




从Oracle Goldengate 11.2开始,oracle引入了一种新的capture mode,称为Integrated Capture Mode。传统的capture mode被称为classic capture mode。
在classic capture mode中,goldengate extract进程直接读取oracle redo log,捕获数据变化,存为Goldengate的trail file格式,然后利用pump进程将这些trail file传输到目标数据库,目标数据库上的replicat进程读取这些trail file,再利用sql将这些变化apply到目标数据库里。
在新的integrated capture mode中,goldengate extract进程不再直接读取oracle redo log,而是通过与数据库log mining server整合来捕获数据变化。log mining server负责以LCR的格式从数据库日志中捕获数据变化,放在stream_pool中;然后extract进程再将这些抓取的数据存成trail file的格式。
与classic capture mode相比,这种integrated capture mode的主要差别就是extract不再直接读取oracle redo log,而交由数据库内部的log mining工具来完成。
由于extract进程是由操作系统来管理的,身处数据库系统之外,integrated capture mode的这种改变所带来的主要好处体现在兼容性方面:支持更多的数据类型和存储类型,以及由于与数据库更紧密的整合,不再需要为Oracle RAC,ASM和TDE作更多额外的配置工作。
以上看起来integrated capture优点多多(不列举),但是缺点呢?
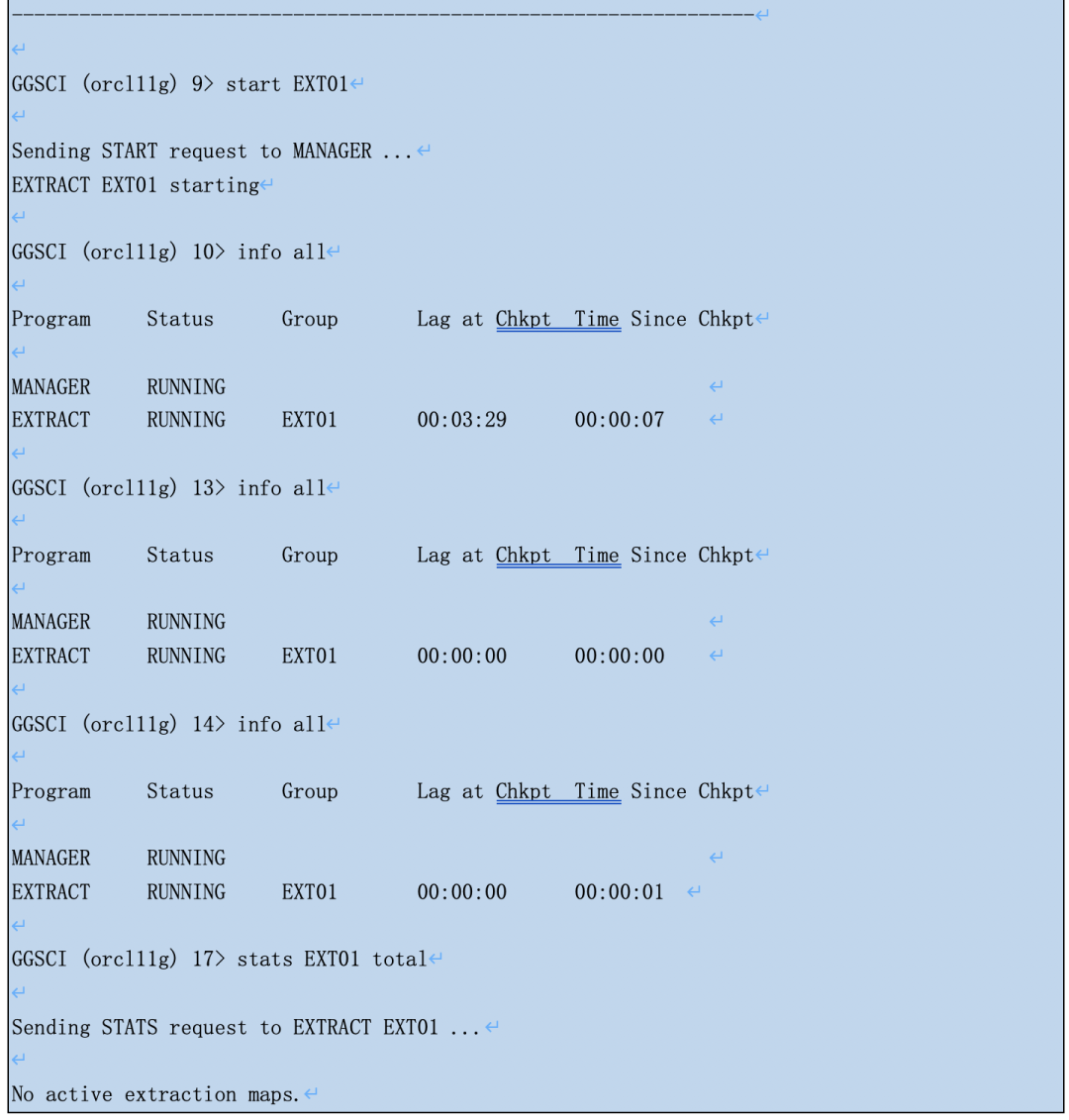
以前配置classic capture,只要归档都在,可以随意指定抽取进程开始的时间或者跳过某些归档(特别是在归档文件不小心丢失的情况下),非常简单方便。比如:

直接到某次integrated capture进程重启后突然提示要一个非常陈旧的归档文件。抽取进程只是暂时了2个小时,这两天的归档全都在啊!尝试指定抽取进程的启动的时间点或者直接begin now都不成功,这意思很可能要重配抽取进程然后begin now,这套ogg还是非常重要的业务同步,丢失2个小时的同步数据,而且不知道是哪些表哪些数据丢了,惨了惨了脑袋缺氧。

轻轻走过,悄悄看过,无意瞥一眼惊鸿的颜色,随着巷口的老猫湮没在无声中,爱这巷,爱这楼阁,爱这轻缓的脚步,落在石板上的踢踏,喜欢看你的身影随我远去,目光牵着你的笑,飞洒的柳絮勾勒你的轮廓,在茫茫烟波中,你留下残红染了梅花,在渺渺云雾中。
在经典抽取中我们经常指定抽取进程启动的时间点或归档位置,只要归档文件都在就可以反复横跳。但这招在integrated capture就不灵了!
第一个缺点:直接alert extract XXXX begin now难了

翻译下就是即使alert IE抽取进程 begin now,抽取进程仍然需要这中间的所有日志文件来同步logminer dictionary。如果缺了中间的归档,唯一的办法是unregistered/registered + begin now,也就是重配抽取进程了。
想想begin now的场景往往就是抽取启动时报缺归档时应急处理的下策,现在这条路也走不通了。当然重建抽取进程当然效果也一样,但可麻烦很多。
再翻译下就是:以后IE抽取进程所需的归档丢了找不回,中间丢的数据真没了!IE抽取进程也绝对起不来了!重建抽取进程吧少年!

