






我们在数据库日常运维过程中,经常会使用数据泵(expdp\impdp)对数据库做导出导入操作,从而实现数据库的部分或全量数据迁移(如搭建测试库、迁移生产库、合并数据库等)。
然而在数据的导出导入过程中,我们会发现比较大的大字段表会很影响整个导出导入效率,甚至无法正常完成。普通表我们可以采取加并行参数(parallel)来提升导出导入效率,但此参数针对于大字段表是无效的,即使加了并行参数,大字段表还是单进程执行导出导入操作。

背 景
有套业务子库(大小大概2T)需要迁移合并至其业务主库,由于是合并操作,在排除使用ADG、XTTS、OGG等迁移方案之后,考虑采用数据泵导出导入的方式进行合并迁移。整个合并迁移时间(包括数据库迁移合并+业务测试)限制在7小时以内,数据库中大部分表通过并发导出导入等优化方式可以在5小时内完成,唯独有一张包含200多G大字段对象的表仅仅是导出花费十几个小时也未完成,直至报错(报快照过久)。通过扩展undo表空间及调整参数undo_retention,最终还是导出失败。
分析原因

LOB字段的表导出时即使加并行参数也是无效的,还是单进程在导出表数据,表本身包含220G数据,大字段数据就占202G,数据量比较大,加上源端服务器是普通的X86服务器,数据在导出过程中还会发生变化,最终由于耗时过久,导出失败。

解决问题
数据库总共有2T数据,其他1.8T数据通过开并行等手段基本可以在2小时之内导出完成,唯独此大字段表即使导出十几个小时也无法正常完成,所以首先我们要尝试解决并行的问题,通过一定的手段使大字段表的导出能够并发进行。
既然并行参数parallel对大字段表是无效的,在不改变表结构及数据的情况下,我们可以尝试将表从逻辑上拆分成一个一个的小单位,每个小单位拉起一个导出进程,这样就可实现大字段表的并行导出操作。
那如何逻辑拆分大字段表呢?如果表上有日期字段,我们可以按日期字段拆分表,再如表上有区域字段,我们也可以按区域字段做拆分,即使没有特别明显的可以区分数据的字段,我们也可以按rowid去做拆分。
其实按rowid去做拆分是一个很好的方式,因为oracle做数据插入时是无序插入的(同一时刻多个进程对同一张表做插入,数据可能存放在不同的数据块上,并不是一个数据块使用完之后,再插入新的数据块),但了解oracle存储结构的会知道,如果我们不管数据的组成,rowid(rowid是由对象编号+文件号+数据块编号+行号组成)其实是有序的,我们如果按rowid有序的去做拆分,就可以尽量少读数据块(相较于索引扫描及全表扫),从而提升整个导出效率。
首先我们创建一张中间表,将表数据的rowid按顺序记录下来(全表扫有序读取相邻的数据块),方便之后做拆分
create table t_test_split as select *+parallel(4)*/rowid sou_rowid,rownum rn,(select current_scn from v$database) scn from t_test;
注:虽然合并迁移过程中业务子库是停业务不再读写的,但为了保证数据的一致性,我们还是选择把数据库的scn号记录下来。例如在数据库不停机的情况下,你在搭建OGG环境初始化大字段表时,这里保存的scn号就非常有用了。
源库拉起导出主进程,通过rowid将表拆分成一个一个的小单元,每个小单元拉起一个独立子进程单独导出一部分表数据,子进程导出完成生成一个标记文件用来标记子进程已导出完成。目标库拉起导入的主进程,监控导出的标记文件,一旦发现导出完成的子进程标记文件就开始执行导入,一直到源库小单元全部导出完成为止。
注:由于案例中的环境在源库和目标库之间设置了nfs共享目录,所以无需scp网络传输导出的数据文件及标记文件。
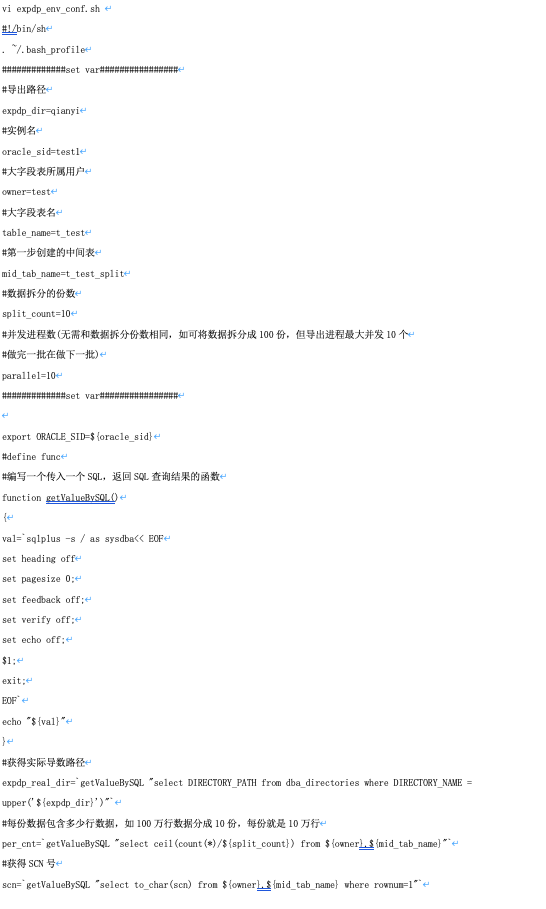


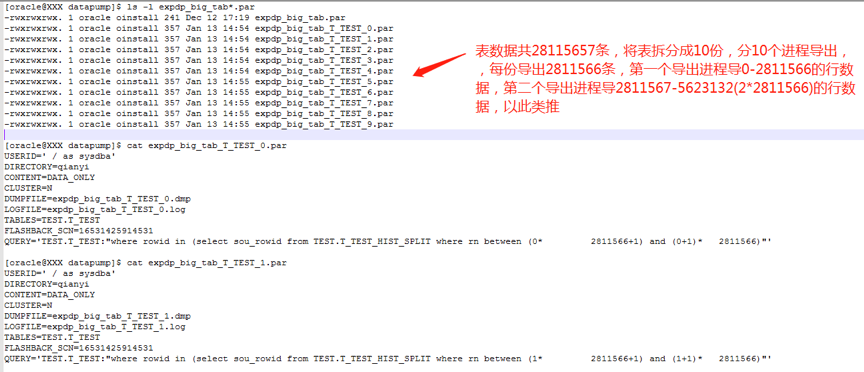
生成的导数文件如下图:

nohup sh expdp_lob_tab.sh>expdp_lob_tab.sh.out &

我们编写导入大字段表的主体shell脚本,和导出主shell基本类似

编写导入大字段表的子shell脚本

nohup sh impdp_big_tab.sh>impdp_big_tab.sh.out &

成 效
原本十几个小时(可能不只这么久,因为十几个小时之后导出报错)无法导出的大字段表,最终两个多小时就导出完成。加上导入时间最终可将整个导出导入时间控制在5小时以内,满足迁移合并时间要求。


总 结
我们在对大字段表用数据泵做导出导入时,由于并行参数对其无效,如果发现导出导入效率无法满足要求,可尝试人工将表逻辑拆分成小单元,每个小单元独立导出一部分数据,以此来提升导出导入效率。

评论

 0 点赞
0 点赞