




Chapter1. Introduction
•Kubernetes Native Application
何为Kubernetes-native的Application,感知是跑在Kubernetes上,并依靠Kubernetes提供的API(指的是与API Server直接交互来查询资源的状态或者更新这些资源的状态)来进行编程的Application,被称之为Kubernetes Native Application。
•Kubernetest 扩展系统 kubernetest提供了很强大的扩展系统,通常来说有多种方式来实现扩展,下面是一些常见的Kubernetes的扩展点,更多细节可以看extending-kubernetes-101[1]:
•cloud-controller-manager
对接各个云厂商提供的能力,比如Load Balancer、VM等•Binary kubectl plug-ins
通过二进制扩展kubelet子命令•Binary kubelet plug-ins
通过二进制扩展网络、存储、容器运行时等•Access extensions in the API server
比如dynamic admission control with webhooks•Custom resources
和 custom controllers
•Custom API servers
•Scheduler externsions,通过webhook来实现自己的调度器•Authentication with webhooks
•Controll LoopKubernetest的controller的实现本质上是一个control loop,通过API server来watch某种资源的状态,然后根据当前状态向着终态走。
Kubernetes并不会根据当前的状态和预期的状态来计算达到预期状态所需要的命令序列,从而来实现所谓的声明式系统,相反Kubernetes仅仅会根据当前的状态计算出下一个命令,如果没有可用的命令,则Kubernetes就达到稳态了
典型的Control loop的流程如下:
1. 读取资源的状态(更可取的方式是通过事件驱动的方式来读取)2. 改变集群中对象的状态,比如启动一个POD、创建一个网络端点、查询一个cloud API等3. 通过API server来更新Setp1中的资源状态(Optimistic Concurrency)mak4. 循环重复,返回到Setp1
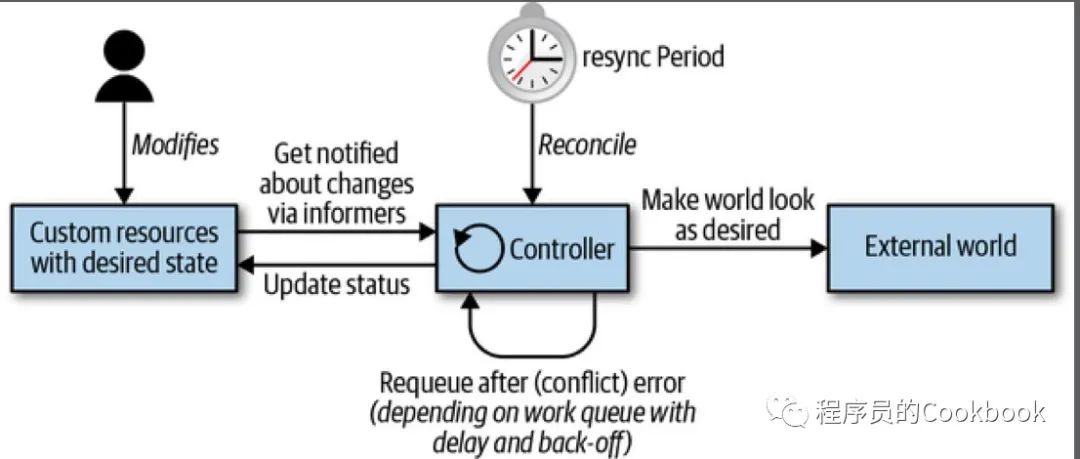
Controller 核心数据结构:
informers 提供一种扩展、可持续的方式来查看资源的状态,并实现了resync机制(强制执行定期对帐,通常用于确保群集状态和缓存在内存中的假定状态不会漂移)
Work queues 用于将状态变化的事件进行排队处理,便于去实现重试(发生错误的时候,重新投入到队列中)
•Events
Kubernetes中大量使用事件和一些松耦合的组件。其他的一些分布式系统主要是RPC来触发行为,但是Kubernetes没有这么做。Kubernetes控制器通过监控Kubernetes对象在API server中的改变(添加、删除、更新)等。当这些事件发生,Kubernetes控制器执行对应的业务逻辑。
