





一、背景
近一段时间在做领域垂直分库的事情,如果你的系统之前没有严格遵守如下规则:
1、本领域只访问本领域数据表;
2、领域之间只通过RPC接口通信;
这时将会产生麻烦,最典型的问题是SQL耦合也就是跨领域联表查询,那么垂直分库的实施将是一件刺手的事情,因为你的业务代码可能需要改造,将耦合的跨域联查SQL分解,改造为RPC请求在业务层组装数据。
关于跨域联查SQL的分解:
1、简单情况下很容易分解(比如单条有明确ID值的联查);
2、复杂情况下(批量、分页、带跨领域的检索条件)就会遇到麻烦;
这种情况下几乎很难化解,原因如下:
1)跨领域的检索条件决定了你无法先在某一个领域上进行分页,这就导致需要全量加载关联数据到内存,再进行内存分页,数据量大的情况下这个方案是不可行的;
2)好一点的情况,即使检索条件可以限制在单个领域内,我们先进行检索条件所在领域的分页,然后通过指定ID批量检索其它领域的数据到内存,再进行内存数据组装,仍然需要比较大的计算和代码改动量。
基于团队现状考虑,为了减少领域垂直分库带来的影响,我们决定将某些数据表进行跨领域冗余,以便于解决SQL批量联查的需求。
二、方案
方案1、应用层维护数据,也就是应用层多写方案。
优点:不存在数据延迟
缺点很明显,1)应用层需要改动代码 2)分布式事务 3)扩展性不足
方案2、应用层维护数据,观察者模式,多写方案
优点:不存在数据延迟
缺点:1)应用层需要较大改动代码 2)分布式事务
方案3、通过MySQL的binlog进行数据同步
优点:1)与应用层解耦,无需改动代码,对已有系统影响最小 2)柔性事务 3)扩展性也可以
缺点:需要解决数据同步系统的稳定性与数据延迟情况
毫无疑问我肯定选择方案3了

三、基于binlog的数据同步方案
通过binlog实现数据同步又可以细分为多种方案:
1)基于云厂商的收费DTS服务
收费,可能遇到无法满足的需求就麻烦了
2)基于开源的Canal
Canal的生态很丰富,它可以和多种中间件对接,比如kafka等,进一步灵活分发数据
3)基于开源的Maxwell
最大的优点是接入简单,但是功能和生态都有限,提供的元数据也有限,提供基于json的数据格式,可以用在特定的场景
4)基于成品的Otter(为数据同步而生)
应该是阿里早期的数据同步系统吧,后来进行了开源,基于Canal实现的数据同步方案,虽然它里面没有引入消息分发中间件,使用的技术比较陈旧,毕竟是早些年开发的,但是功能依然强大灵活,如果能深入理解它的架构,熟练使用它,甚至二次开发,无疑可以节省大量的研发费用。
由于是对旧系统的改造,所以还有一个需求是数据的初始化(全量同步),另外还涉及到额外的需求,比如说由于各种原因造成了数据的不一致,那么如何进行数据纠正呢?综合考虑之后我选择了Otter
四、Otter为数据同步而生
Otter的原理与详细介绍 见官方文档:https://github.com/alibaba/otter

上面的图可以看出Otter是基于Canal实现的,可以认为是一个可直接使用的数据同步产品或系统
今天着重介绍几个Otter落地过程中遇到的问题
1)利用自由门功能实现 数据的全量传输,应用场景:数据初始化、数据纠正
2)自研的自由门助手工具以及Otter自由门功能代码中的一个BUG
3)容器化部署
4)Otter的配置
五、数据初始化方案
在实施过程中你遇到的第一个问题就是历史数据的处理,方案一般就是全量传输+增量传输
方法1:
DBA进行表结构和数据的导出导入,同时记录binlog的位点,等初始化完成之后再开启Otter进行增量传输(启动通道之前将Canal的位点设置为前面DBA记录的位点)
方法2:
开启Otter的增量传输功能,模式设置为 行记录模式,同时使用Otter的自由门功能进行数据自定义传输(数据初始化)
那么应该使用哪种方法呢?
