




$oerr ora 65096 查看ORA错误的解释
12C
Create user c##kamus identified by oracle default tablespace users;复制
创建LOCAL USER需要登录PDB
Show con_nameSelect sys_context(‘USERENV’,’CON_NAME’) FROM DUAL;ALTER PLUGGABLE database open;Select name,open_mode,restricted,open_time from v$pdbs;Select con_id,count(*) from cdb_users group by con_id;复制
xtts
停服务与修改JOB参数
Alter system set job_queue_processes=0;
新库:打开JOB
Alter system set job_queue_processes=1000;
停监听
Srvctl stop listener –l listener
Srvctl stop listener –l listener_scan1
查杀活动进程
查杀进程,确认无活动事务与死事务,包含分布式事务
Ps –ef|grep LOCAL=NO|grep –v grep |awk ‘{print $2}’|xargs kill -9
Select local_tran_id,state from dba_2pc_pending;
KILL JOB进程
12C新特性:
Identity类型
Create table t1(id number generated by default on null as identity);
Insert into t3 values(null);
Select * from user_sequences;
Identity 类型仍然是通过sequence 来实现的,默认创建的sequence,cache_size 是20,开始值是1.
10046事件
Select value from v$diag_info where name=’Default trace file’;Select sid,serial#,username from v$session where username is not null;Select index_name,table_name,column_name from user_ind_columns where table_name=upper(‘’);Alter session set events ‘10046 trace name context forever,level 12’; 启用跟踪;Alter session set events ‘10046 trace name context off’;停止跟踪。复制
对其他用户session设置事件跟踪,同样可以通过DBMS_SYSTEM的set_ev过程来实现。
Sql>exec dbms_system.set_ev(sid,serial#,10046,8,’’);
执行跟踪
Sql>exec dbms_system.set_ev(sid,serial#,10046,0,’’);
结束跟踪
在12C的多租户环境,修改service_names 参数应该非常谨慎。对于该参数的修改会直接反映到监听器的动态注册,甚至会覆盖PDB的动态注册,影响服务。
Alter system set service_names=’ye,ye2,enmo’;
迁移检查:
1.数据库时区检查,保持源库和目标库字符集一致性。
Select dbtimezone from dual;
2.数据库字符集检查,保持原库和目标库字符集一致性
Select * from nls_database_parameters where parameter like ‘%CHARACTERSET%’;
3.数据库目标端补丁情况检查。
目标端psu根据数据库安装配置最佳实践规范配置安装最新PSU
Select ‘opatch’,comments from dba_registry_history;
4.检查目标库端数据组件安装情况,需包含且多于原库组件
5.检查是否使用率key compression 的索引组织表
Select index_name,table_name from dba_indexes where compression=’ENABLED’;
Select owner,table_name from dba_tables where iot_type is not null;
6.检查源端数据文件,表空间异常情况
Select name from v$datafile where instr(name,’ ‘)>0;
如果存在空格或换行符数据文件,需要将该数据文件rename,否则在传输过程中会报错终止。如果存在同名表空间,而且该表空间中的对象需要传输,建议将目标端中的表空间rename,以避免冲突。
7.检查相同表空间下是否存在不同目录下的同名数据文件
Select substr(file_name,-6,2) from dba_data_files where tablespace_name=’TBS_NAME’ order by 1;
8.检查表空间自包含
只检查业务表空间的自包含情况
SQL>execute dbms_tts.transport_set_check(TBS_NAME,TRUE);
Select * from sys.transport_set_violations;
9.检查源端compatible参数
源端不可以是WINDOWS,源端的compatible.rdbms必须大于10.2.0,且不大于目标端compatible.rdbms
Show parameter compatible
如果目标端数据库版本是11.2.0.3或更低。那么需要在目标端安装11.2.0.4并创建实例,然后用来进行备份集转换。如果11.2.0.4中转实例使用ASM,那么ASM版本也必须是11.2.0.4,否则报错ORA-15295.
10.启用block change tracking(块跟踪)功能
11.11.2.0.4之前需安装补丁BUG16850197,注意块跟踪设置的目录大小,避免因块跟踪目录满而导致源数据库HANG。
12.检查目标端的db_files参数
在元数据导入阶段,如果目标端的db_files参数小于源端的db_files参数,会导致元数据因无法关联创建数据文件而导入出错,所以要确保目标端参数大于或等于源端。
Show parameter db_files
Oracle的参数和参数文件
1.推倒参数
通常来自于其他参数的运算,依赖其他参数得出,这类参数通常不需要修改
比如session参数,在ORACLE12C中,session=(1.5*processes)+22
Select name,value from v$parameter where name in (‘processes’,’sessions’);
2.系统依赖参数
Sga_target
/dev/shm 需要特别注意的是,如果有多个实例,那么其大小要大于所有实例所需要内存的总和。
3.可变参数
4.不推荐参数
Select name from v$parameter where isdeprecated=’TRUE’;
5.废弃参数
Select * from v$obsolete_parameter;
12c create spfile 的警示
验证环境RAC 12.1.0.2.0 先记录当前DB的资源配置
Srvctl config database –db rac12
RAC环境,一般推荐使用共享的SPFILE。
通过测试可见每次生成SPFILE,都同时更新了DATABASE资源配置里面的SPFILE设定。
SQL>!srvctl config database –db rac12|grep –i ‘spfile’;
Select instance_name,name,value from gv$parameter gp,gv$instance gi
Where gp.inst_id=gi.inst_id and gp.name=’spfile’;
补丁:BUG18799993
打上补丁之后,create spfile from pfile 命令只有在指定生成文件路径才会更新database资源配置,create spfile from memory 不再更新database资源配置。
From memory不支持as copy 选项,同时加了as copy选项后,即使指定了spfile生成文件路径,也不再更新database资源配置。
Create spfile from pfile=’’ as copy;
参数表的引入:
12c中的参数文件是针对CDB的设置。对于PDB的参数设置不记录在SPFILE文件
那么对于PDB的参数的修改记录在何处呢?通过跟踪过程,可以解析12C中的这个变化。
