




我们如何对抗 CAP 理论?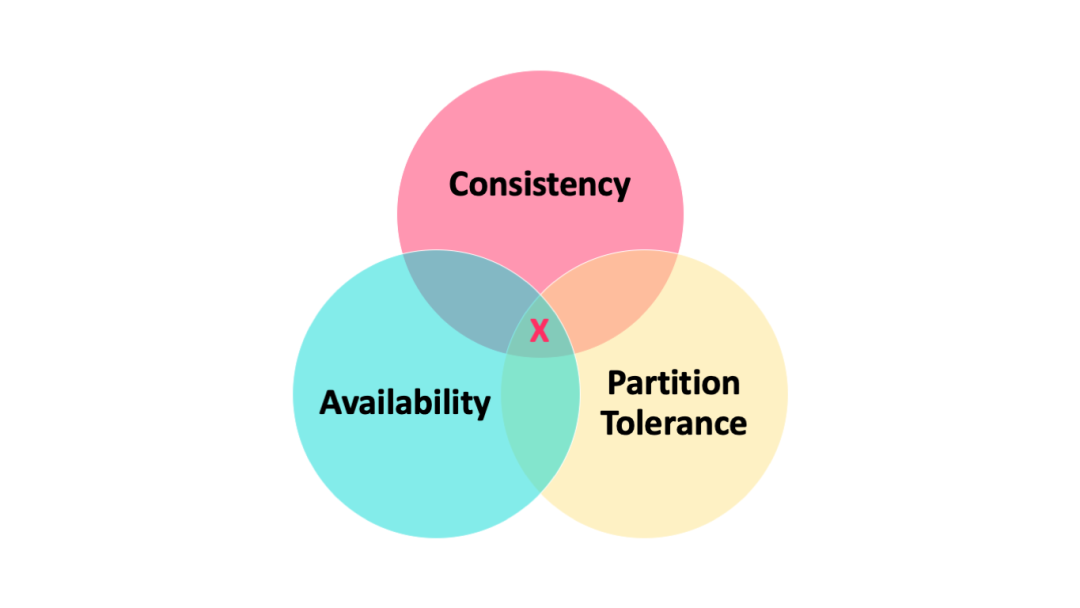
一致性: 每个节点读取的是最新结果或者是报错。 可用性: 每个请求都会收到一个(非错误)响应,但不保证它包含最新的写入。 分区容错: 尽管节点之间的网络丢弃(或延迟了)任意数量的消息,系统仍继续运行。
简史
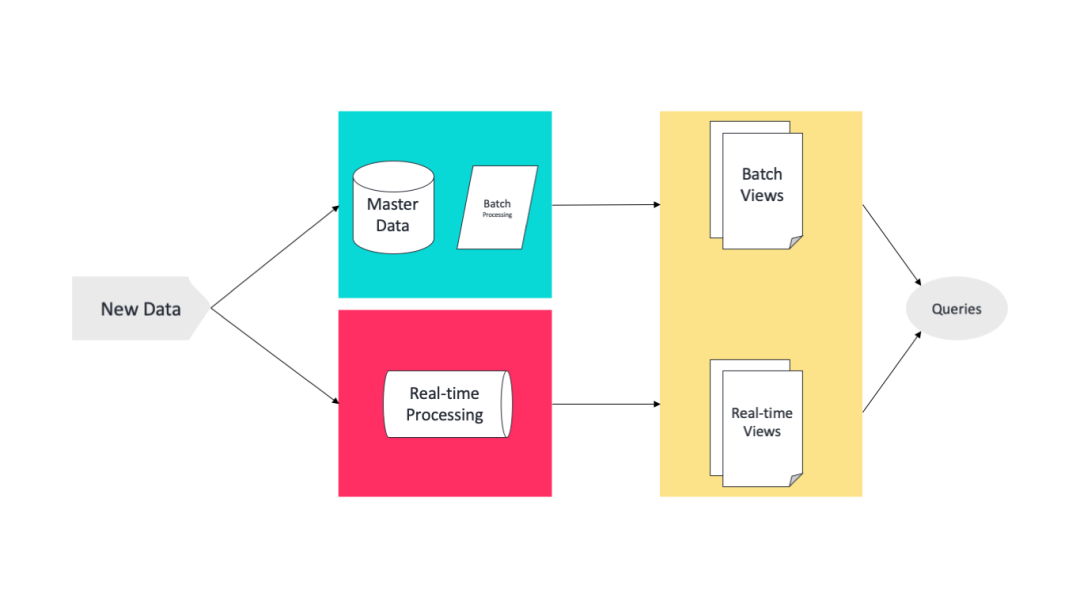
工作原理
它结合了对同一数据的实时(real-time)和批量(batches)处理。
批处理层(Batch layer)
数据是原始的 数据是不可变的 数据永远是真实的
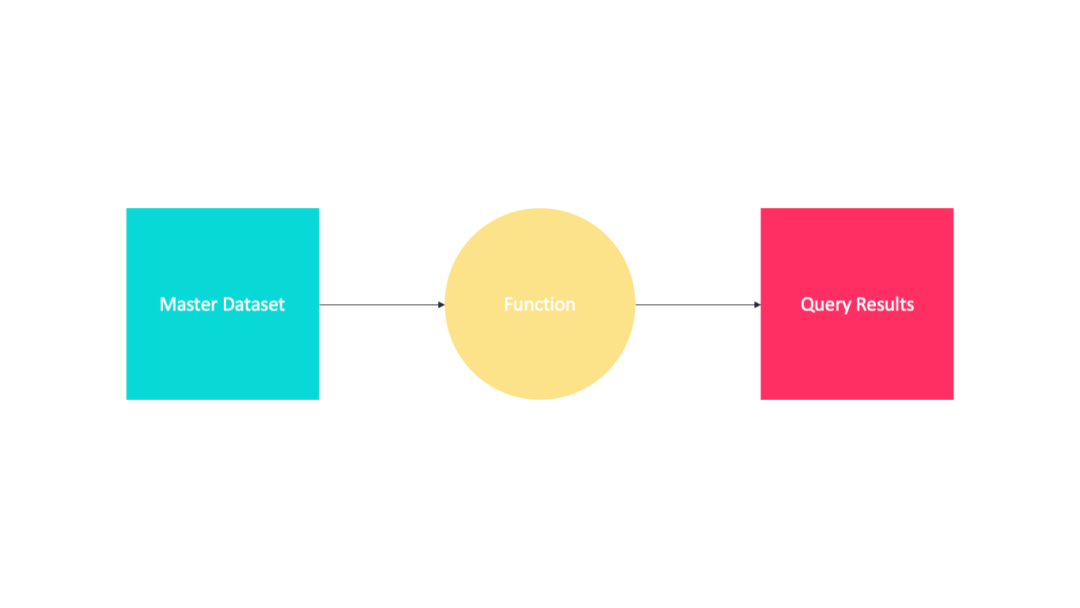
重新计算法: 抛弃旧的批处理视图,重新计算整个主数据集的函数。 增量算法: 当新数据到达时,直接更新视图。
加速层(Speed layer)
随机读: 支持快速随机读取以快速响应查询。 随机写: 为了支持增量算法,必须尽可能的以低延迟修改实时视图。 可伸缩性: 实时视图应随它们存储的数据量和应用程序所需的读/写速率进行缩放。 容错性: 当机器故障,实时视图应还能继续正常运行。
服务层(Serving layer)
Lambda 架构几乎可以满足所有属性