首先无论使用哪种方法,你都应该在业务低峰时间段进行,如果可能的话甚至可以将应用进行停机再操作;然后老吕认为如果你的数据量比较大(历史记录总数千万以上)的情况下可以使用第一种方法速度更快更安全,如果数据量不太大(历史记录总数千万以下吧)的情况下可以使用方法2,毕竟方法2的原理是基于主键的反查源库再插入目标库,它的速度肯定不如方法1的。
六、自由门传输助手
自由门传输助手是我为了方便使用自由门的功能特地开发的一个工具,首先看下官方对自由门的使用方法描述:
自定义数据同步(自 由 门)主要功能是在不修改原始表数据的前提下,触发一下数据表中的数据同步。可用于:同步数据订正全量数据同步. (自 由 门触发全量,同时otter增量同步,需要配置为行记录模式,避免update时因目标库不存在记录而丢失update操作)主要原理:a. 基于otter系统表retl_buffer,插入特定的数据,包含需要同步的表名,pk信息。b. otter系统感知后会根据表名和pk提取对应的数据(整行记录),和正常的增量同步一起同步到目标库。目前otter系统感知的自 由 门数据方式为:日志记录. (插入表数据的每次变更,需要开启binlog,otter获取binlog数据,提取同步的表名,pk信息,然后回表查询整行记录)retl_buffer表结构:CREATE TABLE retl_buffer(ID BIGINT AUTO_INCREMENT, ## 无意义,自增即可TABLE_ID INT(11) NOT NULL, ## tableId, 可通过该链接查询:http://otter.alibaba-inc.com/data_media_list.htm,即序号这一列,如果配置的是正则,需要指定full_name,当前table_id设置为0.FULL_NAME varchar(512), ## schemaName + '.' + tableName (如果明确指定了table_id,可以不用指定full_name)TYPE CHAR(1) NOT NULL, ## I/U/D ,分别对应于insert/update/deletePK_DATA VARCHAR(256) NOT NULL, ## 多个pk之间使用char(1)进行分隔GMT_CREATE TIMESTAMP NOT NULL, ## 无意义,系统时间即可GMT_MODIFIED TIMESTAMP NOT NULL, ## 无意义,系统时间即可CONSTRAINT RETL_BUFFER_ID PRIMARY KEY (ID)) ENGINE=InnoDB DEFAULT CHARSET=utf8;全量同步操作示例:insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'$schema.table$','I',id,now(),now() from $schema.table$);如果针对多主键时,对应的PK_DATA需要将需要同步表几个主键按照(char)1进行拼接,比如 concat(id,char(1),name)
它的原理是基于主键反查
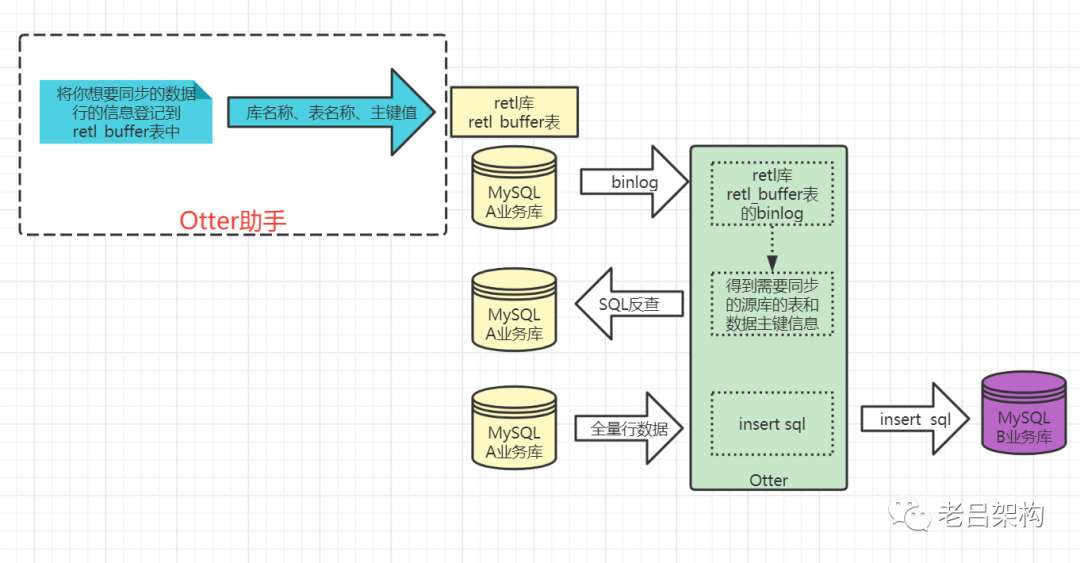
在上图中我已经标出来Otter助手要解决的问题了,在数据库较多、数据表较多(分库+多表+联合主键)的场景下 insert语句的生成是一个耗时费力的工作,所以就写了一个助手工具来解决这个问题,通过简单的配置就可以自动化进行解放人工操作。
在Otter助手开发过程中遇到的一个较大问题就是,当数据表是联合主键的情况存在一个主键排序的bug,我已经在github上提了问题(https://github.com/alibaba/otter/issues/1015),当然目前我是通过和官方保持一致的获取联合主键顺序的方法(看源码)来化解这个问题的。
(获取一个表的主键的方法:
方法1:利用 information_schema.key_column_usage和
information_schema.table_constraints来查询联合主键信息,并且是按从小到大排序的,是准确的,和索引顺序一致。(我最初的方案)
方法2:使用了 information_schema.column表取出的主键名称,它的联合主键顺序是和字段的排列位置相关的,和索引的顺序可能不一致。(Otter使用ddlutils组件中的方案))
七、容器化部署
官方给出的是一个all in one 的容器部署方案,只适合用来演示用。