Show con_nameOradebug setmypidOradebug event 10046 trace name context forever,level 12Oradebug tracefile_nameAlter system set open_cursors=888;Oradebug event 10046 trace name context offAlter session set container=cdb$root;Select db_uniq_name,name,value$ from pdb_spfile$;复制
参数表
恢复某个参数的默认值
Alter system reset open_cursors scope=spfile sid=’*’;复制
解决参数文件的修改错误
实例级别的参数级别高于数据库层面的参数,即只有当实例级别未做设置时,在数据库级别的同一参数才会生效。
级别相同,那么后面出现的参数生效。
可以编辑一个参数文件,如:
Cat initeygle.ora
Spfile=’/…/dbs/spfileeygle.ora’
Sga_max_size=10737 这个参数是之前设置错误了的参数
第一行指向SPFILE,第二行写上出错的参数,给一个正确的值。这个值在实例启动时会覆盖之前错误的设置,然后就可以使用这个文件启动数据库实例了。
SQL>startup pfile=$ORACLE_HOME/dbs/initeygle.ora
参数生效级别:
1.session级别:v$parameter(show parameter),gv$parameter,v$parameter2,gv$parameter2
2.system级别:v$system_parameter,v$system_parameter,v$system_parameter4,gv$system_parameter,gv$system_parameter2,gv$system_parameter4(记录的是当前数据库级别所有用户设置的初始化参数,create pfile/spfile from memory )
System 级别即当前实例生效的参数。
3.重启生效参数视图:
V$spparameter 和gv$spparameter
如果在spfile文件中没有设置参数,则字段ISSPECIFIED对应的值为FALSE
参数值的可选项
Select * from v$parameter_valid_values where name like ‘%cursor%’;
获取系统的启动初始化参数应该从v$system_parameter, 列isdefault 表示当前设置的值是否是数据库的默认值。
Select name,value,isdefault from v$system_parameter where name=’open_cursors’;复制
RAC的各个节点可以使用统一的SPFILE启动,也可以选择不同的SPFILE进行启动。这时GV$SPPARAMETER视图获取的结果才是各个实例SPFILE中设置的结果。
两个实例上正真的参数设置查询方式:
Select inst_id,sid,name,value from gv$spparameterWhere name=’open_cursors’ and substr(sid,-1)=to_char(inst_id);复制
RAC下参数的维护
建议Rac下共享SPFILE,并在默认位置保留一个PFILE,里面通过SPFILE参数指向共享的SPFILE,
More initracdb1.ora
Spfile=’+data2/racdb/spfileracdb.ora’
在RAC环境中,需要谨慎使用create spfile from pfile
如何将参数文件转移到ASM存储并使之生效
首先检查参数文件的位置,并通过SPFILE创建一个PFILE文件,进而在ASM磁盘上创建SPFILE文件。
Show paramere spfile;Create pfile from spfile;Create spfile=’+db’ from pfile=’…dbs/initracdb11.ora’;复制
同步RAC2个节点的参数文件,更改其内容,设置SPFILE参数指向ASM中的参数文件。
$echo “spfile=’+db/racdb1/spfileracdb1.ora’” >’../dbs/initracdb11.ora’;
$ssh rac2 “echo \”spfile=’+db/racdb1/spfileracdb1.ora’\” >…/dbs/initracdb2.ora”
通过srvctl修改ocr中关于参数文件的配置。
oracle$srvctl modify database –d racdb1 –p +db/racdb1/spfileracdb1.ora
现在通过CRS启动数据库,将不再需要DBS目录下的参数文件。可以将其移除。
谨慎修改RAC参数
在ORACLE10.1版本中,alter system set undo_retention=18000 sid=’*’; 这条命令直接导致了RAC的其他节点挂起。
当时解决方法是sid=’RAC1’
参数文件的备份:
Rman targetShow allSelect * from v$rman_configuration;Rman>configure controlfile autobackup on;Configure controlfile autobackup format for device type disk to ‘/backup/control_%F’;复制
检查自动备份
Select * from v$backup_spfile;
List backup of spfile;
参数文件恢复
RMAN>restore spfile to ‘/tmp/spfile_bak.ora’ from auto backup;
ASMCMD>spbackup +data/asm/asmparameterfile/registry…. +data/spfilebackasm.bak
……………………………………………………………………………..+FRA/……………
新增的命令还有spcopy,spmove
NULL
B树索引不存储索引列全为空的记录,如果是单列索引,就是B树索引不存储NULL.
而BITMAP索引是存储NULL值的。
Count可以计算包含NULL记录在内的记录总数。
关于RAC数据库load balance 案例分析
检查服务状态
Select name,goal,clb_goal from dba_services;
检查service metric数据
Select inst_id,service_name,goodness,delta from gv$servicemetric where service_name=’resrac’;
Goodness 值应该和连接数匹配。否则有问题。Goodness值有如下两个特点
GOODNESS值在service的clb_goal 为clb_goal_long时表示实例中该服务的会话连接数。此值越大,连接越多,那么连接时就不会连接到GOODNESS值大的实例上,而是连接到值小的实例上。
Goodness值由MMON进程进行计算,然后定期由PMON发布给监听。
检查MMON进程有没有异常
$truss –p 1467404 (AIX)
Lsnrctl services LISTENER_SCAN1
Lsnrctl services LISTENER
Show parameter listener
Remote server信息实际上是PMON进程将LOCAL LISTENER的信息告诉SCAN监听
1.客户端连接到SCAN监听
2.SCAN监听根据客户端连接时指定的条件(SERVICE_NAME)选择一个实例。
3.SCAN监听把选定的实例的信息,包括地址,端口,协议,实例名发给客户端
4.客户端根据这个信息,重新发起一次网络连接,这次连接到实例的VIP监听上,VIP监听的服务是LOCAL SERVER,所以它会建立真正的连接
5.接下来就是登录验证
这个过程有2个关键点
1.上面第2步的实例选择中,监听是根据从PMON得到的实例的负载信息来选择实例的,这一步实现了负载均衡。
2.如果local listener参数设置不对(正常情况下,11g不需要显示设置,由GRID设置好就行),那么将不能连接,会报错。这个参数正常指向VIP地址,如果设置为主机名或域名,但是客户端不能解析,就连接不上。
如果网络是通过NAT或映射其他IP,则使用客户端负载均衡,直接连接VIP地址是更好的选择。
查看ASH数据
