




近年来,Greenplum凭借其优秀的数据存储、处理和实时分析能力,已被广泛应用于数据仓库领域,去年还被Gartner评为全球排名第三的分析型数据库和排名第四的实时分析数据库。作为主打OLAP和数据分析的开源型MPP数据库, Greenplum经过十多年的打磨,于2019年12月底进行了6.0版本的大升级,TPC-B性能相比5.x提升60倍,单条查找提升350%,拥有了更强的HTAP能力。
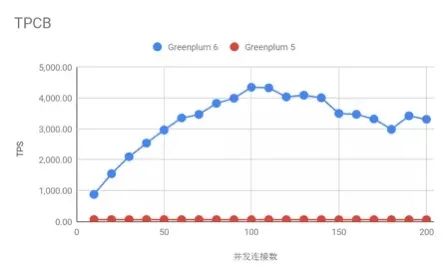
(数据对比图来源于Greenplum官方测试)
MPP架构:Greenplum采用MPP架构,具备线性扩展存储能力及分布式任务处理能力,支持数据的大规模并行计算。

高可用:支持主节点与计算节点增加冗余备份,节点宕机时可自动快速切换,降低整体数据仓库服务宕机风险确保数据不丢失。
多种数据存储方式:同时支持行存储及列存储的数据存储方式以及外部表存储,满足不同场景下的数据存储需求。
简单易用:高度兼容PostgreSQL语法,提供可视化的管理控制台,方便快捷管理监控数据仓库,降低入门成本。
移植了大量PostgreSQL的新特性在既有JSON类型上,支持JSONB存储格式,实现高性能的JSON数据处理及更丰富的JSON函数; 新增GIN索引和SP-GiST索引可以更高性能支持模糊匹配,以及中文检索; 支持了 schema 级别以及 column 列级别权限控制和授权等。
引入全局死锁检查机制,动态的收集和分析锁的信息来检查和解除全局死锁。基于此,HEAP表的更新修改操作可以只借助细粒度行锁完成; 支持大并发的更改删除查询,提高整个系统的并发度和吞吐量; 同时还对事务锁进行了优化,减少了开始事务和结束事务时的锁竞争,在既有高性能 OLAP分析基础上,也可以提供高吞吐交易事务处理。
针对数仓中的维度表,通过建立复制表,可以大量减少数据传输,提升查询效率; 支持zstandard压缩算法:ZSTD压缩算法,较之前 zlib 压缩算法,提升三倍的压缩和解压性能; 采用一致性hash,扩容速度更快;扩容无需停机。

数据仓库
数据分析平台
地理信息数据分析
机器学习

分布策略:支持哈希分布(DISTRIBUTED BY(key))和随机分布(DISTRIBUTED RANDOMLY),复制表【6.x版本的新特性】; 存储方式:行存储、列存储、HDFS外部表; 压缩:可以支持字段级别的压缩; 索引:可以加快查询,需要额外的存储空间; 分区: range分区:把数据根据指定的范围进行分区,例如:时间范围、数值范围 list分区:把数据按照一个list的值进行分区,例如:产品的种类、地区
简单易用:通过可视化的管理控制台,快速的搭建一套Greenplum系统,无需关注复杂的安装和运维,在控制台上很方便的实现集群管理和运维监控等工作。
高可用:主节点与计算节点增加冗余备份,节点宕机时可自动快速切换,降低整体数据仓库服务宕机风险确保数据不丢失。
弹性伸缩:通过控制台增加节点很方便的实现计算能力和存储能力的快速扩容
低成本:支持数据压缩、深度优化的软硬件方案,按实际数据处理需求开通节点实例,无需为搭建数据仓库一次性投入高额成本,同时降低运维人力成本。
完善的监控和异常自动处理:UDW经历了多年的积累,从硬件、系统、软件层面进行了各个维度的监控,便于及时发现问题。同时借助异常自动处理机制,快速处理各种异常,例如:segment的自动恢复,segment发生主从切换之后自动rebalance、故障节点的自动迁移等等。