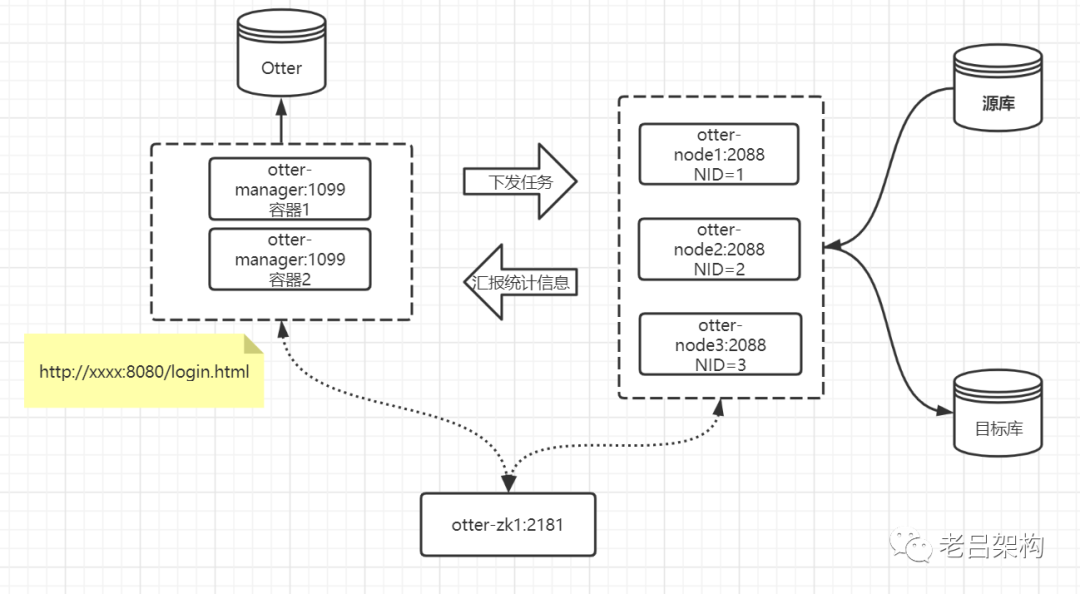
真正的线上环境是要自己改造的,其实并不容易。主要原因是 NID这个东西要提前在manager中配置生成,还有指定node-ip和node-port,很明显这个设计就不是为容器部署而设计的。只不过是目前容器部署已成主流,被迫适应改造。
我们通过在manager中固定NID和服务名称的方式来进行,同时Node的NID通过环境变量动态传入,和manager中保持一致。Node的服务名称和NID一一绑定。如下图。
1、镜像的制作
可以以官方的Dockerfile为基础来拆分或者自己从头定制,分为 otter-manager、otter-node两个镜像,
其它的zk和mysql都使用独立的服务。
主要步骤就是环境变量的定制和替换,然后启动bin下的start.sh 即可。
当然官方给出的demo里面是有很多额外的情况处理的,可按需保留。
manager的Dockerfile
FROM canal/osbase:v1MAINTAINER lval# install otterCOPY image/ home/admin/RUN \chmod +x home/admin/*.sh && \chown admin: -R home/admin && \yum clean all && \trueENV DOCKER_DEPLOY_TYPE=VM PATH=$PATHWORKDIR /home/adminENTRYPOINT [ "/home/admin/app.sh" ]
app.sh 内容
#!/bin/bashset -esource etc/profileexport JAVA_HOME=/usr/java/latestexport PATH=$JAVA_HOME/bin:$PATHchown admin: home/admin/managerhost=`hostname -i`echo ${host}cmd="rm -f home/admin/manager/bin/otter.pid"echo $cmdeval $cmd# default configif [ -z "${MYSQL_USER_PASSWORD}" ]; thenMYSQL_USER_PASSWORD="otter"fiif [ -z "${OTTER_MANAGER_MYSQL}" ]; thenOTTER_MANAGER_MYSQL="127.0.0.1:3306"fi# waitterm# wait TERM/INT signal.# see: http://veithen.github.io/2014/11/16/sigterm-propagation.htmlwaitterm() {local PID# any process to blocktail -f dev/null &PID="$!"# setup trap, could do nothing, or just kill the blockertrap "kill -TERM ${PID}" TERM INT# wait for signal, ignore wait exit codewait "${PID}" || true# clear traptrap - TERM INT# wait blocker, ignore blocker exit codewait "${PID}" 2>/dev/null || true}function checkStart() {local name=$1local cmd=$2local timeout=$3cost=5while [ $timeout -gt 0 ]; doST=`eval $cmd`if [ "$ST" == "0" ]; thensleep 1let timeout=timeout-1let cost=cost+1elif [ "$ST" == "" ]; thensleep 1let timeout=timeout-1let cost=cost+1elsebreakfidoneecho "$name start successful"}function start_manager() {echo "start manager ..."# start managerif [ -n "${OTTER_MANAGER_ZK}" ] ; thenecho "config manager zookeeper env...${OTTER_MANAGER_ZK}"cmd="sed -i -e 's/^otter.zookeeper.cluster.default.