Col program for a40Select to_char(sample_time,’yyyy-mm-dd hh24:mi:ss’) sample_time,session_id,event,program,blocking_sessionFrom dba_hist_active_sess_history where sample_time>=sysdate-3And instance_number=2 and dbid=…And sample_id=….Order by sample_time,session_id;Select to_char(sample_time,’yyyy-mm-dd hh24:mi:ss’) sample_time,session_id,event,program,blocking_sessionFrom dba_hist_active_sess_history where sample_time>=sysdate-3And instance_number=2 and dbid=…And sample_id=…Order by sample_time,session_id;复制
检查SQL执行历史数据
Select sample_id,to_char(min(sample_time),’yyyy-mm-dd hh24:mi:ss’) sample_time,instance_number,qc_session_id,event,count(*)From dba_hist_active_sess_history aWhere a.sample_time>=to_date(‘2014-10-05 09:00’,’yyyy-mm-dd hh24:mi:ss’) and sql_id=’’Group by sample_id,event,instance_number,qc_session_idOrder by 1;复制
查看等待事件的原因
Select sql_id,count(*)From dba_hist_active_sess_historyWhere sample_time>to_date(‘20200624 10’,’yyyymmdd hh24’)And sample_time<to_date(‘20200624 11’,’yyyymmdd hh24’)And wait_class<>’Idle’And event=’buffer busy waits’Group by sql_id;继续查,buffer busy waits 的阻塞者Select sql_id,sql_exec_id,blocking_sessionFrom dba_hist_active_sess_historyWhere sample_time>to_date(‘20200624 10’,’yyyymmdd hh24’)And sample_time<to_date…..< span=""></to_date…..<>And wait_class<>’Idle’And event-‘buffer busy waits’;Select event,count(*)From dba….Where session_id in ()And sample_time>And sample_time<< span="">Group by event order by 2;复制
日志切换频率
Select b.sequence#,b.first_time,a.sequence#,a.first_time,round(((a.first_time-b.first_time)*24)*60,2)From v$log_history a,v$log_history bWhere a.sequence#=b.sequence#+1And a.first_time>to_date…And a.first_time<to_date…< span=""></to_date…<>Order by a.sequence#;复制
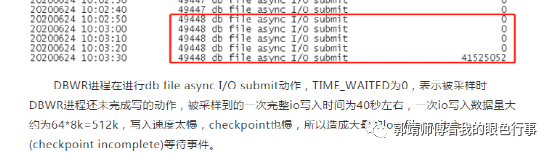
查看与DBWR进程相关的等待事件
Select to_char(sample_time,’yyyymmdd hh24:mi:ss’),seq#,event,time_waited,p1,p2,p3 from dba_hist_active_sess_historyWhere sample_time>to_date…And sample_time<< span="">And program like ‘%DBW%’And snap_id>=6069And snap_id<=6070< span="">And dbid=….Order by 1;复制
释放内存导致数据库崩溃的案例
Cat /proc/sys/vm/drop_caches 值为3时,会触发LINUX的内存清理回收机制,可能出现内存错误的情况。一般为0
对于LINUX的文件系统缓存,可通过调整操作系统内核参数来加快回收的,并不需要使用前面提到的强制清理回收内存的暴力解决方式。
根据MOS建议,通过设置如下参数来避免文本中的问题。
Sysctl –w vm.min_free_kbytes=1024000
Sysctl –w vm.vfs_cache_pressure=200
Sysctl –w vm.swappiness=40
Min_free_kbytes 表示操作系统至少保留的空闲物理内存大小,单位是KB。Vfs_cache_pressure 参数用来控制操作系统对内存的回收,默认值为100,通过增加该值大小,可以加快系统对文件系统cache的回收
Vm.swappiness则是控制swap交换产生的趋势程度,默认值为100,通过将该值调的更低些,可以降低物理内存和disk之间产生交换的概率。但是REDHAT官方白皮书明确提出,不建议将该值设置为10或更低的值。
应用SQL突然变慢优化分析
根据v$session.program定位到业务程序,并结合event,SQL_ID和SQL_TEXT确认较慢的SQL。
Dbms_stats 可以将表的统计信息还原到过去某个时间点
Exec dbms_stats.restore_table_stats(ownname=>’’,tabname=>’’,as_of_timestamp=>’01-dec-15 12.09.22.020077 AM +08:00’);Select owner,table_name,column_name,num_distinct,density,num_buckets,last_analyzed,histogram from dba_tab_col_statistics where table_name=’’;复制
基于列的统计信息。
Select instance_number,snap_id,stat_name,value from dba_hist_osstat;复制
value 为累计数据,前后相减。
Vm_out_bytes 换出的内存
上面的语句查询ORACLE检查到的换页操作。
S
elect instance_number,snap_id,sum(sharable_mem)/1024/1024 from dba_hist_sqlstatWhere snap_id>13550 and snap_id<13558< span="">Group by instance_number,snap_id order by 1,2;复制
检查是否有非常大的SQL操作
子游标过多解决方法
1.升级到11.2.0.4版本
2.设置隐含参数
Alter system set “_cursor_features_enabled”=300 scope=spfile;Alter system set event=’106001 trace name context forever,level 1024’ scope=spfile;复制
正常重启数据库即可。
建议大多数11g核心系统关闭新特性ACS和基数反馈feedback
Alter system set “_optimizer_use_feedback”=false scope=both;Alter system set “_optimizer_adaptive_cursor_sharing”=false scope=both;复制
只失效特定执行计划异常的子游标(11G)
Select address,hash_value from v$sqlarea where sql_id=’’;Exec dbms_shared_pool.purge(‘address,hash_value’,’C’);复制
将整个INDEX缓存到内存中,
Alter index bill.test storage (buffer_pool keep);
Ora-04030 故障处理
1.是否有足够的可用内存
2.是否设置了ORACLE的限制
Show parameter pgaSelect * from v$pgastat;Select x.ksppinm name,y.ksppstvl value,x.ksppdesc describeFrom sys.x$ksppi x,sys.x$ksppcv yWhere x.indx=y.indxAnd x.skppinm like ‘%_pga_max_size%’;复制
%_smm_max_size%复制
3.哪个进程需要的内存过多
4.是否设置了操作系统限制
Ulimit –aSelect * from v$mystat where rownum<2;< span="">Select spid from v$process where addr=(select paddr from v$session where sid=);复制
