




单体应用程序中,我们往往会使用Synchronized、ReentrantLock、lock等悲观锁或者乐观锁实现对临界资源访问。但是在高并发分布式系统中,通过这些锁是无法完成操作上的互斥。
分布式锁需要具备哪些条件:
1、一个临界资源在同一时间只能被一个线程访问
2、高并发的获取和释放锁
3、高可靠的获取和释放锁
4、重入机制,同一线程第二次访问同一临界资源时能够不做线程切换
5、防止死锁,锁失效机制
6、没有获取到锁,不阻塞,防止线程大量阻塞,直接系统崩溃
常见的分布式锁有以下三种实现方式:
数据库实现分布式锁
此实现方式比较简单,就是获取临界资源之前先向数据库对应的表插入一条数据,插入成功,则获取锁,失败则说明锁已被持有;业务处理完,将此数据删除即可释放锁。具体在创建表时,将对应的字段做唯一性约束,多个请求同时提交,保证只有一个操作能够成功。
当然用数据库实现分布式锁只是一种可实现的方式,实际中并不会有人真的这么做,它存在以下问题:
1、数据库单点问题
2、程序没有删掉对应的记录,造成临界资源一直无法访问的死锁问题
3、可重入问题,同一线程第二次访问无法再次获得锁,当然这个问题是可以解决的,增加个字段记录线程id就可以。
4、非阻塞问题,线程获取锁失败,无法进入等待队列,要想再次获取锁,只能通过再次调用获取锁的操作。
基于缓存实现分布式锁(此处介绍redis)
缓存存在的意义,将数据加载到内存中,不从磁盘加载数据,从而达到执行效率提升的目的。redis和memcache是主流的缓存工具,此处我们对redis实现分布式锁做一些讨论。
加锁解锁操作:
setnx lock value1 # 给key为lock设置value = value1 ,返回结果1成功(integer) 1 ;setnx lock value2 #试图覆盖lock的值,返回0表示失败(integer) 0del lock #删除locksetnx lock value2 #再次插入lock的值,返回1(integer) 1复制
setnx可以实现对相同key的互斥访问,如果某个客户端挂掉,del lock的操作没有执行,会有死锁问题。
防死锁操作:
给lock记录加上expired time;
//使用jedis的api,保证原子性 NX, 不存在则操作 EX ,设置有效期,单位是秒String result = jedis.set(key, requestId, "NX", "EX", expireTime);复制
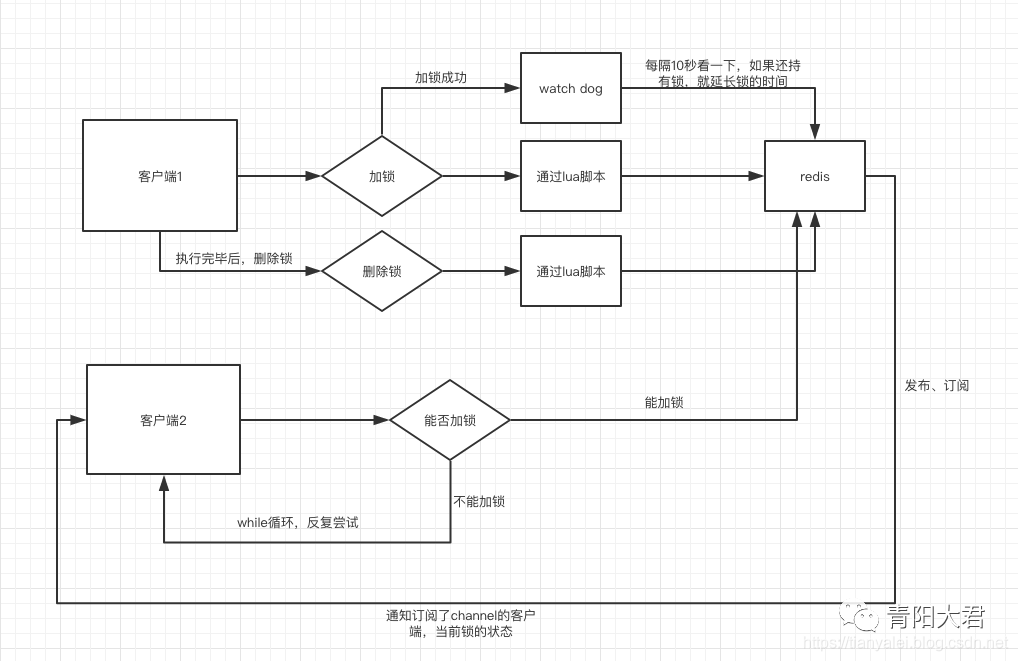
问题又来了,expireTime我怎么知道设置为多长时间呢?由程序员自己预估业务执行时间来设置过期时间有点不可靠,所以如果能启动监控线程,一直监控client线程是否挂掉,如果还在执行,那么就给lock记录的expireTime做续期操作,直到client线程自己释放掉锁。redisson框架实现分布式锁的思路就是通过watchdog机制实现锁的续期。