注意:虽然配置了integrated capture后ogg会自动管理归档文件,避免它被rman误删。但它可挡不住手动rm 或者“DELETE FORCE ARCHIVELOG...”。
第二个缺点:指定integrated capture从旧时间点开始抽取难了
像我前面遇到的问题,归档文件都在啊,在classic capture中我们完全可以重建抽取进程然后指定它从某个时间点开始抽取,数据完全不丢失。
对于integrated capture不是绝对不行,是非常难:
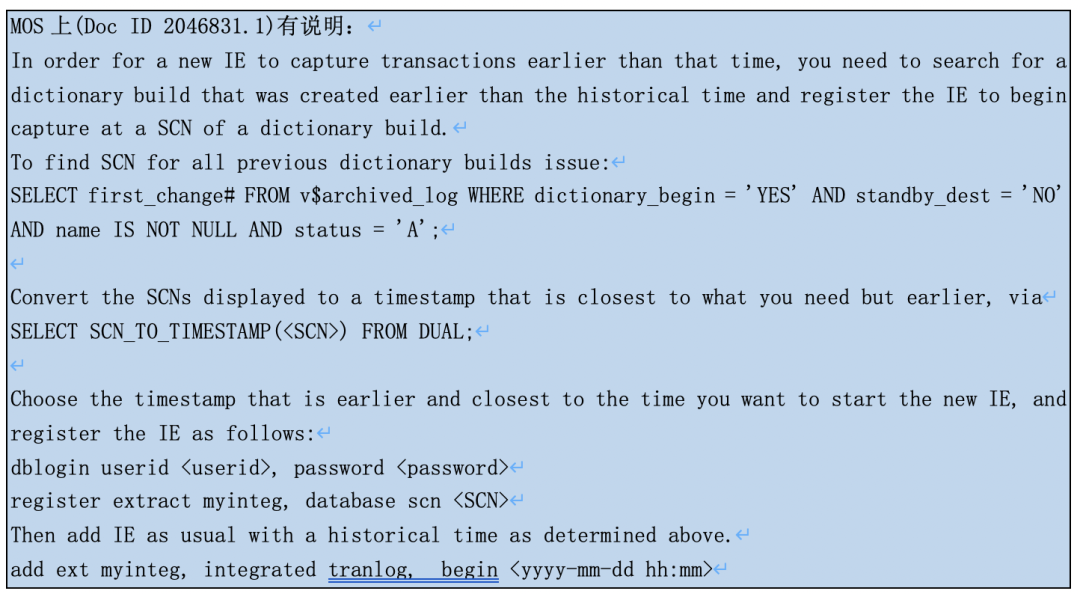
翻译下:要使用新加的IE进程抽取从一个旧的时间点A开始抽取,必须找到包含dictionary的日志文件(假定它的first_change#是时间点B),则A要晚于B,同时从这个日志文件开始所有日志文件必须都在。比如:
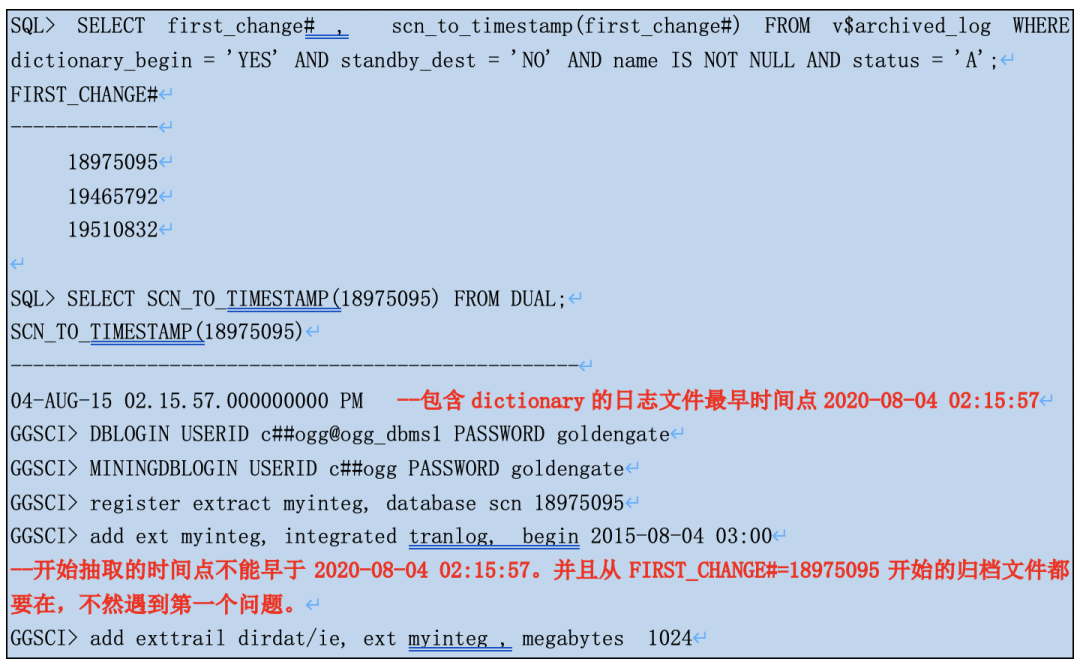
那包含有dictionary的日志文件哪来的?

翻译下:在做register extract时会将当时的dictionary刷到redo文件中,也可以手动刷新。
总结:如果平时不手动刷新dictionary到redo文件(一般人哪会干这事,估计也没人知道),要指定新建的或现有IE进程从一个过去的时间点开始,不能超过IE进程“register extract的时间点”,同时从“register extract的时间点”所有归档必须都在!

这两个MOS的解释让我产生了更多的疑问:
问题一:classic capture为什么不需要dictionary?
问题二:integrated capture平时启停为什么不需要dictionary(register extract时的归档文件早就删了)?
问题三:为什么指定integrated capture的位置/时间时就需要在这之前的dictionary?