*$/otter.zookeeper.cluster.default = ${OTTER_MANAGER_ZK}/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdfiecho "config manager mysql env..."cmd="sed -i -e 's/^otter.communication.manager.port.*$/otter.communication.manager.port = 1099/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdif [ -n "${OTTER_MANAGER_MYSQL}" ] ; thencmd="sed -i -e 's/^otter.database.driver.url.*$/otter.database.driver.url = jdbc:mysql:\/\/${OTTER_MANAGER_MYSQL}\/otter/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdfiif [ -n "${MYSQL_USER}" ] ; thencmd="sed -i -e 's/^otter.database.driver.username.*$/otter.database.driver.username = ${MYSQL_USER}/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdcmd="sed -i -e 's/^otter.database.driver.password.*$/otter.database.driver.password = ${MYSQL_USER_PASSWORD}/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdfiif [ -n "${host}" ] ; thencmd="sed -i -e 's/^otter.domainName.*$/otter.domainName = ${host}/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdfiif [ -n "${OTTER_DOMAIN_NAME}" ] ; thencmd="sed -i -e 's/^otter.domainName.*$/otter.domainName = ${OTTER_DOMAIN_NAME}/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdfiif [ -n "${OTTER_PORT}" ] ; thencmd="sed -i -e 's/^otter.port.*$/otter.port = ${OTTER_PORT}/' home/admin/manager/conf/otter.properties"eval $cmdecho $cmdfiecho "run manager bin startup.sh..."su admin -c "cd home/admin/manager/bin ; sh startup.sh "echo "run manager bin startup.sh...OKL"#check start#sleep 5#checkStart "manager" "nc 127.0.0.1 8080 -w 1 -z | wc -l" 60}function stop_manager() {# stop managerecho "stop manager"su admin -c 'cd home/admin/manager/bin; sh stop.sh 'echo "stop manager successful ..."}echo "==> START ..."start_managerecho "you can visit manager link : http://$host:8080/ , just have fun !"echo "==> START SUCCESSFUL ..."tail -f dev/null &# wait TERM signalwaittermecho "==> STOP"stop_managerecho "==> STOP SUCCESSFUL ..."
