




select to_char(sample_time, 'yyyymmdd hh24:mi:ss'), count(*)
from dba_hist_active_sess_history
where dbid = 87xxxx65
and snap_id between 31633 and 31634
and to_char(sample_time, 'yyyymmddhh24mi') between '201404211323' and
'201404211328'
and instance_number = 1
-- and instance_number = 2
order by 1;复制
时间 | 活动会话个数 |
0421 13:23:07 | 1 |
0421 13:23:17 | 2 |
0421 13:23:27 | 2 |
0421 13:23:37 | 3 |
0421 13:23:47 | 12 |
0421 13:23:57 | 29 |
0421 13:24:07 | 42 |
0421 13:24:17 | 47 |
0421 13:24:27 | 61 |
0421 13:24:37 | 70 |
0421 13:24:47 | 94 |
0421 13:24:57 | 170 |
0421 13:25:08 | 223 |
0421 13:25:18 | 257 |
0421 13:25:28 | 374 |
0421 13:25:38 | 405 |
0421 13:25:48 | 424 |
0421 13:25:58 | 430 |
0421 13:26:08 | 443 |
0421 13:26:19 | 457 |
0421 13:26:29 | 466 |
0421 13:26:39 | 452 |
0421 13:26:49 | 418 |
0421 13:26:59 | 368 |
0421 13:27:09 | 371 |
0421 13:27:20 | 323 |
0421 13:27:30 | 267 |
0421 13:27:40 | 200 |
0421 13:27:50 | 96 |
0421 13:28:00 | 15 |
0421 13:28:10 | 15 |
0421 13:28:20 | 6 |
0421 13:28:30 | 5 |
0421 13:28:40 | 5 |
0421 13:28:53 | 27 |
时间 | 活动会话个数 |
0421 13:23:07 | 2 |
0421 13:23:18 | 1 |
0421 13:23:28 | 3 |
0421 13:23:48 | 13 |
0421 13:24:13 | 27 |
0421 13:24:23 | 32 |
0421 13:24:34 | 43 |
0421 13:24:44 | 53 |
0421 13:24:55 | 96 |
0421 13:25:05 | 157 |
0421 13:25:16 | 195 |
0421 13:26:48 | 364 |
0421 13:26:58 | 380 |
0421 13:27:08 | 350 |
0421 13:27:19 | 310 |
0421 13:27:29 | 295 |
0421 13:27:39 | 168 |
0421 13:27:49 | 88 |
0421 13:27:59 | 50 |
0421 13:28:09 | 34 |
0421 13:28:19 | 31 |
0421 13:28:29 | 18 |
0421 13:28:39 | 9 |
0421 13:28:49 | 35 |
0421 13:28:59 | 60 |
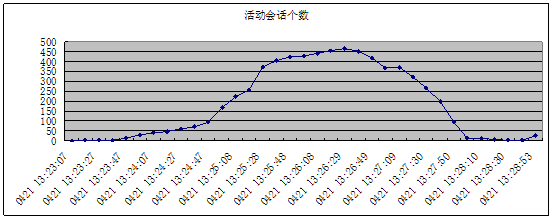
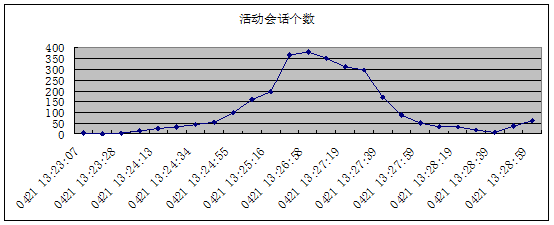

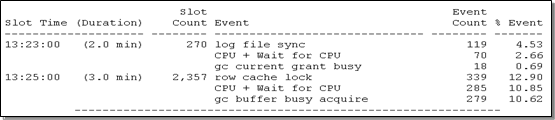
13点23分到25分之间,出现的等待事件主要是”log file sync”和”CPU + wait for CPU”
log file sync 表示当前台进程commit时,必须等待数据库后台lgwr进程将log buffer中的redo刷到磁盘的在线重做日志文件当中,如果commit太频繁、lgwr进程无法获得CPU时间片或者磁盘写入的比较慢,都可能出现等待。
“CPU + wait for CPU” 表示正在消耗CPU或等待获得CPU时间片
时间 | 会话号 | 等待事件 | P1 | P2 |
20140421 13:23:07 | 1_914_55793 | 675562835 | 1 | |
20140421 13:23:17 | 1_429_52181 | db file scattered read | 29 | 2342744 |
20140421 13:23:17 | 1_129_27287 | db file sequential read | 8 | 2214875 |
20140421 13:23:27 | 1_429_52181 | db file scattered read | 38 | 777430 |
20140421 13:23:27 | 1_2169_26989 | 675562835 | 1 | |
20140421 13:23:37 | 1_429_52181 | db file scattered read | 40 | 189572 |
20140421 13:23:37 | 1_1298_47949 | 675562835 | 1 | |
20140421 13:23:37 | 1_2691_49559 | 675562835 | 1 | |
20140421 13:23:47 | 1_2327_54263 | gc buffer busy acquire | 12 | 825179 |
20140421 13:23:47 | 1_136_43439 | gc cr block congested | 26 | 2209472 |
20140421 13:23:47 | 1_1650_27877 | gc cr block congested | 41 | 2244405 |