在classic capture mode中,goldengate extract进程直接读取oracle redo log,捕获数据变化。默认redo条目是不记录表的数据字典信息的。
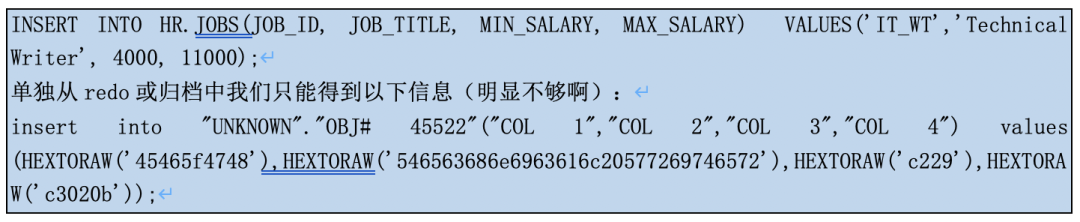
Extract进程检测到redo条目中存在受支持的操作(是否为要抽取的表名),由于redo中包含对象ID,而不是对象名称。首次遇到object_id时,Extract进程将针对数据字典发出一系列语句以找出其含义,将确定相应的对象名称和类型:

当然还有不仅以上一条sql。但对抽取进程来说,表名信息最重要,它不需要列的信息。列信息在复制进程解析trail文件时才需要,将通过使用目标数据库的数据字典(ASSUMETARGETDEFS)或指定定义文件(SOURCEDEFS)来获取。