$dbx –a spid 通过DBX工具查看该进程的LIMIT信息。
SQL执行次数
Select *From (select begin_interval_time,a.instance_number,plan_hash_value,executions_delta exec,,round(buffer_gets_delta/executions_delta)per_get,round(rows_processed_delta/executions_delta,1)per_rows,round(dlapsed_time_delta/executions_delta/1000000,2)time_s,round(disk_reads_delta/executions_delta,2)per_readfrom dba_hist_sqlstat a,dba_hist_snapshot bwhere a.snap_id=b.snap_idand executions_delta<>0and a.instance_number=b.instance_numberand a.sql_id=’’order by 1 desc)where rownum<30;< span="">复制
通过/*+gather_plan_statistics*/ 查看优化器的估计值与真实值之间的差异。
这个提示会记录每一步操作中真实返回的行数A-ROWS,BUFFERS,A-TIME
Connect by 的使用
select empno,
lpad(‘ ‘,level*2-1,’ ‘)|| ename ename,
job,
mgr,
deptno,
level
from emp
start with mgr is null (mgr is null 总裁岗位没领导)
connect by prior empno=mgr
order siblings by emp.ename;(在层次查询结果内对具有同一上级元素的同级元素进行排序)
辅助EXP数据导出
select max(sys_connect_by_path(table_name,',')) tablelist from(select table_name,ceil(sum(num_rows)over(order by table_name asc)/20000000) s,rank()over(order by table_name asc) rk from user_tables)connect by rk=prior rk-1 and s= prior sgroup by s;复制
要求是若几张表的记录数之和超过2000万,则这几张表就作为一组表来导出
实际导出时还需要考虑表之间的关联性等问题,通常会将有主外键关联的表一起导出,但若表较大,则还是要分别导出,但导入时一定要注意顺序
案例分析:buffer busy waits,log file switch (checkpoint incomplete)
1.确定buffer busy waits 产生的原因
SQL>select sql_id,count(*) from dba_hist_active_sess_history where sample_time>to_date('20200720 10','yyyymmdd hh24')And sample_time<to_date('20200720 11','yyyymmdd hh24')And wait_class<>'Idle'And event='buffer busy waits'Group by sql_id;Select sql_id,sql_exec_id,blocking_sessionFrom dba_hist_active_sess_history where sample_time>to_date('20200720 10','yyyymmdd hh24')And sample_time<to_date('20200720 11','yyyymmdd hh24')And wait_class<>'Idle'And event='buffer busy waits';Select event,count(*) from dba_hist_active_sess_historyWhere session_id in ()And sample_time>to_date('20200720 10','yyyymmdd hh24')And sample_time<to_date('20200720 11','yyyymmdd hh24')Group by event order by 2;复制
2.确定log file switch(checkpoint incomplete)产生的原因
Select group#,bytes/1024/1024,status from v$log;
3.继续检查redo log的切换频率
Select b.sequence#,b.first_time,a.sequence#,a.first_time,Round(((a.first_time-b.first_time)*24)*60,2)From v$log_history a,v$log_history bWhere a.sequence#=b.sequence#+1And a.first_time>to_date(‘20200720 10:00’,’yyyymmdd hh24:mi’)And a.first_time<to_date(‘20200720 11:00’,’yyyymmdd hh24:mi’)Order by a.sequence#;复制
(11g适用,12C该视图没有时间,只有日期)
4.查看与DBWR进程相关的等待事件
Select to_char(sample_time,’yyyymmdd hh24:mi:ss’),seq#,event,time_waited,p1,p2,p3 fromDba_hist_active_sess_historyWhere sample_time>to_date(‘20200624 10’,’yyyymmdd hh24’)And sample_time<to_date(‘20200624 11:00’,’yyyymmdd hh24:mi’)And program like ‘%DBW%’And snap_id>=6069 and snap_id<=6070< span="">And dbid=…Order by 1;复制

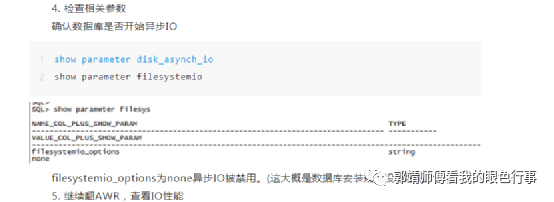
5.检查相关参数
确认数据库是否开始异步IO
Show parameter disk_asynch_io
Show parameter filesystemio_options
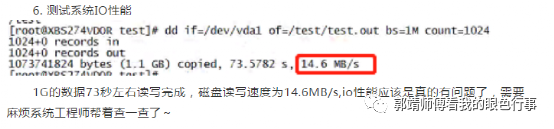
6.测试系统IO性能
#dd if=/dev/vda1 of=/test/test.out bs=1M count=1024
https://mp.weixin.qq.com/s/JdrHjebk4Qtg6781r2IqhA
某客户反馈,某系统10点多突然变慢,很多在线业务被阻塞。
一.分析过程
1.查看活动会话最高的时间段
Select sample_id,to_char(sample_time,’yyyy-mm-dd hh24:mi:ss’),count(*) from dba_hist_active_sess_historyWhere instance_number=1 and sample_time between to_date(‘2020-07-16 06:30’,’yyyy-mm-dd hh24:mi’) and to_date(‘2020-07-16 10:05’,’yyyy-mm-dd hh24:mi’)Group by sample_id,to_char(sample_time,’yyyy-mm-dd hh24:mi:ss’)Order by sample_id;复制
2.查看单次等待耗时最长的等待事件
Select program,machine,session_id,session_serial#,event,blocking_session,count(*) from dba_hist_active_sess_historyWhere instance_number=1 and sample_time between to_date(‘2020-07-16 09:58’,’yyyy-mm-dd hh24:mi’) and to_date(‘2020-07-16 10:01’,’yyyy-mm-dd hh24:mi’)Group by program,machine,session_id,session_serial#,event,blocking_sessionOrder by count(*);复制
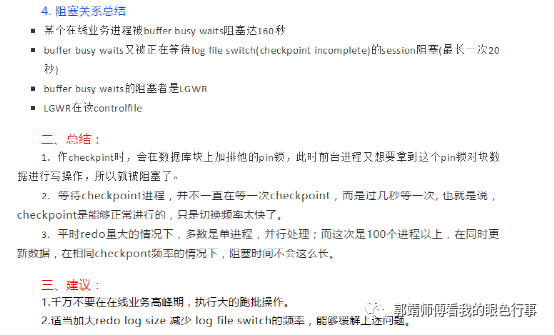
3.查看blocking session的等待事件
4.
