




一、虚拟机与容器
-
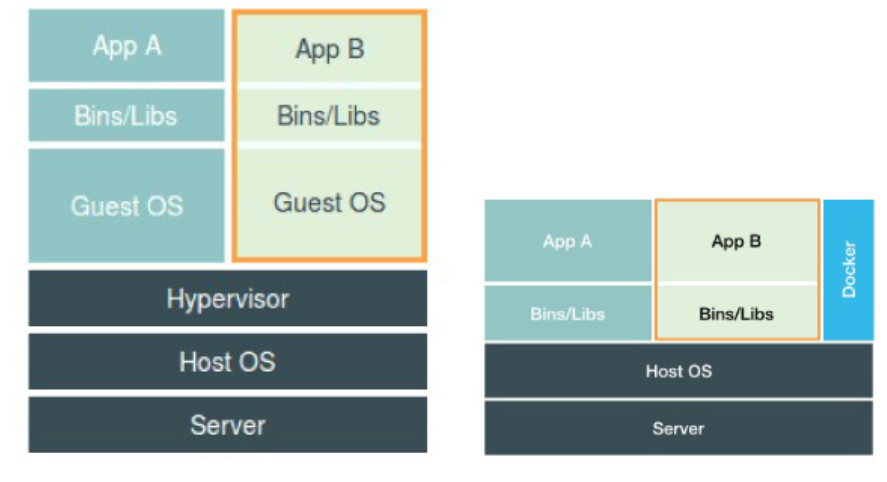
虚拟机
使用虚拟化技术作为应用沙盒,就必须要由 Hypervisor 来负责创建虚拟机,这个虚拟机是真实存在的,并且它里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。 -
容器
用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。
与虚拟机相比,容器化后的用户应用,却依然还是一个宿主机上的普通进程,这就意味着这些因为虚拟化而带来的性能损耗都是不存在的;而另一方面,使用 Namespace 作为隔离手段的容器并不需要单独的 Guest OS,这就使得容器额外的资源占用几乎可以忽略不计。
所以说,“敏捷”和“高性能”是容器相较于虚拟机最大的优势。
不过,有利就有弊,基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
二、隔离(Namespace)
2.1、Namespace类型
常见Namespace类型:
Linux 操作系统还提供了多种类型的Namespace: Mount、UTS、IPC、Network 和 User 。这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
| Namespaces | 作用 |
|---|---|
| PID Namespace | 隔离进程 |
| Mount Namespace | 隔离文件系统,用于让被隔离进程只看到当前 Namespace 里的挂载点信息 |
| Network Namespace | 隔离网络,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。 |
-
PID Namespace
在容器技术原理: Linux 容器最基本的实现原理中讲到:我们在linux系统中运行一个进程,那么他的进程号PID=100,运行下一个进程则是PID=101,那么在101号进程创建时,给他施一个“障眼法”,让他以为他是第一号(PID=1),他永远看不到前100号进程,那么他永远是PID=1,这个就是PID Namespace的作用 -
Mount Namespace
在容器技术原理:文件系统中讲到:Mount Namespace负责让被隔离的进程只能看到当前Namespace里挂载目录的文件,并且可以重新挂载指定目录,让挂载的宿主机目录在容器中是空的目录。避免在容器中访问到宿主机的文件。 -
Network Namespace
在容器技术原理:网络中讲到:新创建的 namespace 默认不能和主机网络,以及其他 namespace 通信。Network Namespace是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。
2.2、隔离的局限性
首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
尽管,你在Linux的宿主机上,通过 Mount Namespace 单独挂载其他不同版本的操作系统文件,比如 CentOS 或者 Ubuntu,形成与宿主机不同的操作系统,但是,这并不能改变共享宿主机内核的事实。
比如:我们在x86的服务器上,制作了一个镜像,拿到arm的服务器上去运行,是无法运行的。
而相比之下,拥有硬件虚拟化技术和独立 Guest OS 的虚拟机就要方便得多了。无论你是在linux系统中启动虚拟机还是windows中启动的,迁移是没有影响的。
其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
这就意味着,如果你的容器中的程序使用 settimeofday(2) 系统调用修改了时间,整个宿主机的时间都会被随之修改,这显然不符合用户的预期。相比于在虚拟机里面可以随便折腾的自由度,在容器里部署应用的时候,“什么能做,什么不能做”,就是用户必须考虑的一个问题。
由于上述问题,尤其是共享宿主机内核的事实,容器给应用暴露出来的攻击面是相当大的,应用“越狱”的难度自然也比虚拟机低得多。
更为棘手的是,尽管在实践中我们确实可以使用 Seccomp 等技术,对容器内部发起的所有系统调用进行过滤和甄别来进行安全加固,但这种方法因为多了一层对系统调用的过滤,必然会拖累容器的性能。何况,默认情况下,谁也不知道到底该开启哪些系统调用,禁止哪些系统调用。
所以,在生产环境中,没有人敢把运行在物理机上的 Linux 容器直接暴露到公网上。
三、限制(Cgroups)
3.1、为何做资源限制?
我们从上面知道,虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
3.2、Linux如何做资源限制?
Linux Cgroups 的全称 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
我们可以用命令查看
$ mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
3.3、Linux进程资源限制演示
(1)我们在后台执行这样一条脚本:
# 循环,让CPU达到100%
$ while : ; do : ; done &
# 进程号是226
[1] 226
(2)查看cpu占用:CPU 的使用率已经 100% 了
$ top %Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
(3)我们可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us -1 $ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us 100000
(4)向 container 组里的 cfs_quota 文件写入 20 ms(每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
(5)我们把被限制的进程的 PID 写入 container 组里的 tasks 文件:
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
(6)查看
$ top %Cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
可以看到,计算机的 CPU 使用率立刻降到了 20%(%Cpu0 : 20.3 us)。
四、总结
【Namespace】 的作用是“隔离”,它让应用进程只能看到该 Namespace 内的“世界”;
【Cgroups】 的作用是“限制”,它给这个“世界”围上了一圈看不见的墙。
这么一折腾,进程就真的被“装”在了一个与世隔绝的房间里。