下面是一个POD创建的过程:
1.deployment控制器(属于controller-manager组件)通过deployment informer发现了一个deployment创建的事件,于是开始创建一个replica set2.replica set控制器(属于controller-manager组件)通过replica set informer发现一个新的replica set创建,于是开始创建一个POD对象3.scheduler(属于kube-scheduler组件),他也是一个控制器,通过pod informer发现了一个POD对象的创建,并且spec.nodeName是空,于是就将其放到了scheduling的队列中4.kubelet(也是一个控制器)同样也发现了一个新的POD对象的创建,但是spec.nodeName是空,和自己的node name并不一致,因此就忽略了这个事件,继续sleep5.scheduler从队列中获取一个POD,并更新spec.nodeName字段,填入要调度到的nodeName,写入到API server6.kubelect组件因为POD状态发生了改变被唤醒,通过比较spec.nodeName和自己的nodeName,如果匹配到了,就根据POD对象创建对应的容器。并根据容器引擎的执行情况来更新POD状态7.replica set控制器发现POD变化了额,但是什么也没做8.最终POD terminates,kubelet会收到通知,并获取POD对象,更新其状态为terminated。9.replica set控制器发现POD的状态为terminated,于是删除POD对象,重新创建一个新的10.到此结束
通过上面POD创建的过程可以看出,整个过程中有很多独立的Controller,每一个Controller就是一个control loop。他们之间通过informer接收到事件来触发对应的逻辑。这些事件是API Server发送给informer的。informer内部通过watche的方式得到通知。
这里说的Event事件和Kubernetes中的Event对象是两回事,Event对象主要是给用户提供一种logging机制,用户编写的Controller可以创建Event对象来记录一些内部事件 比如kubelet会通过Event对象暴露内部的生命周期事件。这些Event对象可以像其他的kubernetes对象(Pod、Deployment等)一样进行查询。这些事件对象默认只存放 1个小时。1个小时候后便会从etcd中删除。
•Level triger vs Edge triger
Kubernetes中大量依赖事件来解耦各个组件,事件的高效通知对于Kubernetes来说至关重要,典型的二种实现事件通知的机制如下:
* Edge-driven triggersAt the point in time the state change occurs, a handler is triggered—for example, from no pod to pod running.* Level-driven triggersThe state is checked at regular intervals and if certain conditions are met (for example, pod running), then a handler is triggered.
水平触发不具备可扩展性,本质上是polling、polling的间隔会影响controller的实时性,边缘触发更加高效,但是如果某个Controller存在bug就会导致事件丢失,这对于 边缘触发来说是无法接受的,而水平触发却不会存在这个问题,因为总是能够通过polling的方式获取到最终的状态。两者结合一下,事件通过边缘触发来通知,每次收到事件后通过pooling的方式 获取到资源的最终状态,那么即使中间丢失了一个事件也无所谓,比如replica set控制器中,预期要创建3个POD,因此每次POD创建都会产生一个事件,replica set通过事件就可以知道当前状态 和预期的状态还差多少,然后继续创建POD,如果因为网络问题导致中间丢失了一个事件,那么这就会导致创建的POD和预期的不符,这个时候如果结合水平触发,在下一次事件到来的时候主动查一下 当前的状态,这样就可以避免了中间事件丢失导致状态不对的问题,同时也借助了边缘触发达到了高效的事件通知。但是这样仍然存在问题。如果正好是最后一个事件丢失了呢? 这样就没有机会去查询当前 状态了。如果能够再结合定时查询就可以解决这个问题了,这个定时查询在Kubernetes中称之为resync。总结下,有三种事件通知策略:
1.Edge driven trigger 没有处理事件丢失的问题2.Edge driven trigger + Level-driven triggers,总是去获取最新的状态(当有事件来的时候),因此即使丢失一个事件,仍然可以通过获取最新的状态来进行业务逻辑3.Edge driven trigger + Level-driven triggers + resync 如果最后一个事件丢失了,后面没有事件来了,所以也不会去触发(Level-driven triggers),这个时候需要借助resync来得到最新的状态。
上面的这三种策略对应如下图:
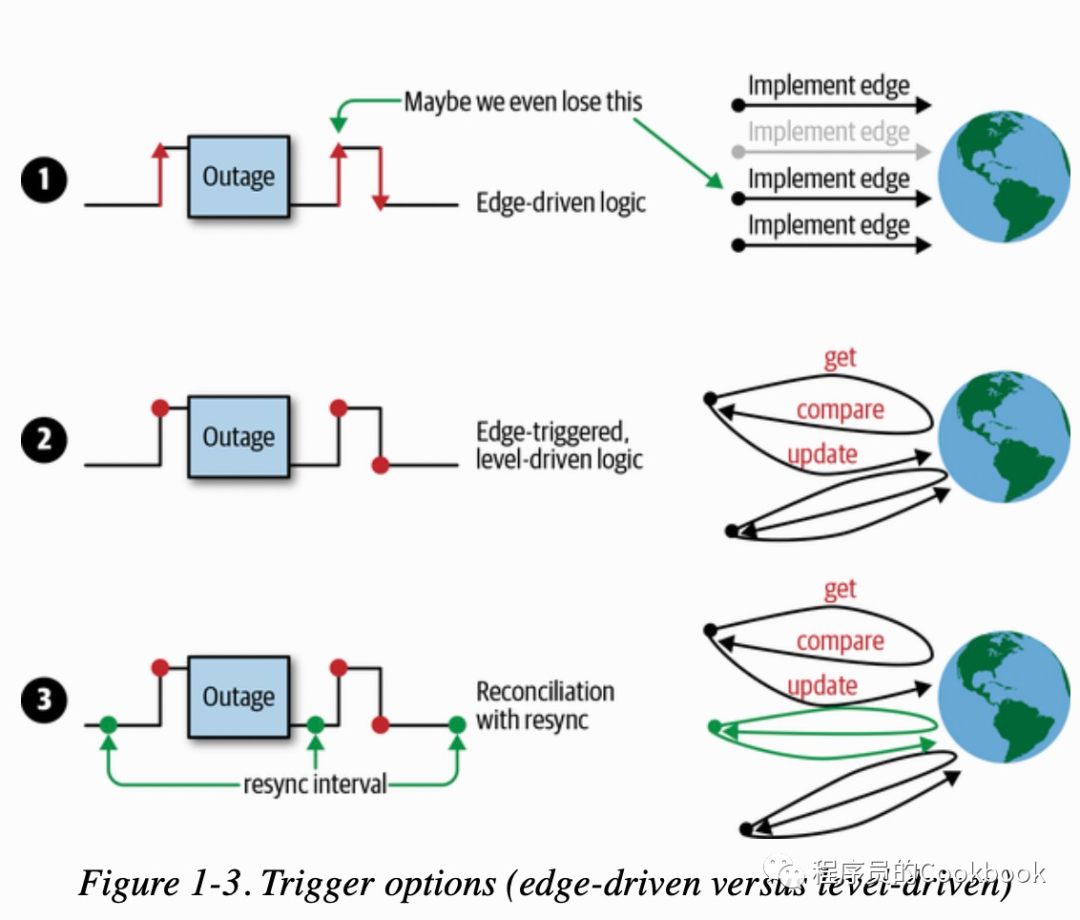
kubernetes实现了上面的第三种策略,通过这种方式来实现高效的事件通知,如果你想知道更多关于水平触发以及reconcile请参考level-triggering-and-reconciliation-in-kubernetes[2]
•Optimistic Concurrency
在Controller的Control loop中会改变集群中对象的状态(比如创建一个POD),然后将结果写到资源中的status中。实际中Controller通常会部署多个,因此这里更新资源的status字段是会存在并发写的。
下图中描述了一种解决方案:
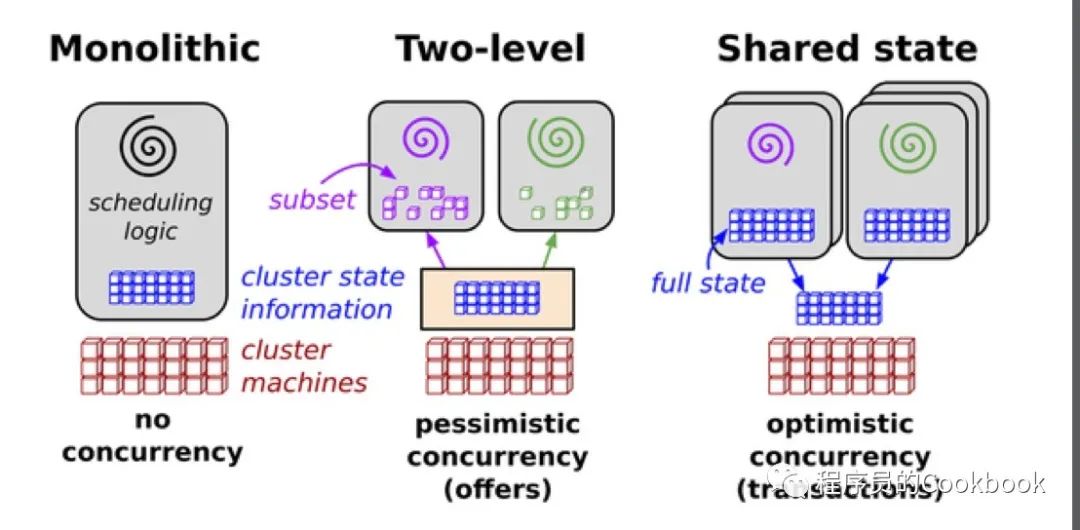
