,node上pull一个镜像:
docker pull nginx:latest复制
随便哪个节点上查看日志是否成功:
docker exec dfclient01 grep 'downloading piece' root/.small-dragonfly/logs/dfclient.log2019-03-29 15:49:53.913 INFO sign:96027-1553845785.119 : downloading piece:{"taskID":"00a0503ea12457638ebbef5d0bfae51f9e8e0a0a349312c211f26f53beb93cdc","superNode":"127.0.0.1","dstCid":"127.0.0.1-95953-1553845720.488","range":"67108864-71303167","result":503,"status":701,"pieceSize":4194304,"pieceNum":16}2019-03-29 15:49:53.913 INFO sign:96027-1553845785.119 : downloading piece:{"taskID":"00a0503ea12457638ebbef5d0bfae51f9e8e0a0a349312c211f26f53beb93cdc","superNode":"127.0.0.1","dstCid":"127.0.0.1-95953-1553845720.488","range":"67108864-71303167","result":503,"status":701,"pieceSize":4194304,"pieceNum":16}复制
可通过如下命令来下载:
dfget -u "http://www.taobao.com" -o /tmp/test.html \--node nodeIp1,nodeIp2 # supernode节点,可以配置多个复制
| 分发原理
普通文件分发原理:
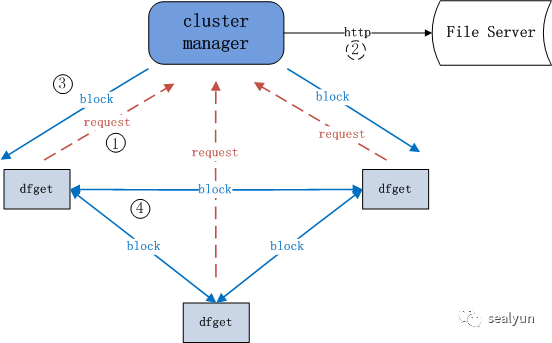
首先在需要下载的节点dfget
请求到supernode节点
supernode通过http在文件服务器获取到文件
返回给node节点
node节点之前就可以进行p2p传输
镜像文件分发原理:
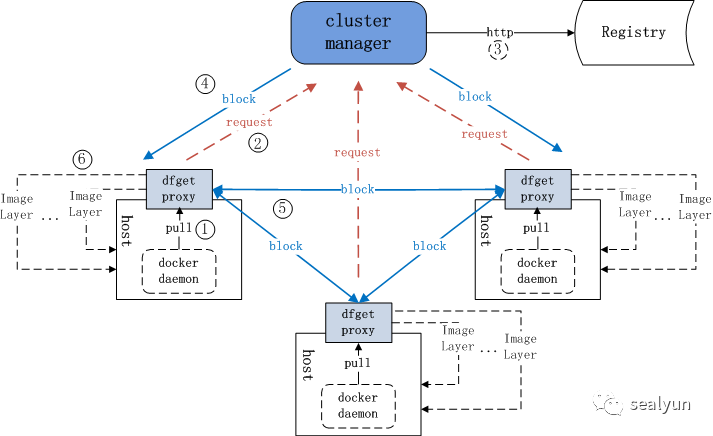
node 发起docker pull请求
请求发给supernode
supernode向仓库拉取镜像
返回镜像给node
节点之间可以相互传输镜像
写镜像到本地文件系统
文件如何分块传输:
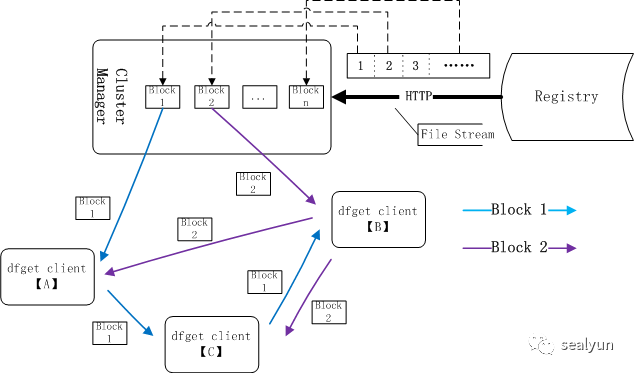
蜻蜓会把一个文件分成很多块,我们以B节点来看,块2从supernode获取,块1从C节点获取然后拼接成一个文件,所以效率非常高。
| 结束语
蜻蜓项目负责人孙宏亮也是docker全球贡献排名前15,笔者也是和他学习了不少东西,这里也推荐他的两本书给大家:
通过docker源码分析可以学习到非常多的原理性东西,比如docker的进程模型是怎样的,镜像是怎么分层的,网络是怎么挂载到网桥上的等等干货,是进阶的好资料