容错: Lambda 架构为大数据系统提供了更友好的容错能力,一旦发生错误,我们可以修复算法或从头开始重新计算视图。 即席查询: 批处理层允许针对任何数据进行临时查询。 可伸缩性: 所有的批处理层、加速层和服务层都很容易扩展。 因为它们都是完全分布式的系统,我们可以通过增加新机器来轻松地扩大规模。 扩展: 添加视图是容易的,只是给主数据集添加几个新的函数。
一些问题
层之间的代码如何同步
我们可以移除速度层(speed layer)吗?
我们可以丢弃批处理层(batch layer)并处理速度层(speed layer)中的所有内容吗?
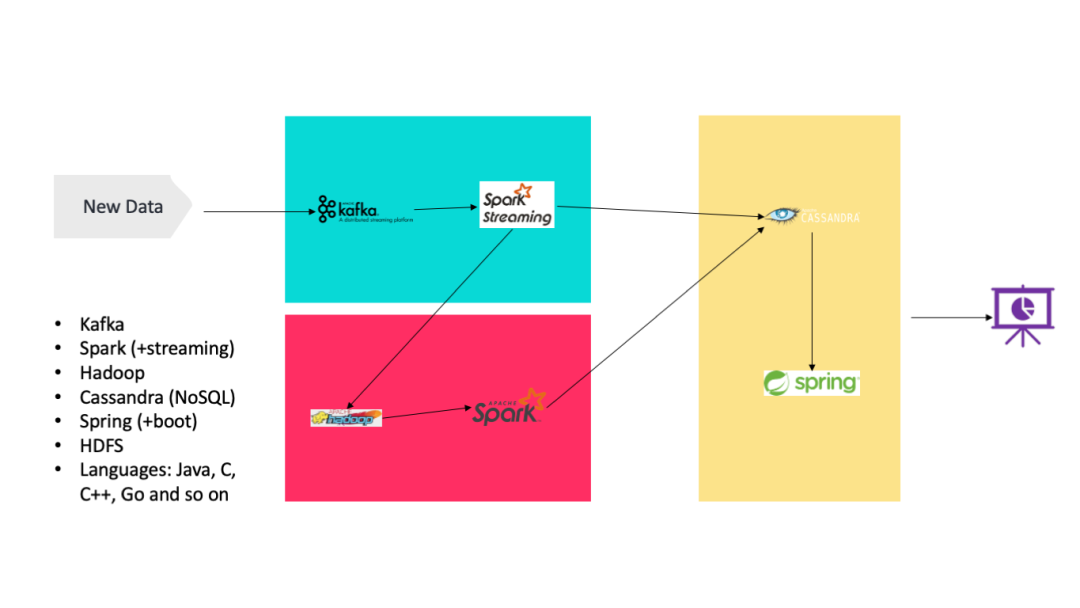
如何实现 Lambda 架构?
使用 Lambda 架构的公司
Yahoo
Netflix
总结
参考文献
[1] nathanmarz.com/blog/how-to… [2] www.slideshare.net/Hadoop_Summ… [3] netflixtechblog.com/announcing-…
来源:https://juejin.cn/post/6887845604886741006
文章转载自大数据学习与分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