classic capture与dictionary的关系:
1) Without DDL support configured, GoldenGate will always query online data dictionary and that doesn’t play well with object changes.
● 如果表当前时间已被delete,即使redo中此表的DML记录,抽取进程也不会抽取此表的数据,因为根据object_id已查不到表的信息(object_id也不会被重用)。
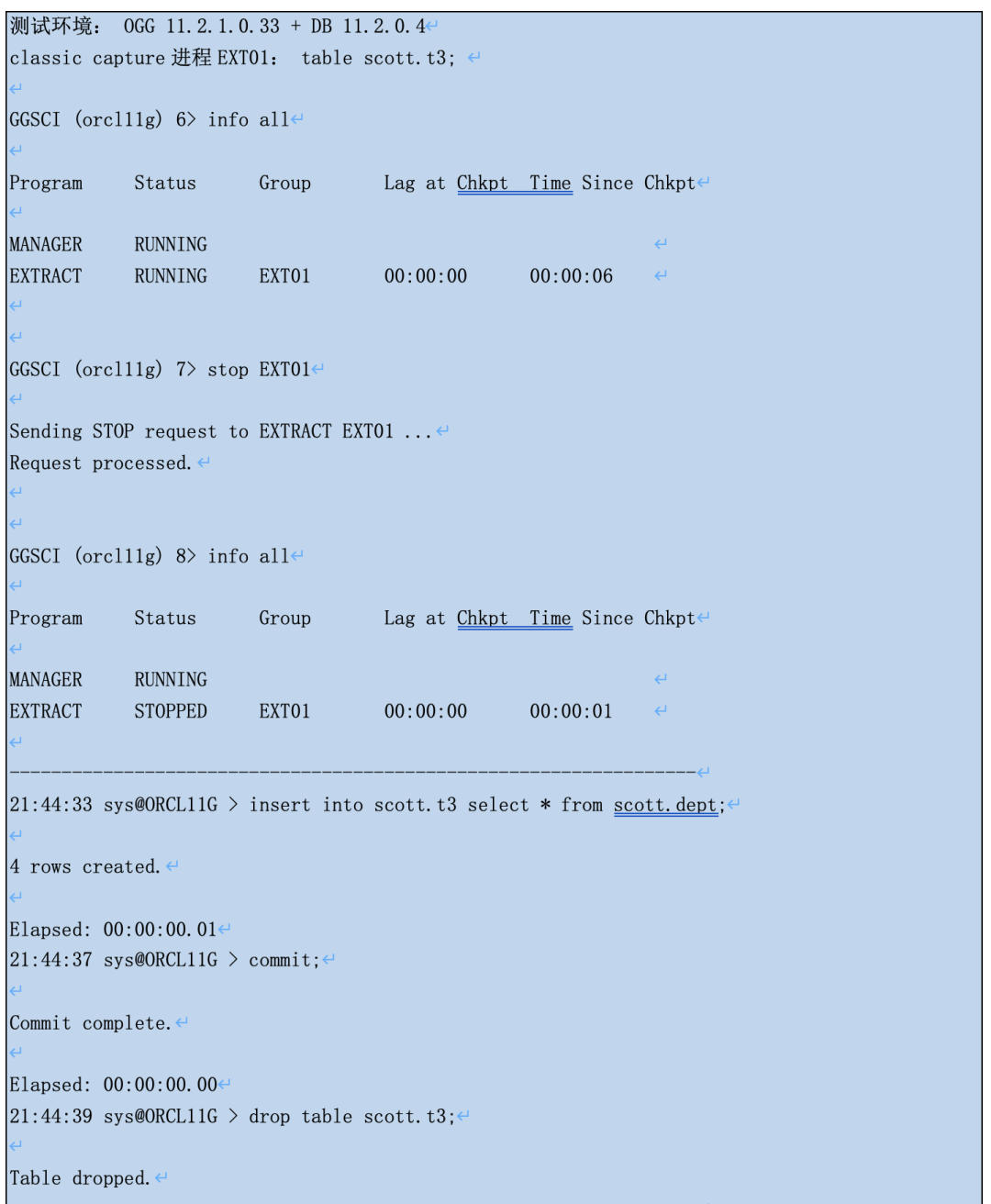
●如果表DML后删除了字段,表的DML记录会从redo中抽取,但由于抽取进程读取的online data dictionary不包括被删除的字段信息了,所以得到trail条目中会缺这个字段。