等待事件













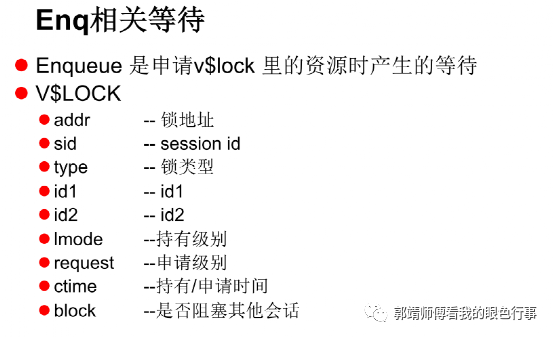
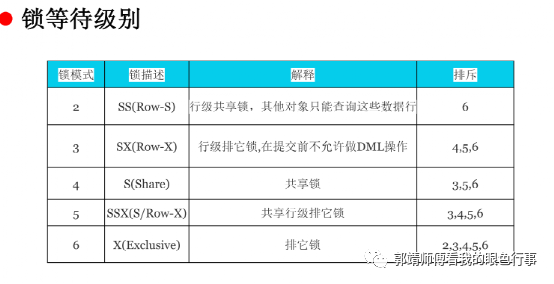















oracle批量操作模板
CREATE OR REPLACE PROCEDURE MOVE_TB_SMS ASBEGINDECLARECURSOR C1 ISSELECT ROWID ROW_ID FROM TB_SMS WHERE CADDDATE < trunc(sysdate - 10); --找出你需要操作的表的rowidC_COMMIT CONSTANT PLS_INTEGER := 30000; --代表提交的行数BEGINFOR C1REC IN C1 LOOPINSERT INTO tb_sms_history(ICONTENTTYPE,CSERVICE)SELECT ICONTENTTYPE,CSERVICEFROM TB_SMSWHERE ROWID = C1REC.ROW_ID; --主要记录rowid两边保持一致,此处以insert为例--DELETE FROM TB_SMS WHERE ROWID = C1REC.ROW_ID;IF (MOD(C1%ROWCOUNT, C_COMMIT) = 0) THENCOMMIT;DBMS_LOCK.SLEEP(60); --这个权限可能需要单独授权,请注意END IF;END LOOP;COMMIT;END;END;/复制
https://blog.csdn.net/u012556249/java/article/details/107513729
如何在五分钟内快速反馈Oracle数据库问题
1.先看系统资源使用情况
Vmstat 2 5
2.检查日志有没有错误
单机系统,先检查alert日志,如果里面有错误,再看相应的trace日志。
3.查等待事件
Select event,count(*) from v$session where status=’ACTIVE’ group by event order by 2;

Select machine,count(*) from v$session where event like ‘read by %’ group by machine order by 2;Select sql_id,count(*) from v$session where event like ‘read by %’ group by sql_id order by 2;复制
我们看到所有这些连接也并非都是同一个SQL_ID执行的。
不过别急,进一步把一个个SQL ID解析成SQL语句后,我们发现,这800多个等待“read by other session”的会话,其实是2个语句:
它们的共同点是都对其中一个表进行查询。
通过执行awrsqrpt.sql语句来进一步分析单个sql_id,我们发现,执行频率很高:
相对于近亿条记录的表关联查询来说,每次执行所消耗的IO,是正常的。
表和索引的统计信息都是一天前刚搜集的。实际记录数与统计信息搜集的相比,差异在1%以内,SQL的执行计划没有发生变化。
因此,猴儿反馈给师父,数据库本身没有问题。
某业务执行频率异常导致业务慢(从sqlrpt的信息来看,执行一个查询要耗时3分多钟),CPU利用率比平时高10个点左右。
执行频率有多高呢,1小时执行了上百万次。这个业务正常一小时执行上万次就了不起了
1、 read by other session等待事件
§这个等待事件是从buffer busy wait这个等待事件剥离出来的。
§什么情况会发生这个等待事件呢?
(1)某个会话正在查询某个表的数据,把这些数据从磁盘里读到高速缓存区中,而其他会话这时如果也在请求相同的数据块。如果响应的数据块还没完全读到缓存中,就会发生这样这个等待事件。
(2)因为有会话正在读取数据在内存,因此该事件同时会伴随着sequential read或者是scattered read,一般情况不会孤立存在。
§通常怎么做?
(1)由应用侧停止发起异常连接数的业务可能是最好的方式,但不一定能做到。
(2)在应用侧的授权下,kill掉相应会话是可选的方式。
2、 单机数据库,如果这些查完都没有问题怎么办?
上述检查中,关于主机方面,主要看了CPU、内存使用情况。因此,还可以检查磁盘IO信息(iostat,sar –d等),还可以看看网络怎么样(top/topas,netstat等)。以及操作系统方面的日志信息。
3、如果是Oracle RAC数据库呢?
检查多个实例的情况
同时应该看看CRS的日志
检查ASM的情况,ASM默认的参数偏小
4、这个case中,有没有可能是SQL本身的问题?
如果不是因为有SQL基线,确定SQL执行计划没变,正常应该确定SQL是否有优化余地。
做一线运维,尽可能去做好所负责的数据库基线管理,并定期更新。这非常有助于快速分析和定位问题。
Oracle常见故障--Listener类:Hang、Crash及连接风暴的判断
目录
监听状态正常,应用反馈时断时连
Listener进程crash
ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务
11G SCAN LISTENER无法注册服务故障
Listener hang
TNS-12535 TNS-00505处理
应用测试连接不上数据库,连接直接报TNS-12547: TNS:lost contact处理
由Oracle的Listener引起的报错很多,很大一部分是由于配置不当导致的。通常,我们要么从tnsnames.ora找原因,要么从lisntener.ora找原因。基本上,我们从Oracle连接的时候报出的错误代码可以快速查到原因。
下面介绍的几类故障及处理方法,难度稍微要大一些
1监听状态正常,应用反馈时断时连
故障现象:
客户端新发起的短连接时断时连,如下所示:
故障原因:
因短连接持续性发起连接耗尽监听ip 1521端口资源,导致监听无法正常处理连接请求。
超过每秒50次连接则需要关注,可通过tail -20f listener.log 观察,如持续性快速刷屏则可能已经出现连接风暴.
