一、词云简介

词云图从大量的文本信息筛选出重要的信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨(简单来说就是一眼就知道多次在文本中重复出现次数最多的字词)
二、词云制作
1、工具准备
1)、pycharm 已经部署完成
2)、python的三个库安装完成:
pip install wordcloudpip install jiebapip install matplotlib
3)、制作词云的文本信息
2、举个栗子
2.1、未指定词云出现模型图
代码
# ****** Auto : YangGaoChao ******************************# **** A beautiful day has begun. come on, Xiao Yang******# ***** Cretive time : 2021-06-16 20:10 ******************from wordcloud import WordCloudimport matplotlib.pyplot as plt #绘制图像的模块import jieba #jieba分词print("词云的文本路径类似:D://word_software/python_Study/词云/YC.txt")path_txt = input("请输入词云的文本路径:",)# path_txt = "D://YC.txt"f = open(path_txt,'r',encoding='UTF-8').read()# 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云cut_text = " ".join(jieba.cut(f))wordcloud = WordCloud(#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的font_path="C:/Windows/Fonts/simfang.ttf",#设置了背景,宽高background_color="white",width=1000,height=880).generate(cut_text)plt.imshow(wordcloud, interpolation="bilinear")plt.axis("off")plt.show()
运行截图:

2.2、指定词云出现模型图
代码:
# ****** Auto : YangGaoChao ******************************# **** A beautiful day has begun. come on, Xiao Yang******# ***** Cretive time : 2021-06-17 09:10 ******************from PIL import Imagefrom wordcloud import WordCloud, ImageColorGeneratorimport matplotlib.pyplot as pltimport numpy as npimport jiebadef YCGetWordCloud():print("词云的文本路径类似:D://word_software/python_Study/词云/YC.txt")path_txt = input("请输入词云的文本路径:",)print("词云的模型图路径类似:D://word_software/python_Study/词云/YC.jpg")path_img = input("请输入词云的文本路径:",)f = open(path_txt, 'r', encoding='UTF-8').read()background_image = np.array(Image.open(path_img))# 结巴分词,生成字符串,如果不通过分词,无法直接生成正确的中文词云,感兴趣的朋友可以去查一下,有多种分词模式#Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。cut_text = " ".join(jieba.cut(f))wordcloud = WordCloud(# 设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的font_path="C:/Windows/Fonts/simfang.ttf",# font_path="C:/Windows/Fonts/Consolas.ttf",background_color="white",# mask参数=图片背景,必须要写上,另外有mask参数再设定宽高是无效的mask=background_image).generate(cut_text)# 生成颜色值image_colors = ImageColorGenerator(background_image)# 下面代码表示显示图片plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")plt.axis("off")plt.show()if __name__ == '__main__':YCGetWordCloud()
为了方面大家使用;此段代码需要自己手动输入:词云图和词云文本的路径
运行结果:
三、词云库整理
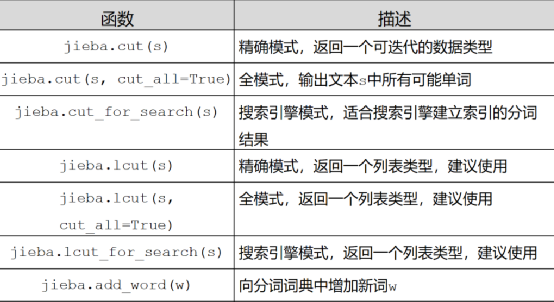
1、jieba包学习
1.1简介:
“jieba” (Chinese for “to stutter”)Chiese text segmention:built to be the best Python Chinse word segmenmtation module.
"jieba" Chiese文本分词:打造最好的Python中文分词模块。
1.2.、jieba库分词的三种模式:
1.2.1、精准模式:把文本精准地分开,不存在冗余
举个栗子:import jiebayc = jieba.lcut("与其降低你的开支,不如去尝试增加你的收入。这就是努力的理由")print(yc)
运行结果:
D:\word_software\python_Study\venv\Scripts\python.exe D:/word_software/python_Study/venv/06/0617/jieba整理.pyBuilding prefix dict from the default dictionary ...Loading model from cache C:\Users\Thinkpad\AppData\Local\Temp\jieba.cacheLoading model cost 0.592 seconds.Prefix dict has been built successfully.['与其', '降低', '你', '的', '开支', ',', '不如', '去', '尝试', '增加', '你', '的', '收入', '。', '这', '就是', '努力', '的', '理由']
1.2.2、全模式:把文中所有可能的词语都扫描出来,存在冗余
举个栗子:import jiebayc = jieba.lcut("与其降低你的开支,不如去尝试增加你的收入。这就是努力的理由", cut_all = True)print(yc)
运行结果:
D:\word_software\python_Study\venv\Scripts\python.exe D:/word_software/python_Study/venv/06/0617/jieba整理.pyBuilding prefix dict from the default dictionary ...Loading model from cache C:\Users\Thinkpad\AppData\Local\Temp\jieba.cache['与其', '降低', '你', '的', '开支', ',', '不如', '去', '尝试', '增加', '你', '的', '收入', '。', '这', '就是', '努力', '的', '理由']Loading model cost 0.689 seconds.Prefix dict has been built successfully.
1.2.3、搜索引擎模式:在精准模式的基础上,再次对长词进行切分
举个栗子:import jiebayc = jieba.lcut_for_search("与其降低你的开支,不如去尝试增加你的收入。这就是努力的理由")print(yc)
运行结果:
D:\word_software\python_Study\venv\Scripts\python.exe D:/word_software/python_Study/venv/06/0617/jieba整理.pyBuilding prefix dict from the default dictionary ...Loading model from cache C:\Users\Thinkpad\AppData\Local\Temp\jieba.cacheLoading model cost 0.709 seconds.Prefix dict has been built successfully.['与其', '降低', '你', '的', '开支', ',', '不如', '去', '尝试', '增加', '你', '的', '收入', '。', '这', '就是', '努力', '的', '理由']
1.3、语法总结
2、wordcloud库学习
2.1、简介:
优秀的词云展示第三方库,以词语为基本单位,通过图形可视化的方式,更加直观和艺术的展示文本。
2.2、基本使用
wordcloud 库把词云当作一个WordCloud对象
wordcloud.WordCloud()代表一个文本对应的词云
可以根据文本中词语出现的频率等参数绘制词云
绘制词云的形状、尺寸和颜色均可设定
以WordCloud对象为基础,配置参数、加载文本、输出文件
2.3、配置对象参数:w= wordcloud.WordCloud(<参数>)
参数 描述width 指定词云对象生成图片的宽度,默认400像素w=wordcloud.WordCloud(width=600)height 指定词云对象生成图片的高度,默认200像素w=wordcloud.WordCloud(height=400)min_font_size 指定词云中字体的最小字号,默认4号w=wordcloud.WordCloud(min_font_size=10)max_font_size 指定词云中字体的最大字号,根据高度自动调节w=wordcloud.WordCloud(max_font_size=20)font_step 指定词云中字体字号的步进间隔,默认为1w=wordcloud.WordCloud(font_step=2)font_path 指定文体文件的路径,默认Nonew=wordcloud.WordCloud(font_path="msyh.ttc")max_words 指定词云显示的最大单词数量,默认200w=wordcloud.WordCloud(max_words=20)stop_words 指定词云的排除词列表,即不显示的单词列表w=wordcloud.WordCloud(stop_words="Python")mask 指定词云形状,默认为长方形,需要引用imread()函数from scipy.msc import imreadmk=imread("pic.png")w=wordcloud.WordCloud(mask=mk)background_color 指定词云图片的背景颜色,默认为黑色w=wordcloud.WordCloud(background_color="white")
2.4、举个栗子:
import jiebaimport wordcloudtxt="比你有钱的人,一定比你努力,比你努力的人,终有一天会比你有钱,生活本来就是平衡的,你不为赚钱付出辛苦,你就得为省钱烦恼,这不是鸡汤,是现实!。w=wordcloud.WordCloud(width=1000,font_path="C:\\Windows\\Fonts\\simfang.ttf",height=700)w.generate(" ".join(jieba.lcut(txt)))w.to_file("computerlanguage.png")
运行结果:

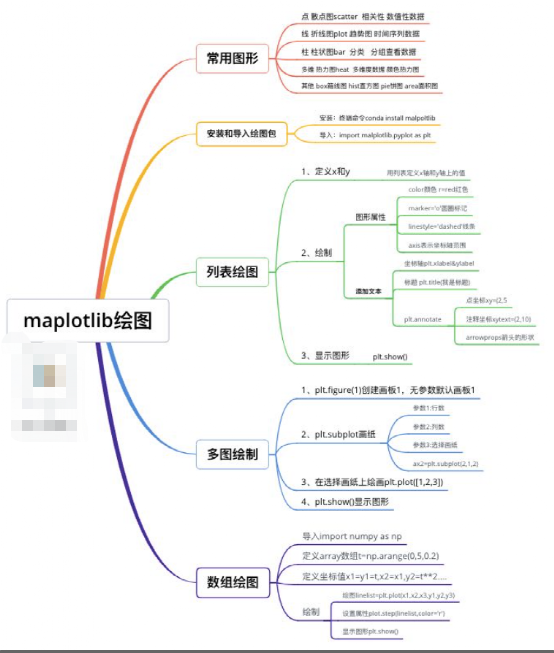
3. matplotlib库学习
3.1、matplotlib简介
Matplotlib 是Python中类似 MATLAB 的绘图工具,熟悉 MATLAB 也可以很快的上手 Matplotlib。
3.2、知识图谱