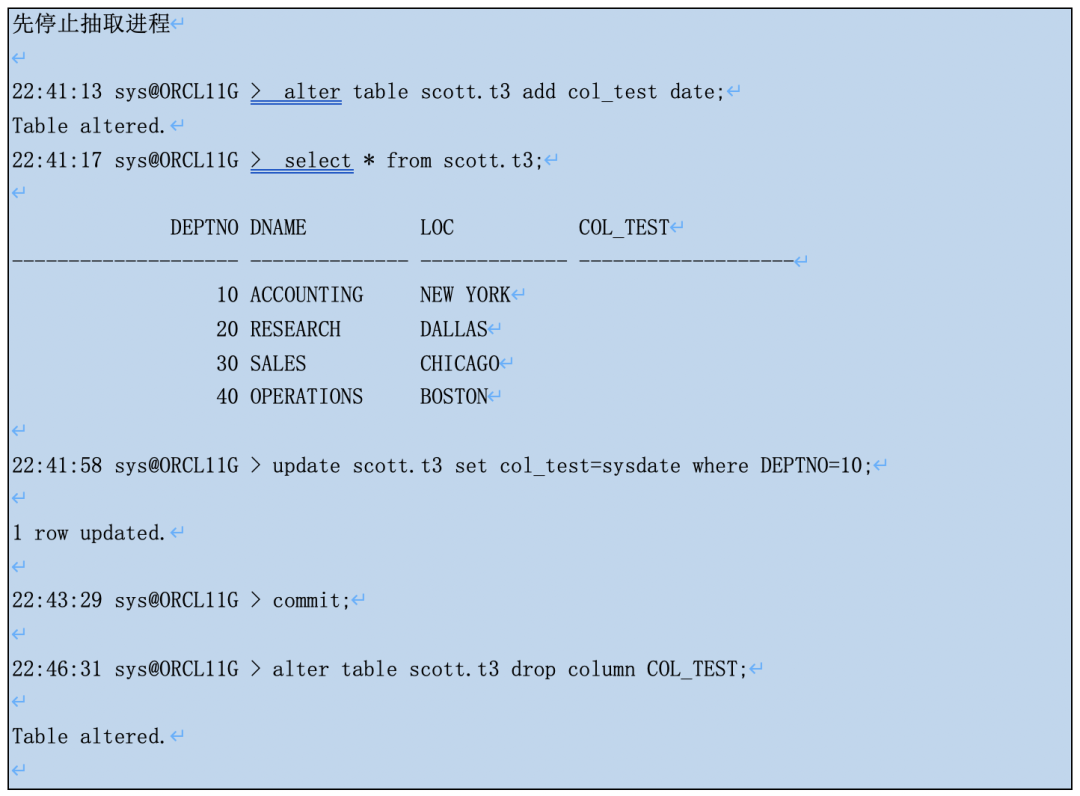
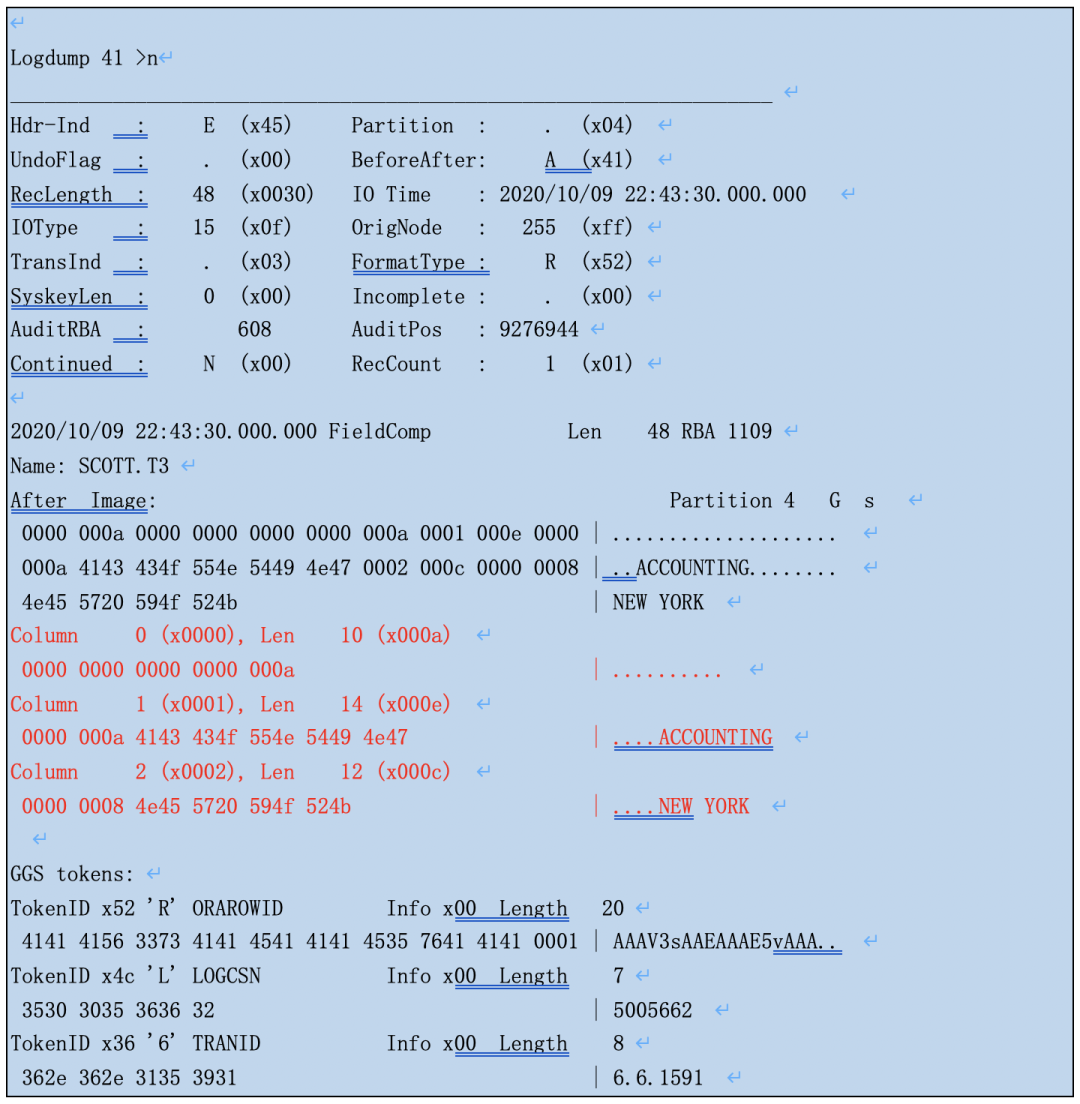
打开抽取进程同步,追平后再用logdump打个这个update记录。redo的原先告诉我们日志文件中肯定有COL_TEST字段的数据,可是trail条目并没有,只有前3个字段。
● 如果表DML后添加了字段,表的DML记录会从redo中抽取,但由于抽取进程读取的online data dictionary有了新的字段,所以得到trail条目中可能会有这个新增字段,只是数据是空。
● 经在OGG 11.2上实验测试,如果有配置DDL同步脚本并且在抽取进程中启用ddl同步,由于OGG的ddl触发器的存在,GGS_DDL_HIST等表一直自动更新,ogg
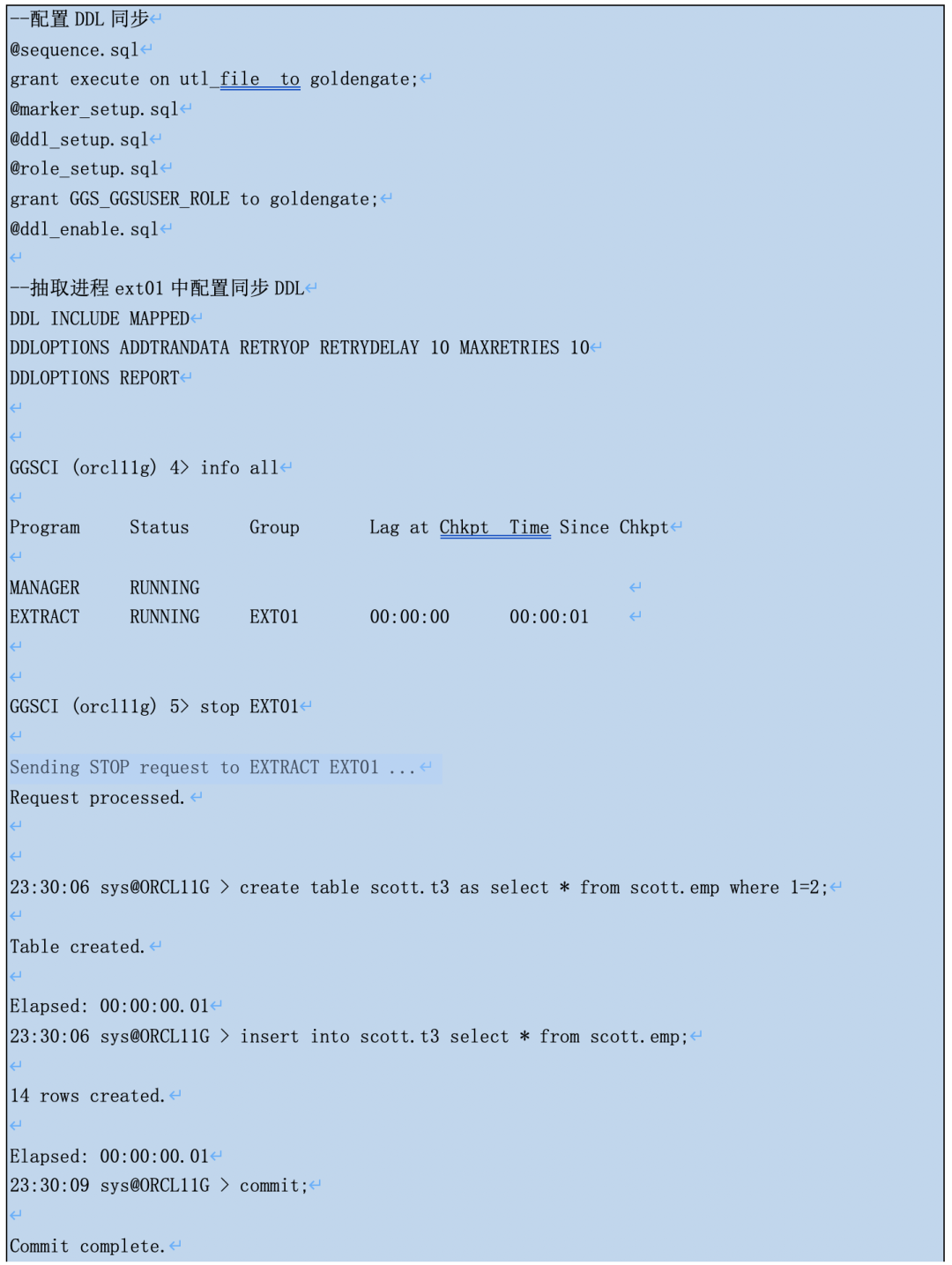

