





作为Hadoop集群维护人员,经常误操作直接将HBase表数据误删除,生产数据肯定是不能直接删除的,下面我详细给大家演示下,如何快速恢复误删除的表:
为方便大家理解,我先讲一下HBase在hdfs上的目录结构,先看下面这张图:
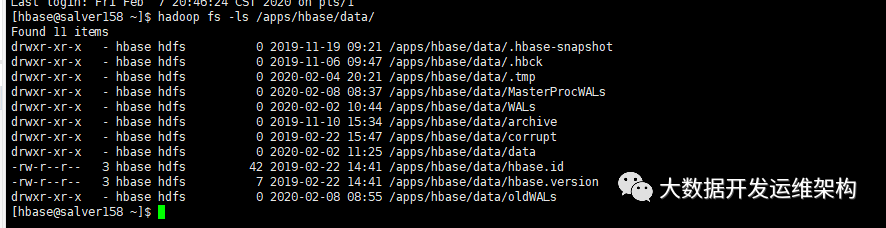
一共9个目录和2个文件:
目录:
1.hbase-snapshot
如果hbase开启了快照,用户对一个数据表建立快照table_snapshot1,则hbase会在这个目录下新建一个文件夹table_snapshot1。
2. .hbck
这个hbase hbck 相关的集群修复命令的一个临时缓存目录。
3. .tmp
临时目录,用户创建、删除表的时候的,会用到这个临时目录4.MasterProcWALs
目录下有一个状态文件,记录管理操作日志记录文件,比如解决冲突的服务器,表创建和其它DDLs等操作到它的WAL文件中,这个WALs存储在MasterProcWALs目录下,它不像RegionServer的WALs,HMaster的WAL也支持弹性操作,就是如果Master服务器挂了,其它的Master接管的时候继续操作这个文件。
5.WALs
HLog预写日志文件
6.archive
存储表的归档和快照,HBase 在做 Split或者 compact 操作完成之后,会将 HFile 移到archive 目录中,然后将之前的 hfile 删除掉,该目录由 HMaster 上的一个定时任务定期去清理。
7.corrupt
损坏的日志文件
8.data
HBase表数据
9.oldWALs
当WALs中的日志文件不再需要时,会先放到这个目录下,等待清理。
文件:
hbase.id
它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。
hbase.version
hbase.version记录了hbase的版本,是一个二进制文件。
1.直接删除HBase表数据在HDFS上的目录
如果你直接从hdfs上删除了数据,由于hdfs每个用户都有个回收站目录:/user/$/.Trash/,删除后可从回收站直接恢复即可,这个比较简单。