node的Dockerfile
FROM canal/osbase:v1MAINTAINER lval# install otterCOPY image/ home/admin/RUN \mkdir -p home/admin/node/logs && \chmod +x home/admin/*.sh && \chown admin: -R home/admin && \yum clean all && \trueENV DOCKER_DEPLOY_TYPE=VM PATH=$PATHWORKDIR /home/adminENTRYPOINT [ "/home/admin/app.sh" ]
app.sh内容:
#!/bin/bashecho 'waiting manager startup...'sleep 30set -esource /etc/profileexport JAVA_HOME=/usr/java/latestexport PATH=$JAVA_HOME/bin:$PATHchown admin: /home/admin/nodehost=`hostname -i`cmd="rm -f /home/admin/node/bin/otter.pid"echo $cmdeval $cmd# waitterm# wait TERM/INT signal.# see: http://veithen.github.io/2014/11/16/sigterm-propagation.htmlwaitterm() {local PID# any process to blocktail -f /dev/null &PID="$!"# setup trap, could do nothing, or just kill the blockertrap "kill -TERM ${PID}" TERM INT# wait for signal, ignore wait exit codewait "${PID}" || true# clear traptrap - TERM INT# wait blocker, ignore blocker exit codewait "${PID}" 2>/dev/null || true}function checkStart() {local name=$1local cmd=$2local timeout=$3cost=5while [ $timeout -gt 0 ]; doST=`eval $cmd`if [ "$ST" == "0" ]; thensleep 1let timeout=timeout-1let cost=cost+1elif [ "$ST" == "" ]; thensleep 1let timeout=timeout-1let cost=cost+1elsebreakfidoneecho "$name start successful"}function start_node() {echo "start node ..."# start nodeif [ -n "${OTTER_MANAGER_ZK}" ] ; thenecho "config node zookeeper env...${OTTER_MANAGER_ZK}"cmd="sed -i -e 's/^otter.zookeeper.cluster.default.*$/otter.zookeeper.cluster.default = ${OTTER_MANAGER_ZK}/' /home/admin/node/conf/otter.properties"eval $cmdfiif [ -n "${OTTER_MANAGER_ADDRESS}" ] ; thenecho "config node env...${OTTER_MANAGER_ADDRESS}"cmd="sed -i -e 's/^otter.manager.address.*$/otter.manager.address = ${OTTER_MANAGER_ADDRESS}/' /home/admin/node/conf/otter.properties"eval $cmdfiif [ -n "${OTTER_NODE_NID}" ] ; thenecho "config nid...${OTTER_NODE_NID}"su admin -c 'cd /home/admin/node/bin/ && echo ${OTTER_NODE_NID} > /home/admin/node/conf/nid && sh startup.sh'fi#sleep 5#check start#checkStart "node" "nc 127.0.0.1 2088 -w 1 -z | wc -l" 30}function stop_node() {# stop nodeecho "stop node"su admin -c 'cd /home/admin/node/bin/ && sh stop.sh'echo "stop node successful ..."}echo "==> START ..."start_nodeecho "==> START NODE SUCCESSFUL ..."tail -f /dev/null &# wait TERM signalwaittermecho "==> STOP"stop_nodeecho "==> STOP NODE SUCCESSFUL ..."