redisson实现分布式锁机制如下,有兴趣的可深入了解。
zookeeper实现分布式锁
zookeeper本来的设计是没有朝着用于分布式锁的方向发展的,只不过因为zk具有强一致性,且能够生成顺序的临时数据节点这一特性,所以可以作为可靠性很高的一个分布式锁的实现方式而被广泛应用。
zk创建临时节点命令:
sh zkcli.shcreate -s -e ${path} 0复制
如下:

在marvel路径下创建三个临时节点,序号顺序产生;
排他锁
排他锁(Exclusive Locks),又被称为写锁或独占锁,如果事务T1对数据对象O1加上排他锁,那么整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能进行读或写。
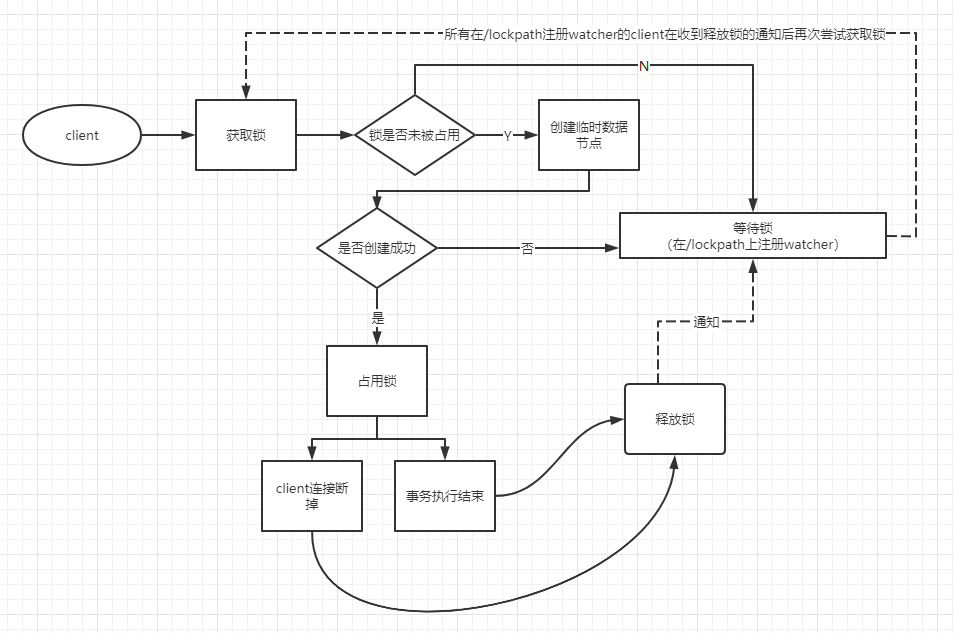
定义锁: 在/lockpath路径下成功创建临时数据节点。
获取锁: 创建临时数据节点,如果成功意味着成果获取锁。如果失败,则需要在节点/lockpath上注册watcher,监听持有锁的lock节点的变更情况。收到释放通知后客户端会再次尝试获取锁的操作。
释放锁: 客户端访问结束后将持有的临时数据节点删除。客户端释放zk的连接,临时数据节点即刻被释放。
共享锁
共享锁(Shared Locks),又称读锁。如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都释放。
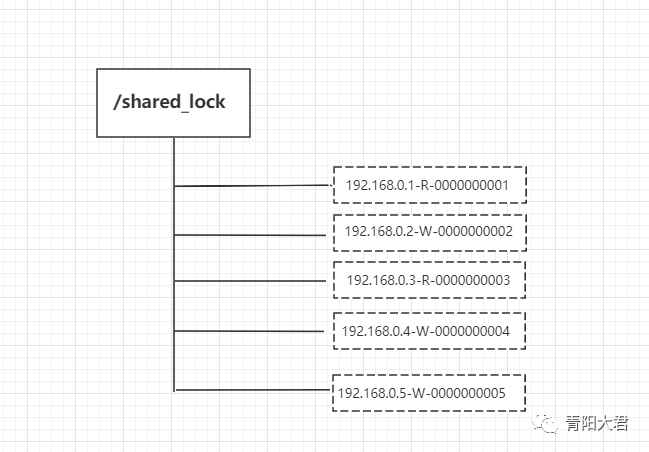
定义锁:
/shared_lock/[hostname]-请求类型W/R-序号复制
获取锁:
1、客户端调用 create 方法创建类似定义锁方式的临时顺序节点。
2、客户端调用 getChildren 接口来获取所有已创建的子节点列表。
3、对于读请求如果所有比自己小的子节点都是读请求或者没有比自己序号小的子节点,表明已经成功获取共享锁,同时开始执行读逻辑。对于写请求,如果自己不是序号最小的子节点,那么就进入等待。
释放锁:与排它锁一致。
共享锁获取流程:
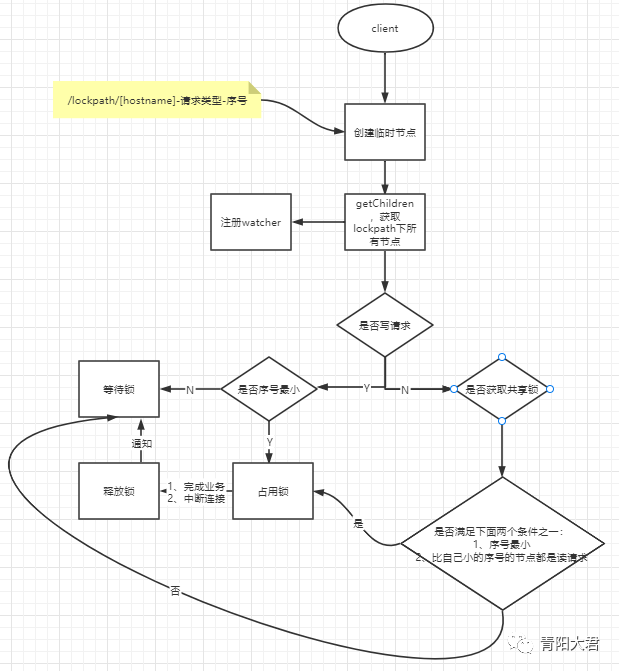
节点释放锁后需要向所有其他子节点发送watcher通知,获取所有节点的动作(getChildren)的操作,以及节点需要判断自己是否是最小节点或者比自己小的序号是否都是读操作(读节点),或者需要判断自己是否是最小的序号节点(写节点)。在并发量很大的情况下,这些操作会耗费很多的内存以及网络上的冲击。更为严重的是,如果同一时间有多个客户端释放了共享锁,Zookeeper服务器就会在短时间内向其余客户端发送大量的事件通知--这就是所谓的 "羊群效应"。