20140421 13:23:47 | 1_21_44843 | gc cr block congested | 12 | 825179 |
20140421 13:23:47 | 1_429_52181 | gc cr block congested | 12 | 1642095 |
20140421 13:23:47 | 1_161_19363 | gc cr grant congested | 15 | 1740715 |
20140421 13:23:47 | 1_1572_4767 | gc current block congested | 17 | 1205179 |
20140421 13:23:47 | 1_167_13503 | gc current block congested | 14 | 473335 |
20140421 13:23:47 | 1_2054_40013 | gc current block congested | 39 | 2221558 |
20140421 13:23:47 | 1_266_62389 | gc current block congested | 40 | 1626499 |
20140421 13:23:47 | 1_380_1 | library cache lock | 5.04E+17 | 5.04E+17 |
20140421 13:23:47 | 1_1298_47949 | 675562835 | 1 | |
20140421 13:23:57 | 1_2773_1 | enq: CF – contention | 1128660997 | 0 |
20140421 13:23:57 | 1_1047_27169 | gc buffer busy acquire | 39 | 2221558 |
20140421 13:23:57 | 1_1521_11677 | gc buffer busy acquire | 26 | 2209472 |
20140421 13:23:57 | 1_2327_54263 | gc buffer busy acquire | 12 | 825179 |
20140421 13:23:57 | 1_2421_17851 | gc buffer busy acquire | 26 | 2209472 |
20140421 13:23:57 | 1_2691_49559 | gc buffer busy acquire | 26 | 2209472 |
20140421 13:23:57 | 1_666_41747 | gc buffer busy acquire | 26 | 2209472 |
20140421 13:23:57 | 1_685_6751 | gc buffer busy acquire | 41 | 2244405 |
20140421 13:23:57 | 1_1158_13581 | gc cr block congested | 16 | 165697 |
20140421 13:23:57 | 1_136_43439 | gc cr block congested | 26 | 2209472 |
20140421 13:23:57 | 1_1431_45963 | gc cr block congested | 26 | 907213 |
20140421 13:23:57 | 1_1650_27877 | gc cr block congested | 41 | 2244405 |
20140421 13:23:57 | 1_1800_42233 | gc cr block congested | 41 | 335282 |
20140421 13:23:57 | 1_21_44843 | gc cr block congested | 12 | 825179 |
20140421 13:23:57 | 1_2545_38111 | gc cr block congested | 41 | 2241403 |
20140421 13:23:57 | 1_429_52181 | gc cr block congested | 12 | 1642095 |
20140421 13:23:57 | 1_519_11753 | gc cr block congested | 35 | 2542667 |
20140421 13:23:57 | 1_522_42787 | gc cr block congested | 17 | 1228281 |
20140421 13:23:57 | 1_161_19363 | gc cr grant congested | 15 | 1740715 |
20140421 13:23:57 | 1_1024_33599 | gc current block congested | 17 | 1894578 |
20140421 13:23:57 | 1_1572_4767 | gc current block congested | 17 | 1205179 |
20140421 13:23:57 | 1_167_13503 | gc current block congested | 14 | 473335 |
20140421 13:23:57 | 1_2054_40013 | gc current block congested | 39 | 2221558 |
20140421 13:23:57 | 1_266_62389 | gc current block congested | 40 | 1626499 |
20140421 13:23:57 | 1_384_34603 | gc current block congested | 21 | 2321101 |
20140421 13:23:57 | 1_398_48405 | gc current block congested | 17 | 2481977 |
20140421 13:23:57 | 1_817_62135 | gc current block congested | 35 | 2429993 |