故障解决/日志分析: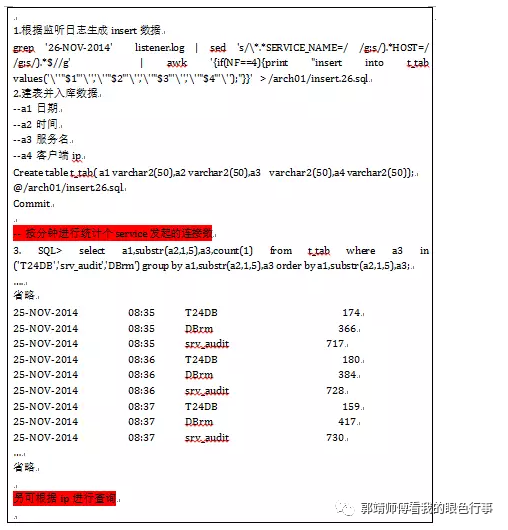
2Listener进程crash
故障环境:
操作系统为:SunOS 5.10
数据库版本:Oracle 10.2.0.4
故障现象:
Listener进程已经crash, 查看主机数据库监听日志listener_ngsetdb3/4.log如下:
系统日志:
故障分析
Listener进程crash是由于IPMP出现故障所致,Listener随后在探测不到服务节点时,直接crash。Oracle MOS文章Solaris Cluster 3.x: IPMP group failure impact [ID 1006916.1]对此有详细描述:在Sun Cluster中,短暂的网络故障会导致IPMP组失败,并触发资源组切换。并且,它会在38秒后回切!
处理方法:
查看监听日志listener.log跟系统日志(/var/adm/ messages)。
手动重启两个节点的Listener,Oracle提供了一个解决方案:修改/etc/default/mpathd文件下的IPMP FAILURE_DETECTION_TIME变量值,即将失败检测时间从默认的10秒(10000)增加到20秒(20000)以上
注:修改该参数需要重启mpathd服务。
3ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务
故障现象:
客户端无法通过监听连接数据库
故障原因:
1.实例未注册到listener中,可通过lsnrctl status 查看
2.oracle process达到上限无法建立新的连接。
故障解决:
1.手工注册数据库,alter system register;
2.检查数据库用户连接分布情况,并show process 查看连接限制
Select username,count(1) from v$session group by username order by 2 asc;
Ps :大部分情况由开发商程序bug引起。
411G SCAN LISTENER无法注册服务故障
故障现象:
scan listener 无法注册service服务
故障原因:
bug 13066936
故障解决:
5Listener hang
故障环境:
任意环境
故障现象:
从其他应用主机tnsping发现延迟很大
查看监听状态报如下错:
listener.log有如下报错:
故障分析:
Too many open files意味着Maximum Number Of Open Files Per Process 达到了上限。因此listener hang住的原因是该limit设置过小。
处理方法:
将oracle用户的soft limit提升为至少1024,然后重新oracle用户登录,检验ulimit合格后,重新启动数据库和监听。
具体解决办法如下:
1.在/etc/system增加以下行
set rlim_fd_max=65536
set rlim_fd_cur=4096
2.重新登录ORACLE并检验oracle用户的限制
su – oracle
ulimit -Ha
ulimit –Sa
3.重新启动数据库和监听
6TNS-12535 TNS-00505处理
故障环境:
任意环境
故障现象:
Db alert日志报如下错误:
故障分析:
一个客户端连接整个步骤:
1.客户端发起一个connection连接监听
2.监听启动一个专属进程(服务器进程,也就是我们通常说的LOCA=NO进程)用于接收这个connection
3.在专属进程启动之后,监听会将这个connection传递给这个专属进程
4.专属进程通过这个connection来跟客户端握手
5.专属进程跟客户端信息交换需要建立一个session
6.session打开
当在以上的第3步到第4步时客户端关闭,所以当专属进程尝试跟客户端联系时发现连接已关闭时,就会报出我们看到的错误!!
错误一般是由于程序异常断开导致超时,11g R1如果出现如上的错误信息会写入到sqlnet.log,11g R2会写入到alert.log,
其实出现此错误是正常的现象。
处理方法
如果不想这样的信息打印在alert日志中,
在sqlnet.ora设置
DIAG_ADR_ENABLED = OFF
在listener.ora设置
DIAG_ADR_ENABLED_
重启监听
7应用测试连接不上数据库,连接直接报TNS-12547: TNS:lost contact处理
故障环境:
环境:HP-UX 11.31 ia64
数据库版本:11.2.0.4
故障现象:
应用测试连接不上数据库,连接直接报TNS-12547: TNS:lost contact。
但查看监听状态,CRS状态,数据库状态均正常。CRS日志、CSS日志及AGENT日志均无报错。
故障分析:
1.应用连接数据库直接报TNS-12547: TNS:lost contact
2.监听日志发现一直在报连接失败:
问题导致的原因有在32位平台中当listener.log超过2G会报这个错。
ORACLE_HOME下的一些执行文件权限不对也会导致相同的错误,但我们这个是64位的,排除第一种,
所以去查询执行文件的权限是否正常。
处理方法:
1、 通过对比发现部分执行文件少了S权限,做了relink all,重新同步执行文件
2、 由于数据库使用的是ASM,磁盘属组为asmadmin,故对比问题节点及正常节点DB ORACLE_HOME下属组为asmadmin的文件,将问题节点文件权限修正即可解决问题。
快速获取ORACLE_HOME
1.ORACLE_HOME环境变量
2.More /etc/oratab
3.Ps –ef|grep tns
4.Ps –ef|grep pmon
Pmap 40923|grep dat
PGA
1.私有SQL区域-----存储SERVER PROCESS执行SQL所需要的私有数据和控制结构,包含固定区域和运行时区域
2.会话空间--------存放LOGON信息等会话相关的控制信息
3.SQL工作区--------排序操作;为实现自动PGA管理,引入了初始化参数PGA_AGGREGATE_TARGET WORKAREA_SIZE_POLICY
查看排序操作PGA的使用情况
1.查看用户的会话信息
Select c.sid,spid,pid,a.serial# from (select sid from v$mystat where rownum<=1) c,v$session a,v$process b
Where c.sid=a.sid and a.paddr=b.addr;
2.查看PGA内存的使用
Select pag_max_mem/1024,pga_alloc_mem/1024,pga_used_mem/1024,program from v$process where spid=3480 order by pga_used_mem,pga_max_mem;
Select count(*) from v$open_cursor where sid=44;
PGA自动管理
参数:
Pga_aggregate_target
1.该参数用来控制instance使用PGA内存总量。
2.不是硬性限制,而算是一个请求
3.11G,内存自动管理AMM(memory_target,memory_max_target)
Workarea_size_policy auto
PGA监控
1.查看进程使用PGA信息