这个解决方案是基于共享状态构建的新的并行调度器体系结构,使用无锁乐观并发控制,以实现可扩展性和性能可伸缩性。这种架构正在谷歌的下一代集群管理系统Omega中使用 Kubernetes大量参考了Omega。为了做了无锁并发写,Kubernetes也采用了乐观并发。这意味着当API Server探测到并发写(通过resource version来判断), 它会拒绝掉后续的写操作。然后交由Controller自己来处理写入冲突的问题。可以简单的用下面的代码来表示这个过程。
var err errorfor retries := 0; retries < 10; retries++ {foo, err = client.Get("foo", metav1.GetOptions{})if err != nil {break}<update-the-world-and-foo>_, err = client.Update(foo)// 通过资源版本(ObjectMeta字段中的resource version)来判断当前是否有人在写入,是否会产生并发写的冲突if err != nil && errors.IsConflict(err) {continue} else if err != nil {break}}
乐观并发很适合Kubernetest中Controller的Controll Loop,Controll Loop中的水平触发总是获取到最新的状态,这个和乐观并发在失败后总是基于最新状态 再次发生写入的思想不谋而合。
写冲突错误在Controller中是完全正常的。我们应该总是预期它们会出现,并优雅地处理它们。client.Get返回的对象foo,包含了ObjectMeta字段,这个字段中包含了resource version,API Server借助这个字段来探测并发写。边缘触发 + 水平触发 + resync + optimistic concurrency 是Kubernetes 事件驱动架构的核心
•Operators
一个SRE是一人,他来操作其他开发工程师写的软件,这个软件是具有领域知识的,因此要运维需要掌握这个软件的领域知识才能运维好。而这些运维所需要的领域知识称之为Operator。一个Operator就是一个具有领域知识的用于运维的controller,借助了Kubernetes API进行扩展的Controller,借助这个Controller就可以实现简单的配置就达到运维复杂的带有状态的应用程序的效果。一般来说,这个Controller通过一组具有领域知识的schema组成的crd来实现自动化运维。
Reference
•extending-kubernetes-101[1]•The Mechanics of Kubernetes[2]•A deep dive into Kubernetes controllers[3]•深入浅出Event Sourcing和CQRS[4]•Events, the DNA of Kubernetes[5]•QoS, "Node allocatable" and the Kubernetes Scheduler[6]•level-triggering-and-reconciliation-in-kubernetes[7]•introducing-operators[8]