避免"羊群效应",写节点在watcher注册时只注册比自己小的序号,当比自己小的序号节点释放了锁,本节点即可占有锁;读节点注册比自己序号小的写节点,同样也能达到目的。此时,watcher通知的效率从 n*(n-1)/2 降到了n,大大缓解了上述存在的问题
实际开发过程中,可以 curator 工具包封装的API帮助我们实现分布式锁。
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>x.x.x</version></dependency>复制
curator 的几种锁方案 :
1、InterProcessMutex:分布式可重入排它锁
2、InterProcessSemaphoreMutex:分布式排它锁
3、InterProcessReadWriteLock:分布式读写锁
源码中通过acquire实现加锁
public boolean acquire(long time, TimeUnit unit) throws Exception {return this.internalLock(time, unit);}复制
通过release实现解锁
public void release() throws Exception {Thread currentThread = Thread.currentThread();InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread);if (lockData == null) {throw new IllegalMonitorStateException("You do not own the lock: " + this.basePath);} else {int newLockCount = lockData.lockCount.decrementAndGet();if (newLockCount <= 0) {if (newLockCount < 0) {throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + this.basePath);} else {try {this.internals.releaseLock(lockData.lockPath);} finally {this.threadData.remove(currentThread);}}}}}复制
有需要可实践操作curator工具包,此处不作详细展开。
总结
性能:缓存分布式锁>zk分布式锁>数据库
可靠性:zk分布式锁>缓存分布式锁>数据库