Select program,spid,pga_used_mem/1024 PGA_USED,PGA_ALLOC_MEM/1024 PGA_ALLOC,PGA_FREEABLE_MEM/1024 PGA_FREE,PGA_MAX_MEM/1024 PGA_MAX
FROM V$PROCESS ORDER BY PGA_USED;
2.查看session UGA信息
Select * from v$sysstat where name like ‘session%ga%’;
3.查看PGA状态信息
Select * from v$pgastat;
PGA故障
ORA-4030错误的可能原因
1.PGA设置过大,导致物理内存耗尽
2.操作系统内存限制设置不合理
3.程序中分配内存部分出现死循环
4.分配对象后没有释放
需要排序的操作
1.创建索引
2.Parallel insert operations involving index maintenance
3.ORDER BY OR GROUP BY
4.DISTINCT
5.UNION,INTERSECT OR MINUS
6.SORT-MERGE JOINS
7.ANALYZE
查看排序区使用
案例
1.查看临时表空间临时段的使用
Select tablespace_name,segment_block,used_blocks,free_blocks,current_users,total_blocks from v$sort_segment;
2.查看instance排序分布
Select low_optimal_size/1024/1024 low_mb,(high_optimal_size+1)/1024/1024 high_mb,
Optimal_executions,onepass_executions,multipasses_executions from v$sql_workarea_histogram
Where total_executions!=0 and (low_optimal_size/1024/1024>=8 or total_executions>optimal_executions);
3.查看临时表空间应用事件
Select b.sid,a.name,b.value from v$statname a,v$sesstat b
Where a.statistic#=b.statistic# and a.name like ‘%direct%’ and sid=21;
数据库生成的临时数据包括:
1.位图合并
2.散列联接
3.位图索引创建
4.分类
5.临时LOB
6.全局临时表
优化:
1.建立多个临时表空间,将临时表空间的tempfile存储到不同的磁盘上
2.将临时表空间加入到临时表空间组
3.设定临时表空间组为数据库默认的临时表空间
案例:调整PGA优化排序
1)查看PGA配置
Show parameter pga
Select * from v$pgastat;
2)查看临时段的使用
Select tablespace_name,segment_block,used_blocks,free_blocks,current_users,total_blocks from v$sort_segment;
查看排序 应用:
Select low_optimal_size/1024/1024 low_mb,(high_optimal_size+1)/1024/1024 high_mb,
Optimal_executions,onepass_executions,multipasses_executions from v$sql_workarea_histogram
Where total_executions!=0 and (low_optimal_size/1024/1024>=8 or total_executions>optimal_exections);

3)调整PGA SIZE
Alter system set pag_aggregate_target=500m scope=spfile;
等待事件
1.direct path read
意味着磁盘上有大量的临时数据产生,比如排序,并行执行等操作或PGA中空闲空间不足。
2.direct path write
是会话将一些数据从PGA中直接写入到磁盘文件上,而不经过SGA
1.使用临时表空间 排序(内存不足)
2.数据的直接加载(使用append方式加载数据)
3.并行DML操作
RAC管理
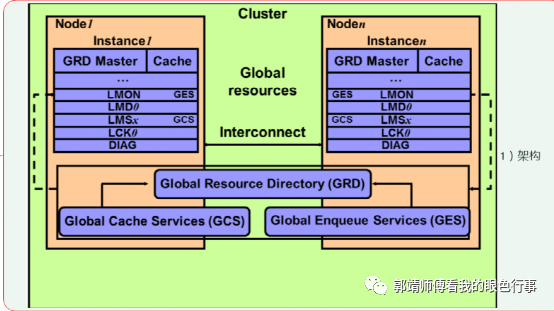
缓存融合(cache fusion)
Lmon 负责节点之间的通信,监控各个节点的健康状态
Lmd0 负责多个实例间对数据块的访问顺序,保证数据访问的一致性
Lms0负责数据块在实例间的传递
Lck0
网络管理
查看集群网络配置
#oifcfg iflist –p –n
#oifcfg getif
修改IP
1.禁用并停止数据库
#srvctl disable database –d prod
Srvctl stop database –d prod –o immediate
2.禁用并停止local listener
#srvctl disable listener
#srvctl stop listener
3.禁用并停止VIP
#srvctl disable vip –i node1 –vip
#srvctl disable vip –i node2 –vip
#srvctl stop vip –n node1
#srvctl stop vip –n node2
4.禁用并停止scan listener 及scan
#srvctl disable scan_listener
#srvctl stop scan_listener
#srvctl disable scan
#srvctl stop scan
5.在所有node停止CRS服务
#crsctl stop crs –f
#crsctl stop crs -f
6.在操作系统下修改IP
7.启动CRS服务
#crsctl start crs
#crsctl check crs
8.通过OIFCFG修改集群网络配置
#oifcfg getif
#oifcfg delif –global eth1
#oifcfg delif –global eth2
#oifcfg delif –global eth3
注意:对于私有网络做了HAIP后,多网卡中,最少保留一个网卡配置,不能被删除
按照修改后的IP网段配置网络:
#oifcfg setif –global eth2/10.10.10.0:cluster_interconnect
#oifcfg setif –global eth1/192.168.8.0:public
9.配置VIP及SCAN
#srvctl modify nodeapps –n node1 –A 192.168.8.23/255.255.255.0/eth1
#srvctl modify nodeapps –n node2 –A 192.168.8.24/255.255.255.0/eth1
#srvctl config vip –n node1
#srvctl config vip –n node2
#srvctl config scan
#srvctl modify scan –n cluster01(/etc/hosts 配置的主机名)
10.重新启用及启动相关服务
#srvctl enable scan
Srvctl start scan
Srvctl enable scan_listener
Srvctl start scan_listener
Srvctl enable vip –I node1 –vip