GOLDENGATE.GGS_DDL_HIST、GOLDENGATE.GGS_MARKER详细记录了DDL的sql和DDL前的表定义。
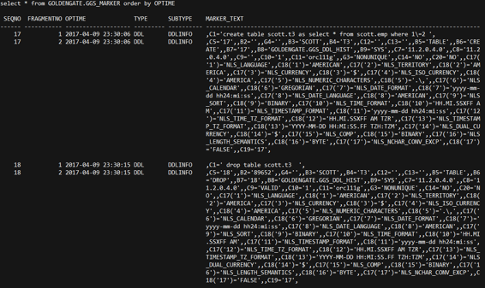
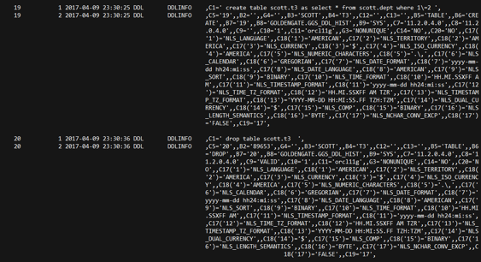

启动抽取进程后,可以看到进程完全地抽取了表的DDL和14+4行的insert操作。
● 经在OGG 11.2上实验测试,如果有配置DDL同步脚本但没有在抽取进程中启用ddl同步,ogg抽取效果跟前面没有配置DDL同步脚本一样。
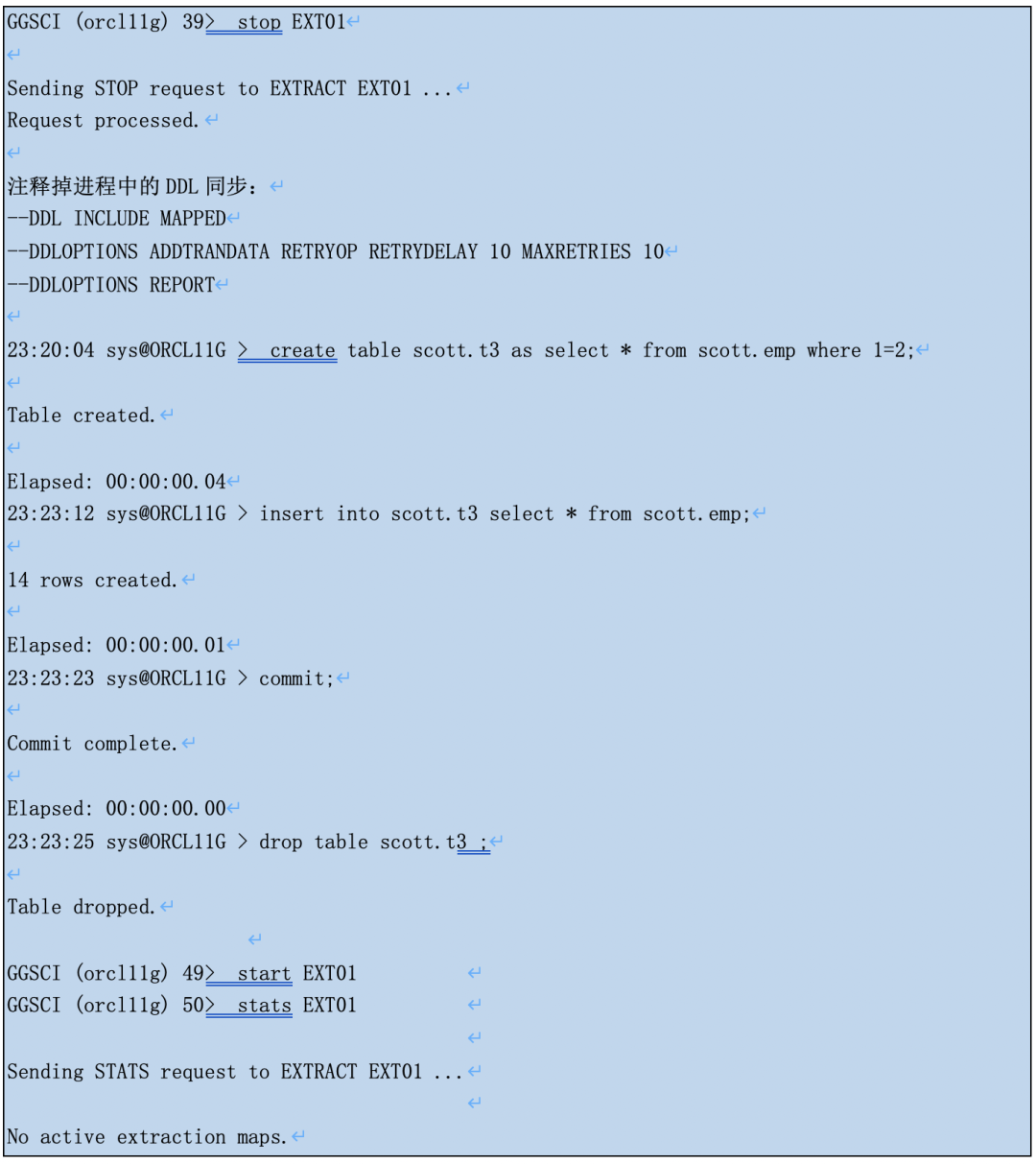
在integrated capture mode中,goldengate extract进程不再直接读取oracle redo log,而是通过与数据库stream技术整合,通过log mining server来捕获数据变化。
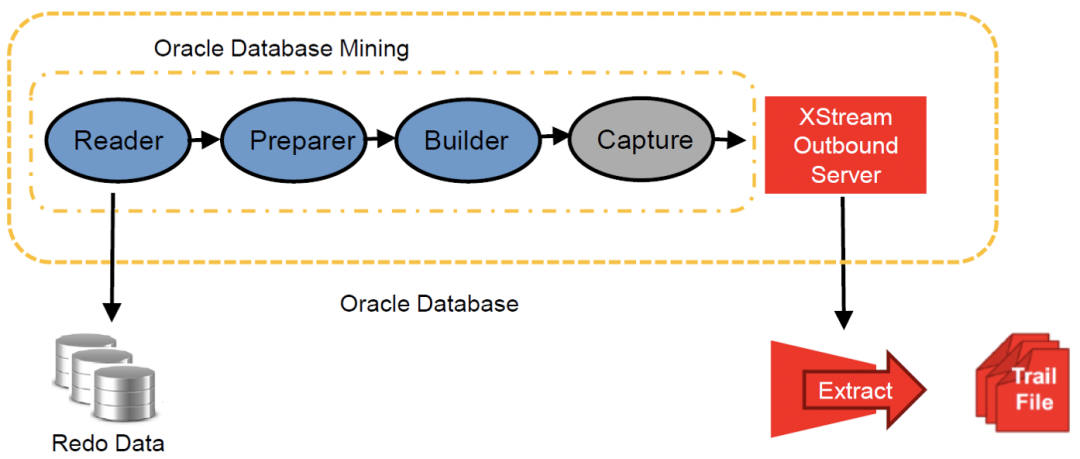
既然是logMiner,想想我们平时挖归档是怎么做的,是不是得有dictionary。
The LogMiner dictionary allows LogMiner to provide table and column names, instead of internal object IDs, when it presents the redo log data that you request.
LogMiner uses the dictionary to translate internal object identifiers and datatypes to object names and external data formats. Without a dictionary, LogMiner returns internal object IDs and presents data as binary data.
下面直接黏贴一段LogMiner字典的官方文档:
LogMiner字典有3种选项:
1) 使用源数据库数据字典(Online Catalog)
使用源数据库分析重做日志或归档日志时,如果要分析表的结构没有发生任何变化,Oracle建议使用该选项分析重做日志和归档日志。为了使LogMiner使用当前数据库的数据字典,启动LogMiner时应执行如下操作:
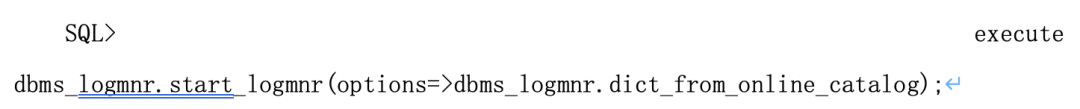
需要注意,dbms_logmnr.dict_from_online_catalog要求数据库必须处于open状态,并且该选项只能用于跟踪DML操作,而不能用于跟踪DDL操作。(本人一般用这种查DML操作)
如果dbms_logmnr.start_logmnr之前对象发生过DDL,则无法正常通过dict_from_online_catalog完整解析DDL之前的归档。
2) 摘取LogMiner字典到重做日志
使用分析数据库分析重做日志或归档日志,或者被分析表的结构发生改变时,Oracle建议使用该选项分析重做日志和归档日志。
为了摘取LogMiner字典到重做日志,要求源数据库必须处于archivelog模式,并且该数据库处于open状态。

跟前面MOS上(Doc ID 2046831.1)的说法是如此一致!!
3) 摘取LogMiner字典到字典文件
字典文件用于存放对象ID号和对象名信息,该选项是为了与早期版本兼容而保留的。需要注意,使用字典文件分析重做日志时,如果要分析新建的对象。必须重新建立字典文件。如下所示:

果然从归根到底这是一个stream技术问题!!

后面在mos上找到了一篇“Resolving the MISSING Streams Multi-version Data Dictionary Error (Doc ID 212044.1)”:

integrated capture与dictionary的关系:
integrated capture注册到数据库时会刷新current SCN下的所有数据字典到redo中,同时也记录到SYSTEM.LOGMNR%对象。
后面抽取进程会自动更新SYSTEM.LOGMNR%中的元数据变化,甚至记录个多个版本的元数据。这样多个extract进程即使有不同的延迟也能logminer不同时间点的归档。
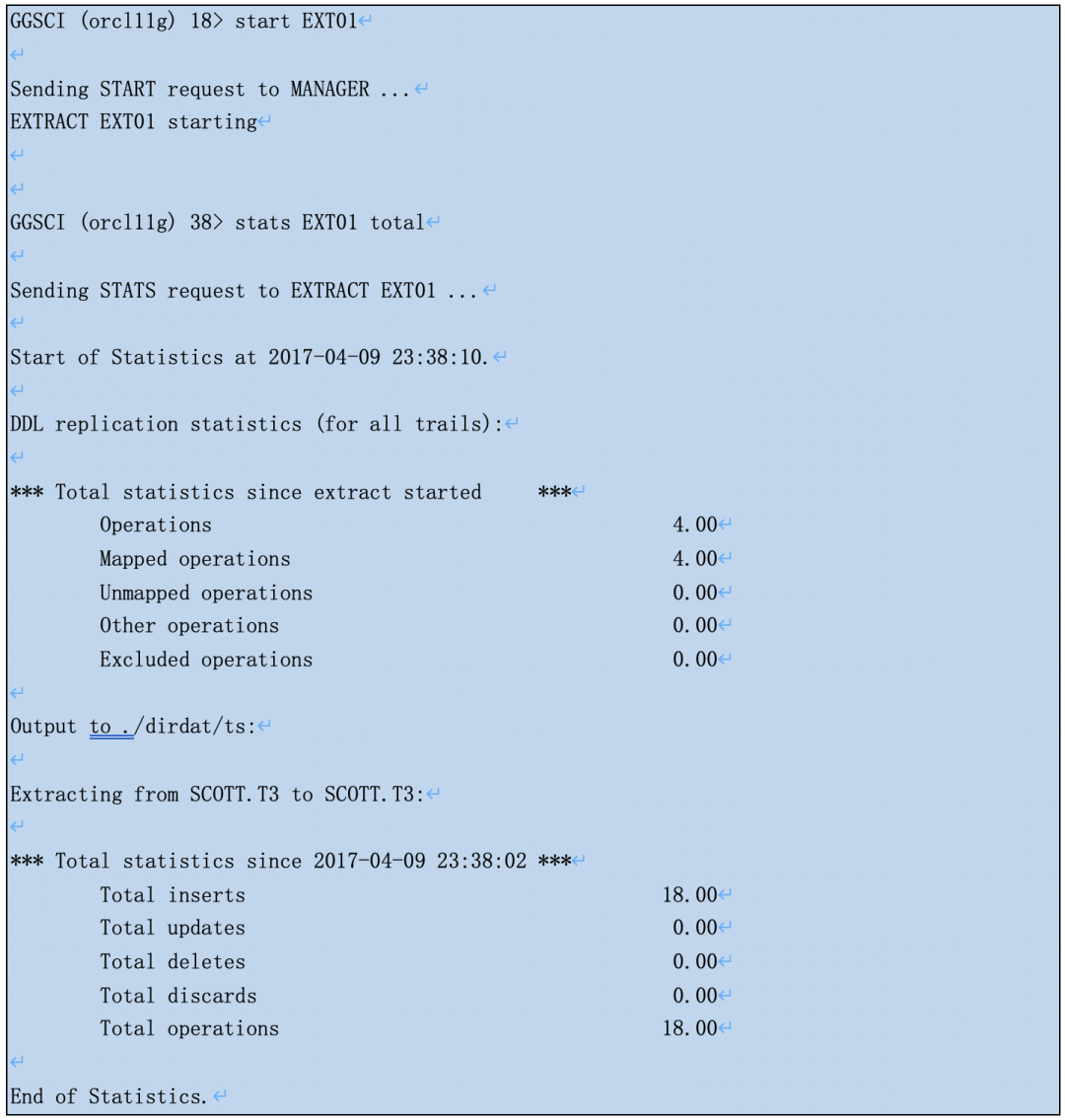
实验证明下:ogg和db版本不变,我们创建了IE进程ext02,抽取所有scott用户的表。

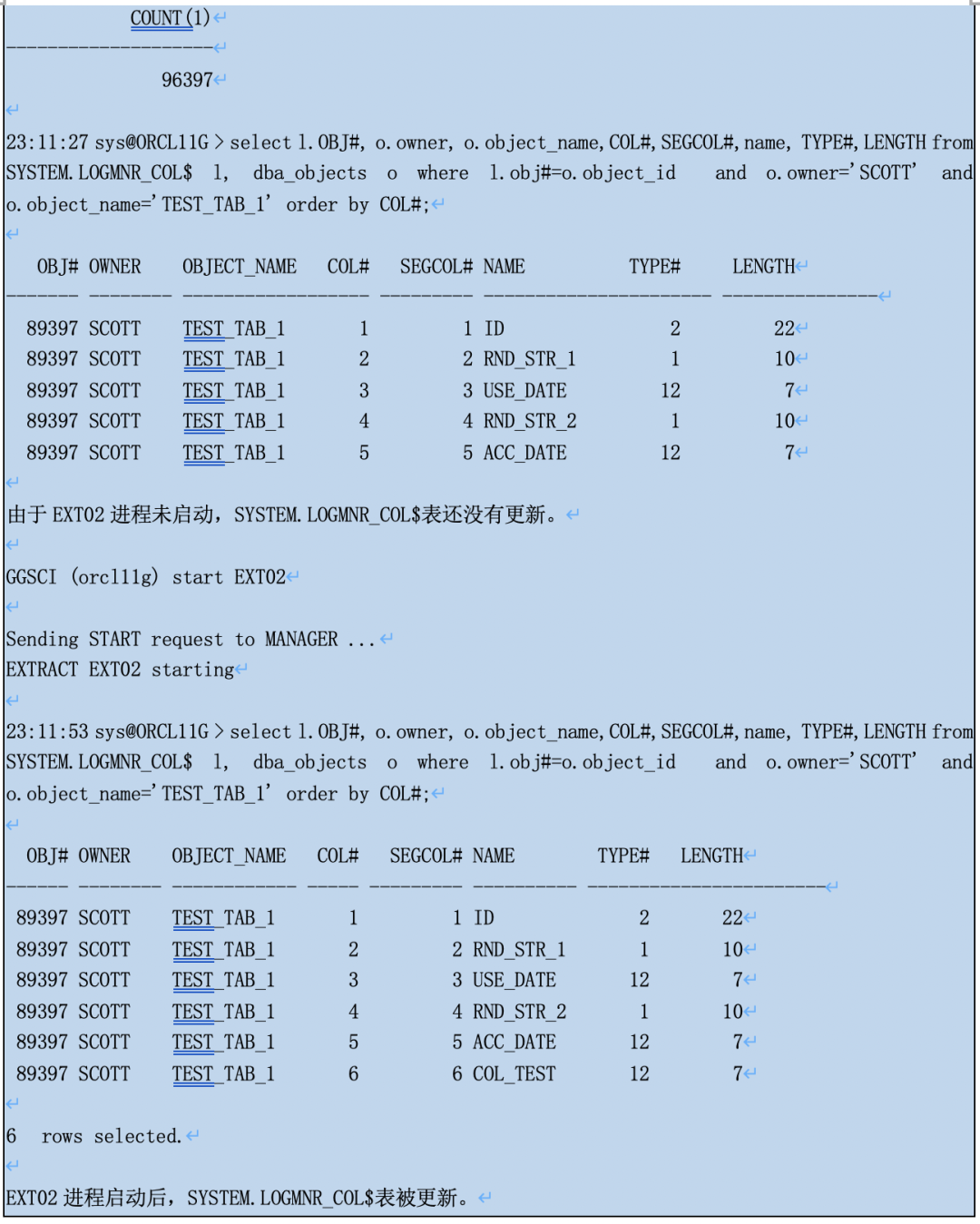
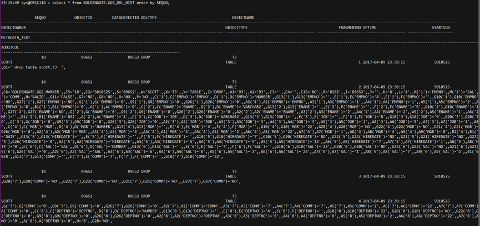
system.logmnrc_gtlo记录元数据有变化的表。