hadoop的回收站是在我们删除数据后能恢复的目录,但是我们并不希望在回收站保存太久的数据,我们可以使用如下参数进行配置。
参数介绍:
1).fs.trash.interval=0
以分钟为单位的垃圾回收时间,垃圾站中数据超过此时间,会被删除。如果是0,垃圾回收机制关闭。
可以配置在服务器端和客户端。
如果在服务器端配置trash无效,会检查客户端配置。如果服务器端配置有效,客户端配置会忽略。
建议开启,建议4320(3天)
垃圾回收站,如有同名文件被删除,会给文件顺序编号,例如:a.txt,a.txt(1)
2).fs.trash.checkpoint.interval=0
以分钟为单位的垃圾回收检查间隔。应该小于或等于fs.trash.interval。如果是0,值等同于fs.trash.interval。每次检查器运行,会创建新的检查点。
建议设置为60(1小时)
2.通过disable+drop删除了HBase的数据表
这里用表testTable1演示数据恢复过程:
a).登录hbase shell中查看表中有两条数据:
hbase(main):004:0> scan 'testTable1'ROW COLUMN+CELLrow001 column=info1:col1, timestamp=1581149494656, value=value1row001 column=info1:col2, timestamp=1581149504948, value=value21 row(s) in 0.0330 seconds复制
原来表的存储目录是:/apps/hbase/data/data/default/testTable1
b).用disable+drop删除表
hbase(main):005:0* disable 'testTable1'0 row(s) in 2.3000 secondshbase(main):006:0> drop 'testTable1'0 row(s) in 1.2510 seconds复制
c).在hbase的归档目录archive下可查看已删除的数据
[hbase@master98 ~]$ hadoop fs -ls apps/hbase/data/archive/data/defaultFound 2 itemsdrwxr-xr-x - hbase hdfs 0 2019-11-10 15:34 apps/hbase/data/archive/data/default/test12drwxr-xr-x - hbase hdfs 0 2020-02-08 15:47 /apps/hbase/data/archive/data/default/testTable1复制
d).由于这个数据是有保存时间的(这个保存时间恢复完数据后下面我专门讲解),先将已删除额testTable1的数据拷贝到/tmp下备份,以防hbase自身定时任务清理掉。
[hbase@master98 ~]$ hadoop fs -ls tmp/defaultFound 2 itemsdrwxr-xr-x - hbase hdfs 0 2020-02-08 15:51 tmp/default/test12drwxr-xr-x - hbase hdfs 0 2020-02-08 15:51 tmp/default/testTable1复制
e).新建同名、同列族的表testTable1,这时testTable1会在hdfs上重新有一个目录,下面共3个子目录:
hbase(main):002:0> ^C[hbase@master98 ~]$ hadoop fs -ls apps/hbase/data/data/default/testTable1Found 3 itemsdrwxr-xr-x - hbase hdfs 0 2020-02-08 16:19 apps/hbase/data/data/default/testTable1/.tabledescdrwxr-xr-x - hbase hdfs 0 2020-02-08 16:19 apps/hbase/data/data/default/testTable1/.tmpdrwxr-xr-x - hbase hdfs 0 2020-02-08 16:19 /apps/hbase/data/data/default/testTable1/7688ca7556d73db2d8ba69128da544f8复制
f).将备份的数据拷贝到新的testTable1表在hbase的存储目录下,不要拷贝整个目录,只拷贝/tmp/testTable1/*下的region数据目录,这时新testTable1表下面就会多了一个region数目目录,这时共4个子目录,如下:
#拷贝命令一定不要出错[hbase@master98 ~]$ hadoop fs -cp tmp/testTable1/dd4adf04aea66bd5912275e577f2ef6a apps/hbase/data/data/default/testTable1/[hbase@master98 ~]$ hadoop fs -ls apps/hbase/data/data/default/testTable1Found 4 itemsdrwxr-xr-x - hbase hdfs 0 2020-02-08 16:19 apps/hbase/data/data/default/testTable1/.tabledescdrwxr-xr-x - hbase hdfs 0 2020-02-08 16:19 apps/hbase/data/data/default/testTable1/.tmpdrwxr-xr-x - hbase hdfs 0 2020-02-08 16:19 apps/hbase/data/data/default/testTable1/7688ca7556d73db2d8ba69128da544f8drwxr-xr-x - hbase hdfs 0 2020-02-08 16:20 /apps/hbase/data/data/default/testTable1/dd4adf04aea66bd5912275e577f2ef6a复制
h).这时候你去查询hbase数据的时候是看不到数据的,因为在hbase的元数据表.meta中并没有原来那个region的元数据信息,需要进行修复:
hbase(main):001:0> scan 'testTable1'ROW COLUMN+CELL0 row(s) in 0.2490 seconds复制
i).表修复,切换到hbase管理员用户:su - hbase,执行hbase hbck相关命令进行修复,具体该执行哪个命令要根据hbase hbck的报错信息进行修复,hbse hbck修复命令:
1. 检查输出所以ERROR信息,每个ERROR都会说明错误信息。hbase hbck2. 先修复tableinfo缺失问题,根据内存cache或者hdfs table 目录结构,重新生成tableinfo文件。hbase hbck -fixTableOrphans3. 修复regioninfo缺失问题,根据region目录下的hfile重新生成regioninfo文件hbase hbck -fixHdfsOrphans4. 修复region重叠问题,merge重叠的region为一个region目录,并从新生成一个regioninfohbase hbck -fixHdfsOverlaps5. 修复region缺失,利用缺失的rowkey范围边界,生成新的region目录以及regioninfo填补这个空洞。hbase hbck -fixHdfsHoles6.修复meta表信息,利用regioninfo信息,重新生成对应meta row填写到meta表中,并为其填写默认的分配regionserverhbase hbck -fixMeta7. 把这些offline的region触发上线,当region开始重新open 上线的时候,会被重新分配到真实的RegionServer上 , 并更新meta表上对应的行信息。hbase hbck -fixAssignments复制
我首先执行了hbase hbck检查了集群整体状态,报错表testTable1缺少元数据信息,需要执行hbase hbck -fixMeta 进行修复,如果修复失败,可依次尝试fixHdfsOrphans,fixTableOrphans,fixMeta,fixAssignments参数进行修复:

修复多执行几次,直到再次执行hbase hbck显示下图时,说明修复成功,表数据可查询:
0 inconsistencies detected.Status: OK复制
去hbase shell中验证一把,数据可查询,至此修复成功:
hbase(main):001:0> scan 'testTable1'ROW COLUMN+CELLrow001 column=info1:col1, timestamp=1581149494656, value=value1row001 column=info1:col2, timestamp=1581149504948, value=value21 row(s) in 0.3030 seconds复制
上面涉及到了几个知识点,我再给大家详细说一下:
HBase的数据主要存储在分布式文件系统HFile和HLog两类文件中。Compaction操作会将合并完的不用的小Hfile移动到<.archive>文件夹,并设置ttl过期时间。HLog文件在数据完全flush到hfile中时便会过期,被移动到.oldlog文件夹中。
HMaster上的定时线程HFileCleaner/LogCleaner周期性扫描.archive目录和.oldlog目录, 判断目录下的HFile或者HLog是否可以被删除,如果可以,就直接删除文件。
关于hfile文件和hlog文件的过期时间,其中涉及到两个参数:
(1)hbase.master.logcleaner.ttl
HLog在.oldlogdir目录中生存的最长时间,过期则被Master的线程清理,默认是600000(ms);
(2)hbase.master.hfilecleaner.plugins:
HFile的清理插件列表,逗号分隔,被HFileService调用,可以自定义,默认org.apache.hadoop.hbase.master.cleaner.TimeToLiveHFileCleaner。
(3) hbase.master.hfilecleaner.ttl:
默认hfile的失效时间是5分钟,在主region发生compaction之后,被compact掉的文件会放入Archieve文件夹内,超过hbase.master.hfilecleaner.ttl时间后,文件就会被从HDFS删除掉。而此时,可能replica region正在读取这个文件,这会造成用户的读取抛错返回。如果不想要这种情况发生,就可以把这个参数设为一个很大的值,比如说3600000(一小时),总没有读操作需要读一个小时了吧?
实际在测试的过程中,删除一个hbase表,在hbase的hdfs目录下的archive文件夹中,会立即发现删除表的所有region数据(不包含regioninfo、tabledesc等元数据文件),等待不到6分钟所有数据消失,说明所有数据生命周期结束,被删除。在hfile声明周期结束到被发现删除中间间隔不到一分钟。
如果觉得我的文章能帮到您,请关注微信公众号,并转发朋友圈,谢谢支持!!!