Srvctl start vip –n node1
Srvctl enable vip –i node2 –vip
Srvctl start vip –n node2
Srvctl enable listener
Srvctl start listener
Srvctl enable database –d prod
Srvctl start database –d prod
备份恢复
1.热备 在RAC中任何一个NODE上进行备份(归档)
RMAN>backup incremental level 0 database format ‘/backup/prod/%U’;
1.冷备 关闭整个database,然后将一个instance启动到mount下进行备份。
案例:在归档数据库做数据库的完全恢复
删除用户表空间数据文件
Select file#,error from v$recover_file;
通过RMAN恢复
Rman target
Rman>run {
Sql ‘alter database datafile 4 offline’;
Alter database open;
Restore datafile 4;
Recover datafile 4;
Sql ‘alter database datafile 4 online’;
}
闪回恢复
基于时间点的闪回查询:
Select * from emp1 as of timestamp to_timestamp(‘2018-01-05 10:30:15’,’yyyy-mm-dd hh24:mi:ss’);
Insert into emp1 (select * from emp1 as of timestamp to_timestamp(‘2018-01-05 10:20:15’,’yyyy-mm-dd hh24:mi:ss’));
案例:在RAC下用户误操作,做基于数据库的不完全恢复
1.用户误操作 truncate table emp
2.关闭数据库
Srvctl stop database –d prod –o immediate
3.建立基于时间点的不完全恢复
Rman>run {
Startup mount;
Sql ‘alter session set nls_date_format=”yyyy-mm-dd hh24:mi:ss”’;
Set until time ‘2018-01-05 10:36:17’;
Restore database;
Recover database;
Alter database open resetlogs;
}
添加新节点
1.环境准备 建立和其他节点一致的新节点,操作系统,参数,硬件
跳过环境检测:
$export IGNORE_PREADDNODE_CHECKS=Y
添加新节点:
【grid@node2 bin】./addNode.sh “CLUSTER_NEW_NODES={node3}””CLUSTER_NEW_VIRTUAL_HOSTNAMES={node3-vip}”
在新节点上运行脚本
#/u01/app/oraInventory/orainstRoot.sh
#/u01/11.2.0/grid/root.sh
上面是添加GRID到新节点
添加ORACLE到新节点
[oracle@node2]$cd $ORACLE_HOME/oui/bin
./addNode.sh –silent “CLUSTER_NEW_NODES={node3}”
在新节点运行脚本
#/u01/app/oraInventory/orainstRoot.sh
#/u01/app/oracle/product/11.2.0/db_1/root.sh
添加新的INSTANCE
[oracle@node2 dbs]$dbca –silent –addInstance –nodeList node3 –gdbName prod1 –instanceName prod13 –sysDBAUserName sys –sysDBAPassword oracle
Oracle 12c rac 集群启动顺序
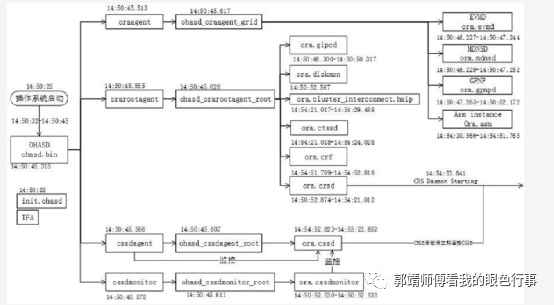
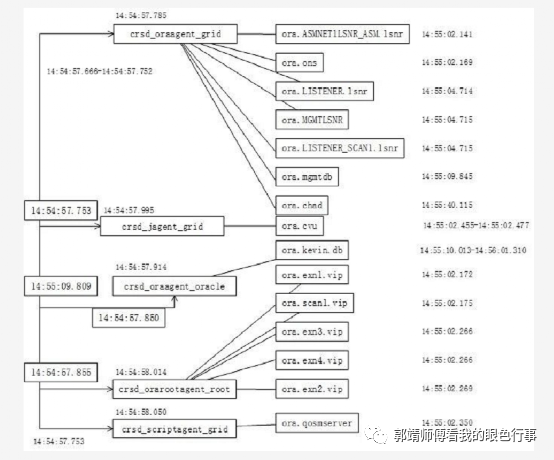
笔者阅读12C RAC单节点启动日志约89.6MB,耗时月余,大致了解了集群启动过程,上图仅展示各资源是谁调度启动的,以及启动时间记录。不包含启动过程中各资源间的通信调用,工作原理等
1.操作系统系统后,作为开机启动项,ohas及其守护进程被优先启动。
2.OHAS启动3个主代理
高可用grid代理:oraagent
高可用root代理:orarootagent
心跳代理:cssdagent
心跳监控:cssdmonitor
这三大代理分别启动操作系统层面grid和root用户分别控制的不同集群资源,以及root用户控制的集群心跳。
oraagent代理启动 ora.evmd ora.mdnsd ora.gpnpd ora.asm资源
orarootagent代理启动
ora.gipcd
ora.diskmon
ora.cluster_interconnect.haip
ora.ctssd
ora.crf
ora.crsd等
1.
cssdagent代理启动ora.cssd资源cssdmonitor启动ora.cssdmonitor资源
3. crsd启动5个子代理
crsd_oraagent_grid
crsd_oraagent_oracle
crsd_orarootagent_root
crsd_jagent_grid
crsd_scriptagent_grid
crsd_oraagent_grid代理负责启动 ora.mgmtdb ora.chad ora.listener_scan1.lsnr ora.mgmtlsnr ora.listener.lsnr ora.one ora.asmnet1lsnr_asm.lsnr 资源
crsd_oraagent_oracle代理负责启动ora.kevin.db资源
crsd_orarootagent_root代理启动vip资源
crsd_jagent_grid代理启动ora.cvu资源
crsd.scriptagent_grid代理启动ora.qosmserver资源
RAC环境下:ALTER SYSTEM SWITCH LOGFILE与ALTER SYSTEM ARCHIVE LOG CURRENT 区别
ALTER SYSTEM SWITCH LOGFILE:仅对当前节点进行日志切换并归档
ALTER SYSTEM ARCHIVE LOG CURRENT:对集群内所有节点实例进行切换并归档
也可对指定实例进行日志切换:alter system archive log instance ‘node2’ current;
触发检查点:alter system checkpoint;óalter system checkpoint global;
对当前实例触发:alter system checkpoint local;
RAC中如何删除归档日志
Run {
Delete noprompt archivelog high sequence 70 thread 1;
Delete noprompt archivelog high sequence 70 thread 2;
}
在删除归档日志的时候要加上thread,否则只会删除当前节点的,上条命令是删除实例1,2上所有小于70号的归档日志。
判断一个数据库是否是RAC
Show parameter cluster