20140421 13:23:57 | 1_2536_48381 | library cache lock | 5.04E+17 | 5.04E+17 |
20140421 13:23:57 | 1_2660_11985 | log file sync | 8467 | 2215449001 |
时间 | 会话号 | 等待事件 | P1 | P2 |
20140421 13:23:07 | 2_2705_39081 | 2 | 43 | |
20140421 13:23:07 | 2_2451_44245 | 10 | 2073606 | |
20140421 13:23:18 | 2_1312_12281 | 16 | 1273651 | |
20140421 13:23:28 | 2_7_33057 | db file sequential read | 18 | 1187652 |
20140421 13:23:28 | 2_1168_44727 | db file sequential read | 21 | 52088 |
20140421 13:23:28 | 2_1782_62969 | 28 | 2011437 | |
注意:这里缺少了23分38秒一次采样 | ||||
20140421 13:23:48 | 2_1666_49667 | db file scattered read | 38 | 2002368 |
20140421 13:23:48 | 2_380_1 | enq: CO – master slave det | 1129250822 | 0 |
20140421 13:23:48 | 2_400_41067 | gc current block 2-way | 14 | 1711942 |
20140421 13:23:48 | 2_2404_1021 | gc current grant busy | 13 | 1102632 |
20140421 13:23:48 | 2_915_6217 | library cache pin | 5.04E+17 | 5.04E+17 |
20140421 13:23:48 | 2_2773_1 | 100 | 0 | |
20140421 13:23:48 | 2_2396_29 | 5.04E+17 | 5.04E+17 | |
20140421 13:23:48 | 2_1639_1 | 3 | 0 | |
20140421 13:23:48 | 2_1513_1 | 80 | 0 | |
20140421 13:23:48 | 2_1387_1 | 0 | 3 | |
20140421 13:23:48 | 2_1262_1 | 0 | 0 | |
20140421 13:23:48 | 2_1261_1 | 1 | 1 | |
20140421 13:23:48 | 2_1036_45191 | 500 | 0 | |
注意:这里缺少了23分58秒和24分08秒的两次采样,下面一行却显示是24分13秒,而不是24分08秒,说明数据库或者操作系统出现了性能问题导致采样丢失、延迟 | ||||
20140421 13:24:13 | 2_1666_49667 | gc cr multi block request | 40 | 1460683 |
20140421 13:24:13 | 2_400_41067 | gc current block 2-way | 14 | 1711942 |
…… |
时间 | 活动会话个数 |
0421 13:23:07 | 2 |
0421 13:23:18 | 1 |
0421 13:23:28 | 3 |
正常10秒有一次采样,这么有10秒左右挂起了,直接跳到23分48秒 | |
0421 13:23:48 | 13 |
正常10秒有一次采样,这么有20秒左右挂起了,直接跳到24分13秒 | |
0421 13:24:13 | 27 |
0421 13:24:23 | 32 |
0421 13:24:34 | 43 |
0421 13:24:44 | 53 |
0421 13:24:55 | 96 |
0421 13:25:05 | 157 |
0421 13:25:16 | 195 |
正常10秒有一次采样,这么有1分30秒左右挂起了 | |
0421 13:26:48 | 364 |
0421 13:26:58 | 380 |
0421 13:27:08 | 350 |
0421 13:27:19 | 310 |
0421 13:27:29 | 295 |
0421 13:27:39 | 168 |
0421 13:27:49 | 88 |
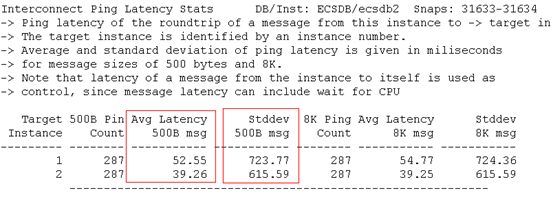


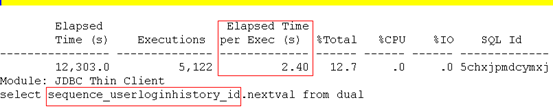
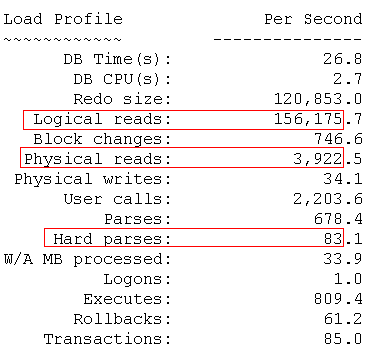
每秒硬解析83次,太高,系统有多处应该使用绑定变量但未使用的地方,过高的硬解析不利于系统的稳定性、扩展性,存在较大隐患。后续我们将把这些应该使用绑定变量但未使用的SQL语句查找出来,以便开发进行相应修改。
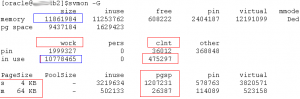
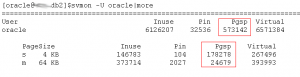
每秒逻辑读15万,过大,有很大的优化空间
每秒物理读3922个BLOCK,IO过大,有很大的优化空间


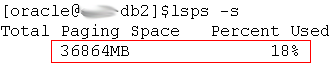
针对连接数突然升高导致数据库不可用的历史故障,我们建议调整内存大小到70G,同时重启操作系统,把换页空间中的内存数据释放掉。
RAC标准配置必须要求安装ORACLE发布的Oswatcher工具,以便可以获取到CPU、内存等性能数据,安装介质可以从metalink上下载,搜索关键字为oswatcher即可,按照10秒采样,保留3天
系统存在很大的性能提升空间,存在一些隐患,需要针对性的、深入的现场分析。
原创文章,版权归本文作者所有,如需转载请注明出处
喜欢本文请长按下方的二维码订阅Oracle一体机用户组