2、容器的编排
贴下docker-compose.xml内容:
version: '3.7'services:otter-zk:image: zookeepernetworks:- otter-networkdeploy:replicas: 1otter-manager:image: canal/otter-manager:latestenvironment:OTTER_MANAGER_ZK: 'otter-zk:2181'OTTER_MANAGER_MYSQL: '172.16.30.85:3306'MYSQL_USER: 'root'MYSQL_USER_PASSWORD: 'root'OTTER_DOMAIN_NAME: '172.16.30.85'OTTER_PORT: '8080'volumes:- /Users/lvaolin/code_gz/otter/otter-docker/docker-compose/managerLogs:/home/admin/manager/logsports:- target: 8080published: 8080protocol: tcpmode: hostnetworks:- otter-networkdeploy:replicas: 2mode: globalotter-node1:image: canal/otter-node:latestenvironment:OTTER_MANAGER_ZK: 'otter-zk:2181'OTTER_MANAGER_ADDRESS: 'otter-manager:1099'OTTER_NODE_NID: '1'volumes:- /Users/lvaolin/code_gz/otter/otter-docker/docker-compose/node1Logs:/home/admin/node/logsnetworks:- otter-networkdeploy:replicas: 1mode: globaldepends_on:- otter-manager- otter-zkotter-node2:image: canal/otter-node:latestenvironment:OTTER_MANAGER_ZK: 'otter-zk:2181'OTTER_MANAGER_ADDRESS: 'otter-manager:1099'OTTER_NODE_NID: '2'volumes:- /Users/lvaolin/code_gz/otter/otter-docker/docker-compose/node2Logs:/home/admin/node/logsnetworks:- otter-networkdeploy:replicas: 1mode: globaldepends_on:- otter-manager- otter-zkotter-node3:image: canal/otter-node:latestenvironment:OTTER_MANAGER_ZK: 'otter-zk:2181'OTTER_MANAGER_ADDRESS: 'otter-manager:1099'OTTER_NODE_NID: '3'volumes:- /Users/lvaolin/code_gz/otter/otter-docker/docker-compose/node3Logs:/home/admin/node/logsnetworks:- otter-networkdeploy:replicas: 1mode: globaldepends_on:- otter-manager- otter-zknetworks:otter-network:driver: bridgeattachable: true
八、Otter配置注意事项
1、Otter配置结构图,注意pipeline是没有一级菜单的,需要靠channal的穿透才能看到,一步一步穿透就能完成整个通道的配置了
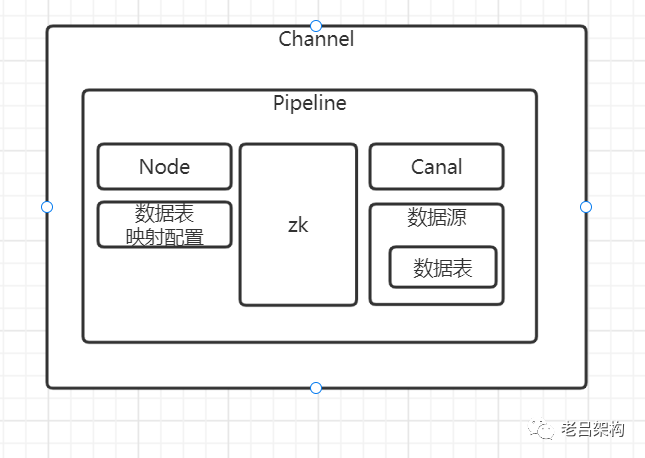
2、一般情况下每个Channal都是单向配置,它下面配置一个pipeline就够了。但是它也是支持双向配置的,如果是双向同步就需要配置两个pipeline了,每个pipeline负责一个方向的数据。
3、里面有很多选项和高级参数配置,大多数情况下默认就行了,用到的时候再研究修改。
4、一个canal的配置只能用到一个pipeline上,想想为什么,因为它没有接入MQ,就没有消息分发功能,只能靠一个位点来记录消费情况,所以只能被一个pipeline使用。
5、Otter中canal的消费位点信息保存在zookeeper中,注意zk的内容持久化,不要丢失。如果丢失了可以通过重新设置位点来解决,不过位点信息来源与哪里是个问题,日志中也有位点的记录,可以参考。实在不行就指定一个大概的位置了,可以靠前一些,设置为按行同步的模式就可以及时同步到最新状态,减少出现中间状态的旧数据了。
6、另外还有其它的信息也在zk中,如果丢失了就无法进入manager了,不过有办法恢复:
访问如下地址进行数据恢复 http://domain:8080/system_reduction.htm, 点击一键补全即可。
7、otter在pipeline进行库表映射选择的时候支持 正则表达式,这在多库多表场景下非常有用,大大提高配置效率。
8、另外在设置pipeline时可以设置 通过扩展 EventProcessor 接口的java源码的方式定制化处理过程,比如跳过,修改数据等。
9、Otter助手运行之前确保Otter通道处于开启状态
10、app.sh里的checkStart 方法在检测超时情况下会退出应用,这个注意,我已经关闭。
九、总结
在分析和使用Otter的过程中已经感受到了Otter功能的强大,同时也发现了一些不足,比如容器化部署困难,Node与Manager的之间的服务发现机制可以更加智能一些,免去NID、NodeIP、NodePort的手工指定。总之基于Otter的数据同步是一个可行的可节省研发费用的开源方案,有需求的同学可以研究一下。