我们从system.logmnrc_gtcs可以看到表的多版本元数据详细信息(会清理过旧的版本的,还不知道清理的策略和原理)。
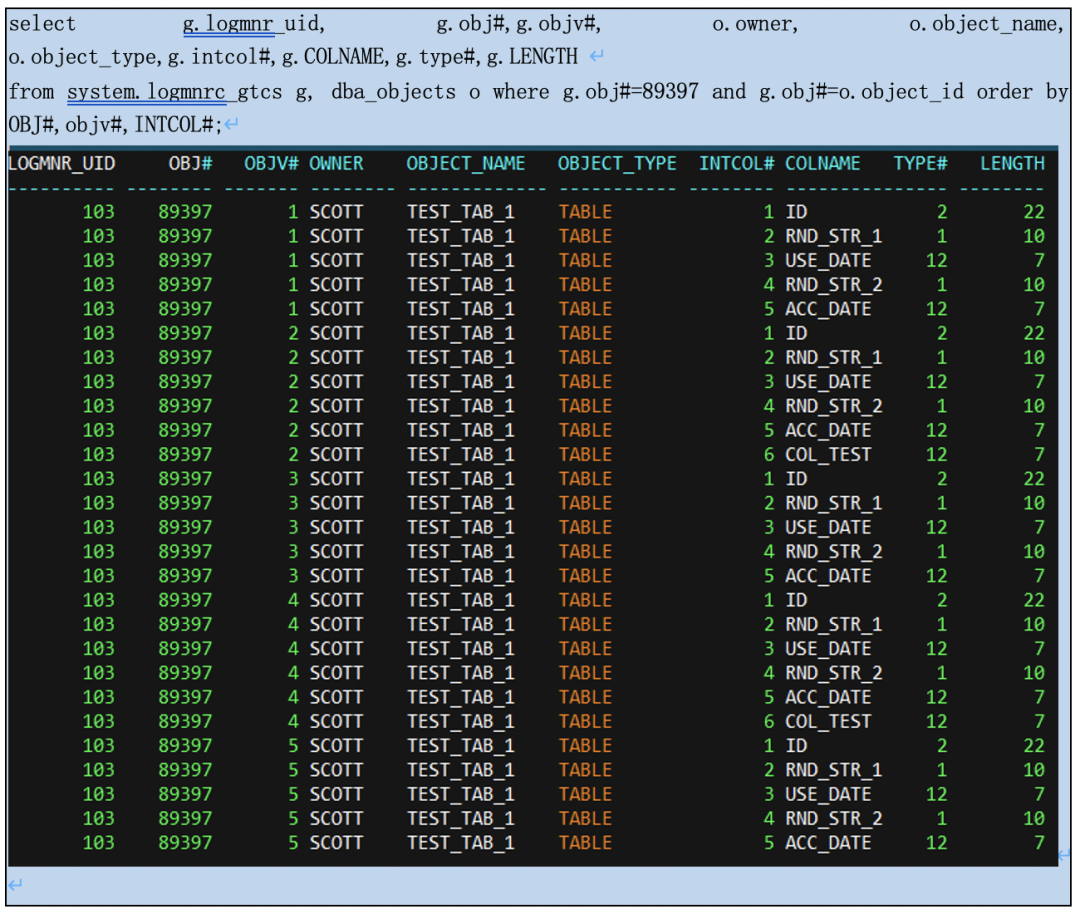
结合这些资料和实验,猜想如下:
所以不能指定integrated capture进程中途跳过某几个归档,因为这样元数据变化将无法持续跟踪和更新,无法保证元数据的准确性,logminer进程工作不了。
如果指定integrated capture进程到旧的SCN(大于register database时的SCN),由于SYSTEM.LOGMNR%对象(比如system.logmnrc_gtcs)很可能不会记录那么旧的多版本元数据,因此无法去做logminer; 如果指定integrated capture进程到更旧的SCN(小于register database时的SCN),此时SYSTEM.LOGMNR%对象根本没有,因此无法去做logminer。
后面这两种情况ogg将尝试查找你指定的SCN之前的归档中的数据字典(就是integrated capture注册时产生的),从当时的归档文件中重建SYSTEM.LOGMNR%对象,并一路跟踪下来。这样需要非常旧的归档文件及之后所有归档文件,一般早没了。
integrated capture
下数据字典的优化
根据前面的分析,我们知道integrated capture是无法跳过归档的了,中断一段时间再想begin now拉起来是没戏的。
但如果想指定到一个过去的时间点启动还是可以实现的。Resolving the MISSING Streams Multi-version Data Dictionary Error (Doc ID 212044.1)中推荐我们定期手动刷新Dictionary到日志文件中:

实际执行大概花费几分钟。如果是多租户架构需要所有pdb都是open的。
每天刷新一次加上合理的归档保留策略,至少能保证我们可以指定IE从过去的时间点启动。

问题一:classic capture为什么不需要dictionary?
答:
● 没有配置DDL同步脚本classic capture,直接使用online data dictionary来解析日志文件,如果表有过ddl,抽取可能不完善。
● 配置DDL同步脚本,但抽取进程中未启动同步DDL的classic capture,同上。
● 配置DDL同步脚本,同时在抽取进程中启动同步DDL的classic capture,会利用ddl触发器自动刷新的GOLDENGATE.GGS_DDL_HIST、GOLDENGATE.GGS_MARKER中记录的表元数据来解析日志文件,可以准确同步DDL和不同版本表元数据下的DML操作。
问题二:integrated capture平时启停为什么不需要dictionary(register extract时的归档文件早就删了)?
答:
register extract时会将整个库表的元数据刷新到日志文件,同时记录dictionary到SYSTEM.LOGMNR%表中。IE进程工作时会自动维护SYSTEM.LOGMNR%表中的元数据,利用Multi-Version Data Dictionary来正确抽取过去的日志数据。IE进程关闭了SYSTEM.LOGMNR%表的数据也还在。
问题三:为什么指定integrated capture的位置/时间时就需要在这之前的dictionary?
答:
指定位置或时间来启动IE进程,SYSTEM.LOGMNR%表记录的dictionary不可用了。此时ogg需要记录在日志文件中的dictionary来重构。因此需要register extract时的归档文件及之后的所有归档文件。定期刷新dictionary到日志文件会有帮助。

How to configure a new Integrated Extract to start at a historial old date and time. (Doc ID 2046831.1)
Integrated Extract Is Mining through Old Archive Logs Even When Altering to BEGIN NOW (Doc ID 1610114.1)
https://docs.oracle.com/cd/B19306_01/server.102/b14215/logminer.htm#i1015913
https://blog.pythian.com/oracle-goldengate-extract-internals-part-iii/
Resolving the MISSING Streams Multi-version Data Dictionary Error (Doc ID 212044.1)

本期作者|马育义 十年老DBA,精通Oracle数据库管理,精通OGG运维,喜欢各种数据库故障和救援处理。同时熟悉mysql、mongodb运维,喜欢钻研各类疑难杂症、技术新动向。持有oracle OCM,ogg OCP, mysql OCP, mongodb认证,AWS SAP认证,阿里云ACP认证等。
